来源
课件地址:https://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/it300/download/ppt_all_in_one.zip
【110】看不懂你捶我,ProxySQL 实现MySQL读写分离的原理
来源:https://www.bilibili.com/video/BV1fU4y1o7rW?spm_id_from=333.999.0.0
正常的情况,MySql 集群,Java 应用直接操作主数据库
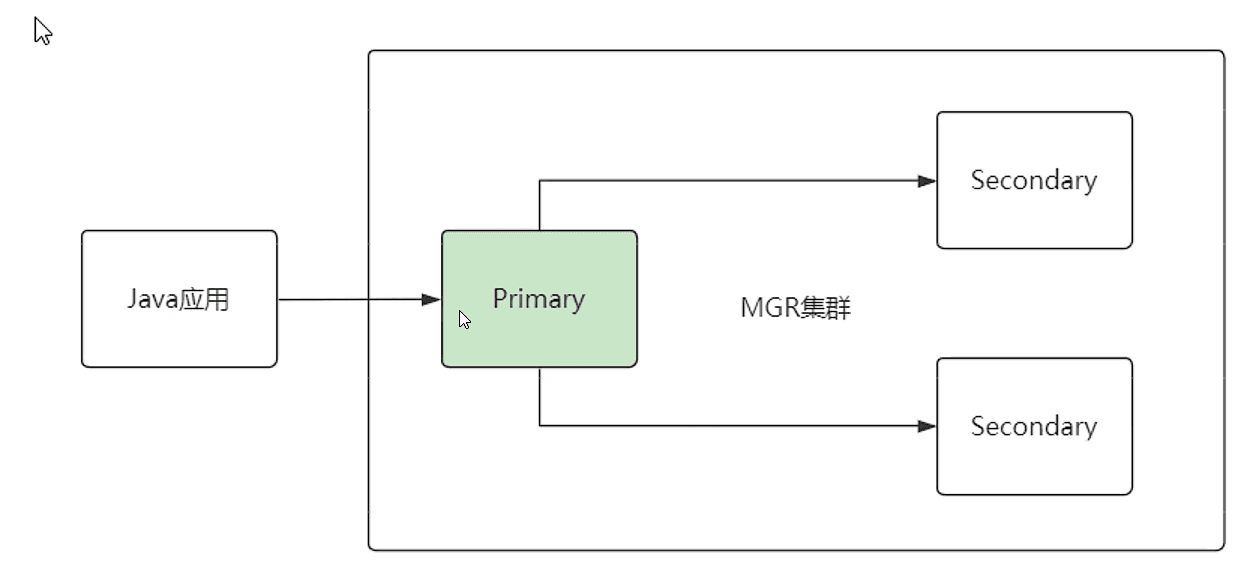
但是,如果主数据库挂掉了,主节点变更了,是不是抓瞎了
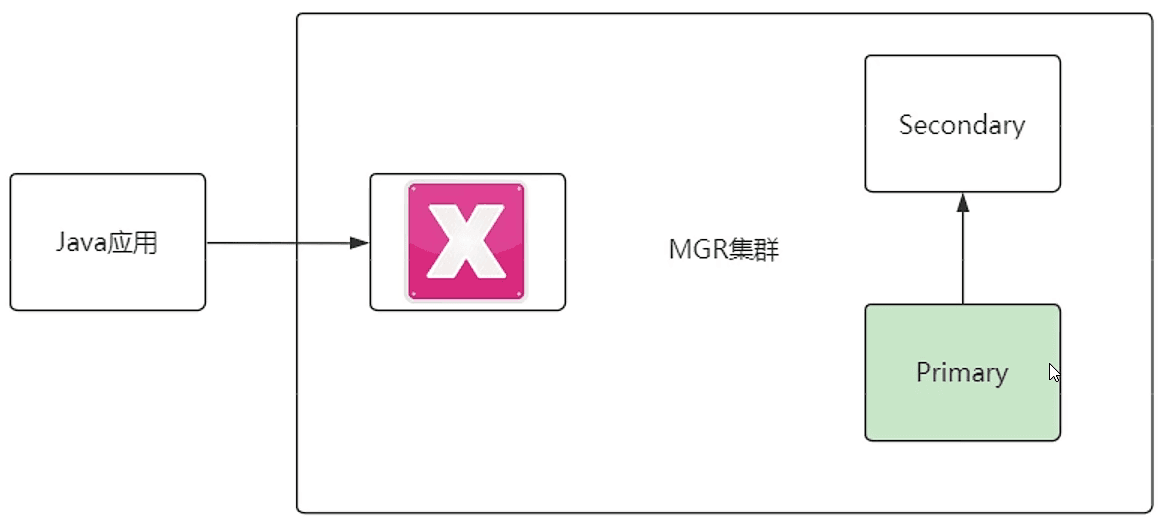
所以这个时候 ProxySQL 就出场了
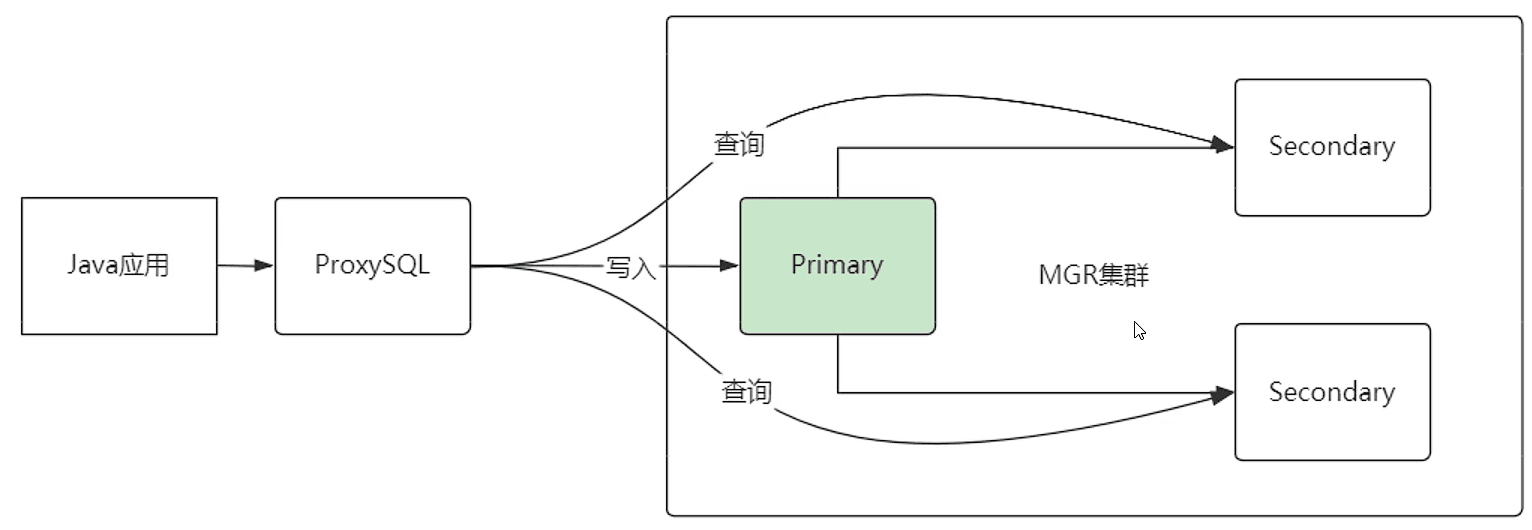
下面这种情况,即使主节点丢失,ProxySQL 也能找到新的主节点
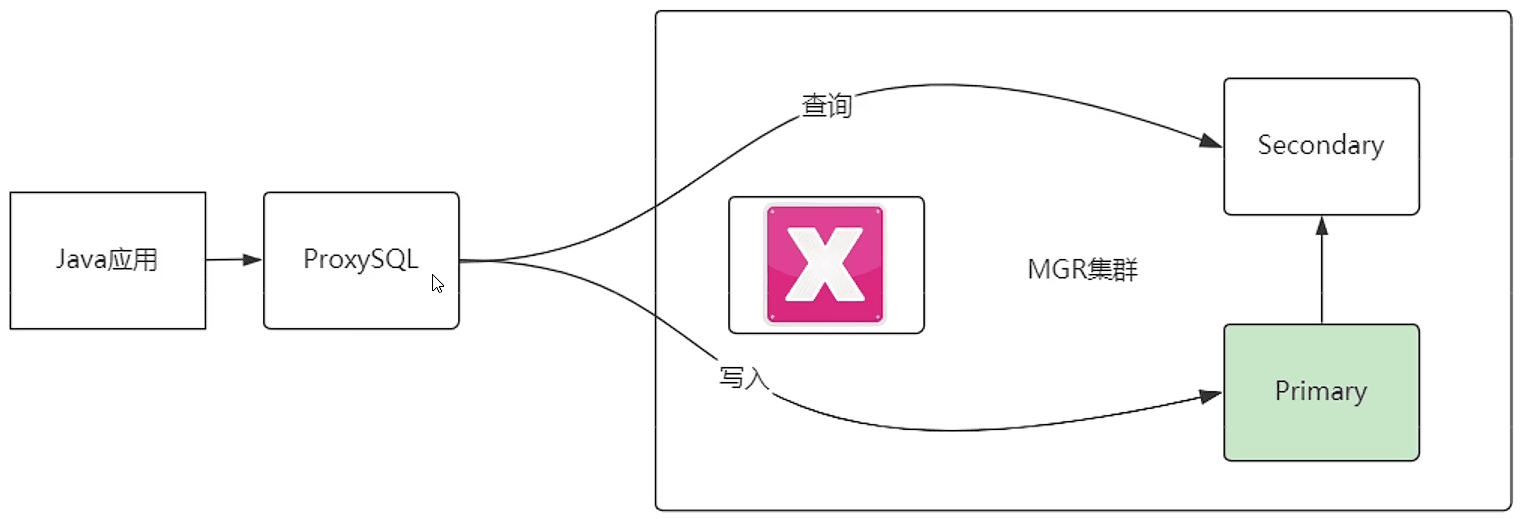
通过每个节点建立一个用户,轮询查询各个节点健康状态
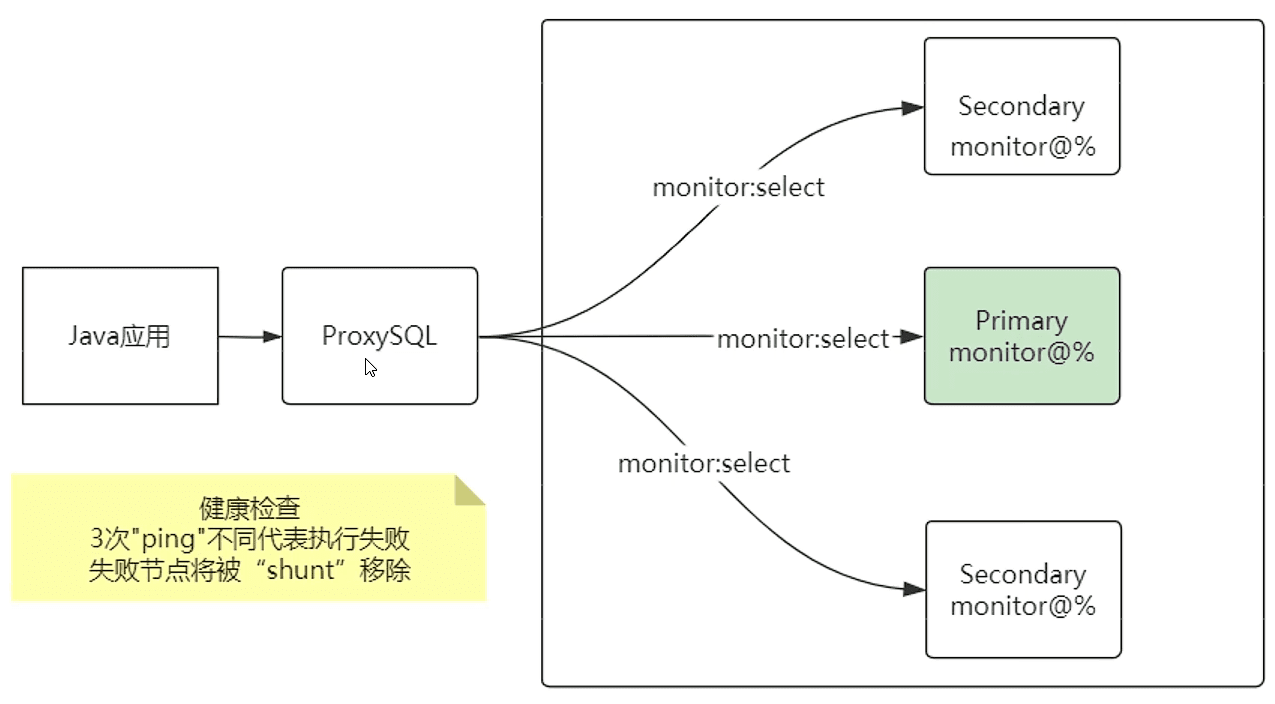
主节点如果发生变化了怎么办?
ProxySQL 的方案是在每个节点上创建一个视图 sys.gr_member_routing_candidate_status
目的是收集节点的运行状态,判断当前节点是主节点,还是从节点
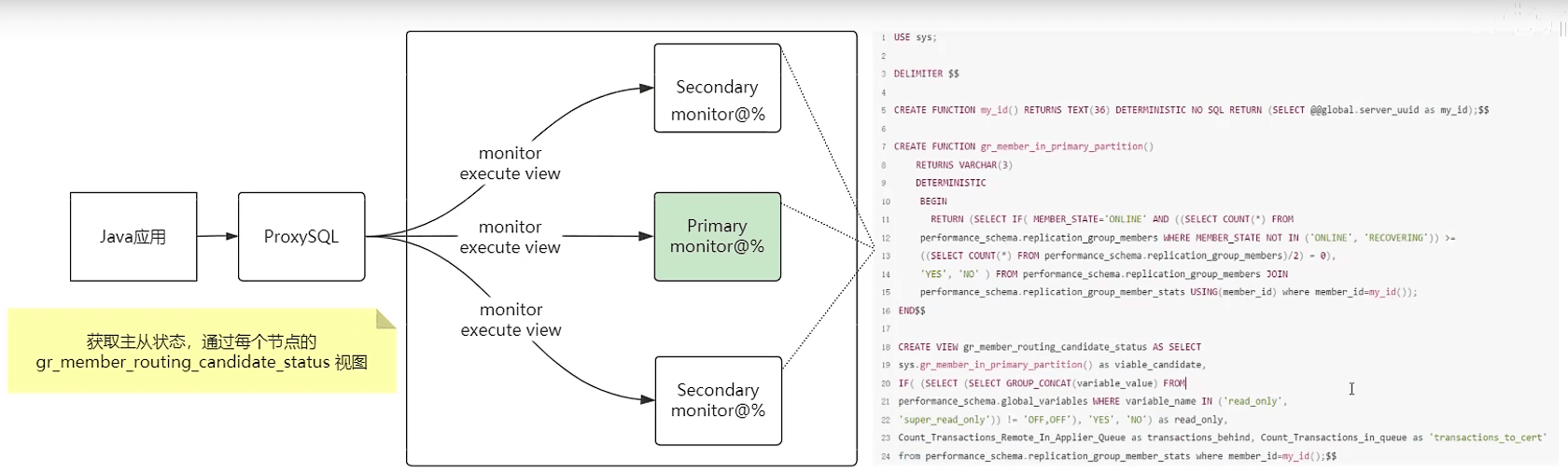
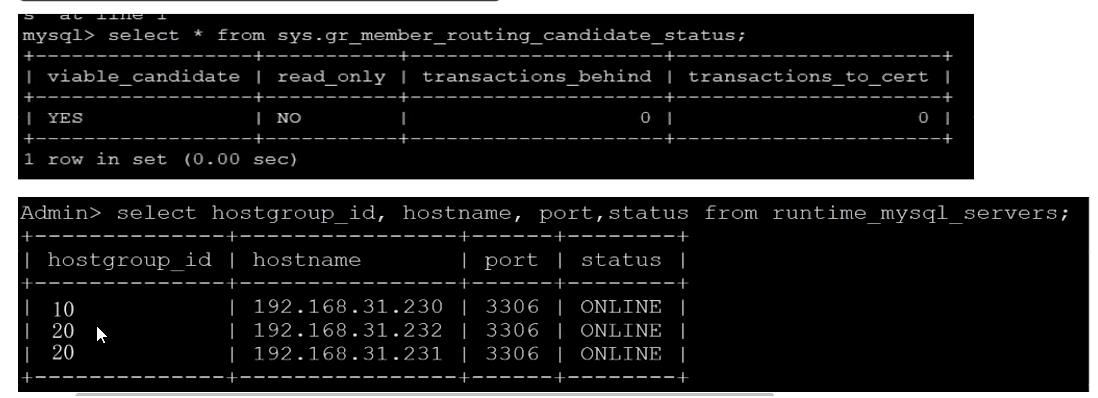
通过 read_only 字段判断是否主节点
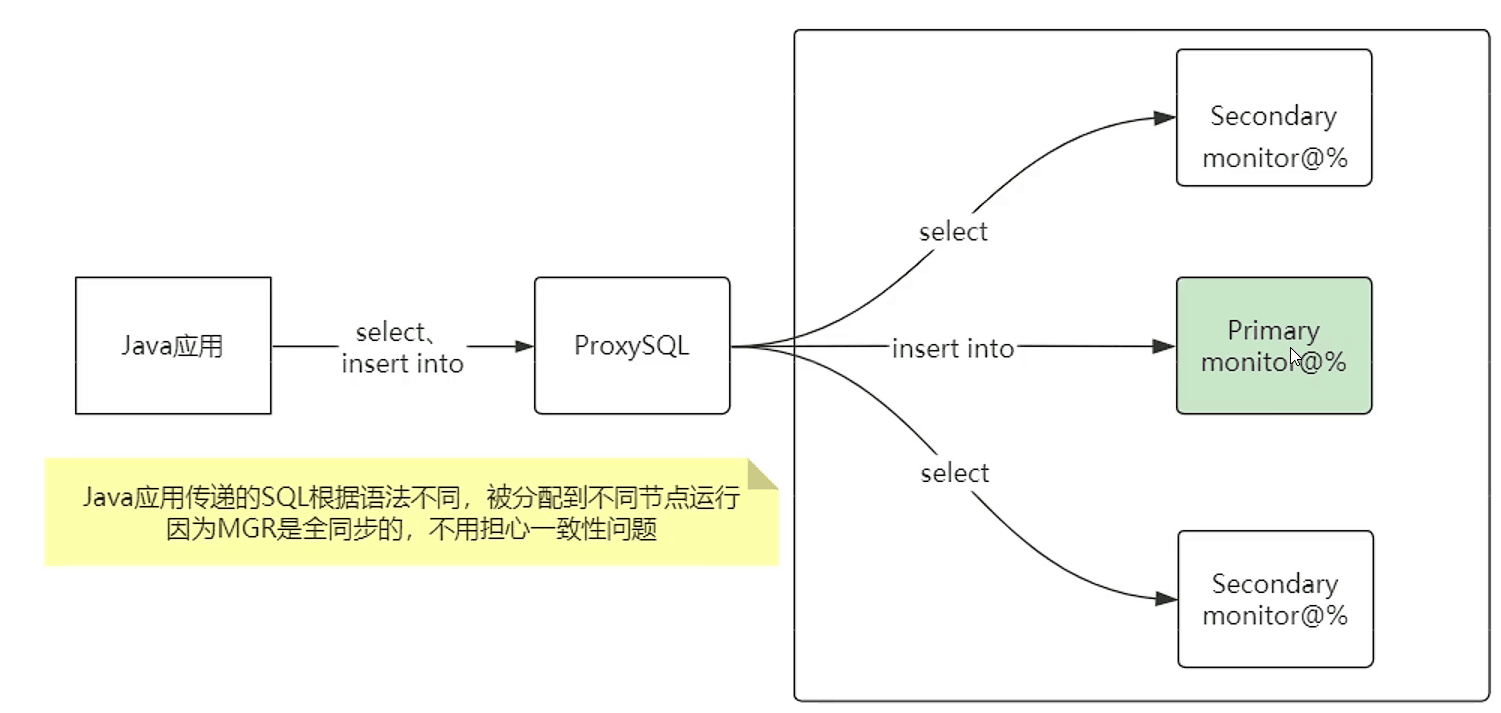
SQL 也通过 ProxySQL 分配到不同节点运行
【112】高频面试题,MySQL 读写分离后,先写后查如何保障一致性?
来源:https://www.bilibili.com/video/BV1PP4y137LM/?spm_id_from=333.788
常见读写分离架构
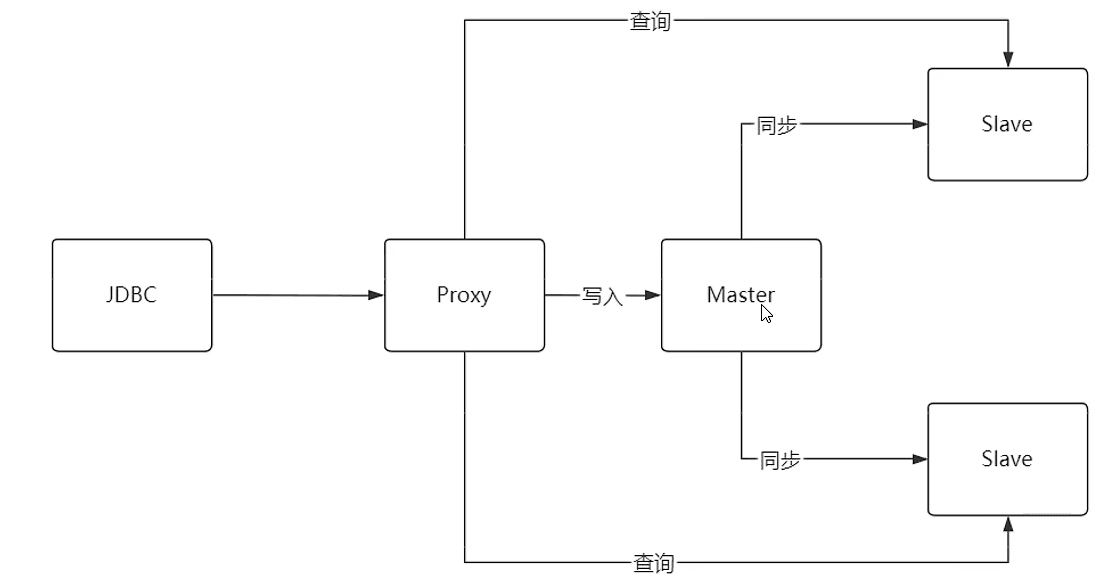
如果主,从之间数据同步有延迟怎么办?
//订单时间、自动编号、冗余字段等依赖数据表默认值自动生成
orderMapper.insert(order);===>走主库
//获取完整数据
Order order = orderMapper.findById(order.getOrderId());===>走从库
//这个时候数据还没有写入从库,这个数据不是最新的
//进行后续业务处理,如库存调拨,积分管理等
解决办法:
方案1:所有表记录必须自己设置,Order 对象保存所有字段数据
完全不依赖数据库机制,包括自增主键也是自己生成。
不推荐:真的有必要让程序员理解并设置所有字段数据吗?
Order 对象全量存储orderMapper.insert(order);===>走主库//进行后续业务处理,如库存调拨,积分管理等
方案2:延迟查询,为主从同步留出足够时间
不推荐:程序猿写代码时还得时刻脑补这个查询是否存在从库问题?
这个要求有点高啊!
你无法估计预留时间,长了浪费时间,短了不解决问题
//订单时间、自动编号、冗余字段等依赖数据表默认值自动生成orderMapper.insert(order);===>走主库Thread.s\eep(1000);Order order = orderMapper.findBy\d(order.getOrder\d());===>走从库//进行后续业务处理,如库存调拨,积分管理等
方案3:利用读写分离框架特性,如 ShardingJDBC 可以要求下一条 SELECT 强制走主库
推荐: ShardingJDBC 通过重写 DataSource 数据源方式实现读写分离,很少的代码修改便可以实现适配。
主库压力增大,可能出现性能瓶颈。
orderMapper.insert(order);===>走主库\\下一条 SQL 强制走主库HintManager.getInstance().setMasterRouteOnly();Order order = orderMapper.findById(order.getOrderId());===>走主库\\进行后续业务处理,如库存调拨,积分管理等
方案4:采用 MGR 全同步复制,强一致数据同步没完成主从同步之前,jdbc.insert() 方法无法得到结果
新项目推荐:无需改代码,真正的一致性方案
老项目不推荐,传统应用集群向 MGR 迁移成本高、风险大
orderMapper.insert(order);===>走主库Order order = orderMapper.findByld(order.getOrderld());===>走从库//进行后续业务处理,如库存调拨,积分管理等
【115】我为什么不建议利用 Docker 部署MySQL数据库
来源:https://www.bilibili.com/video/BV14R4y1F7bi/?spm_id_from=333.788
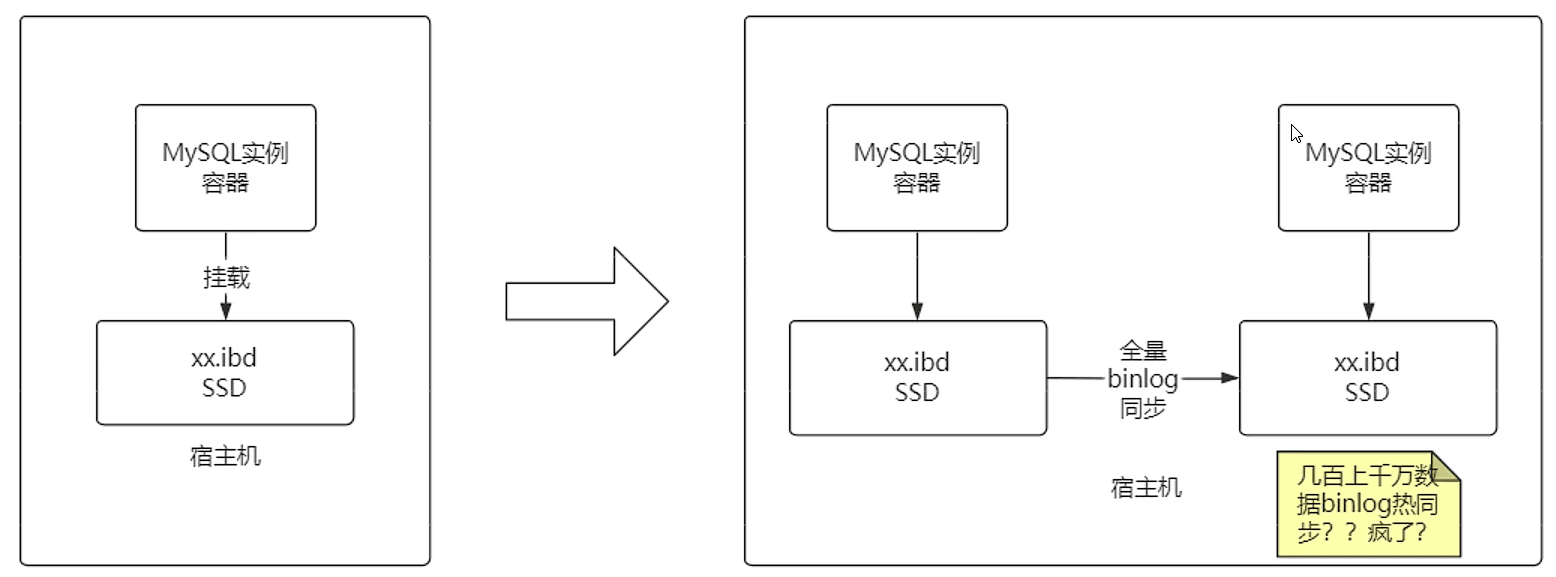
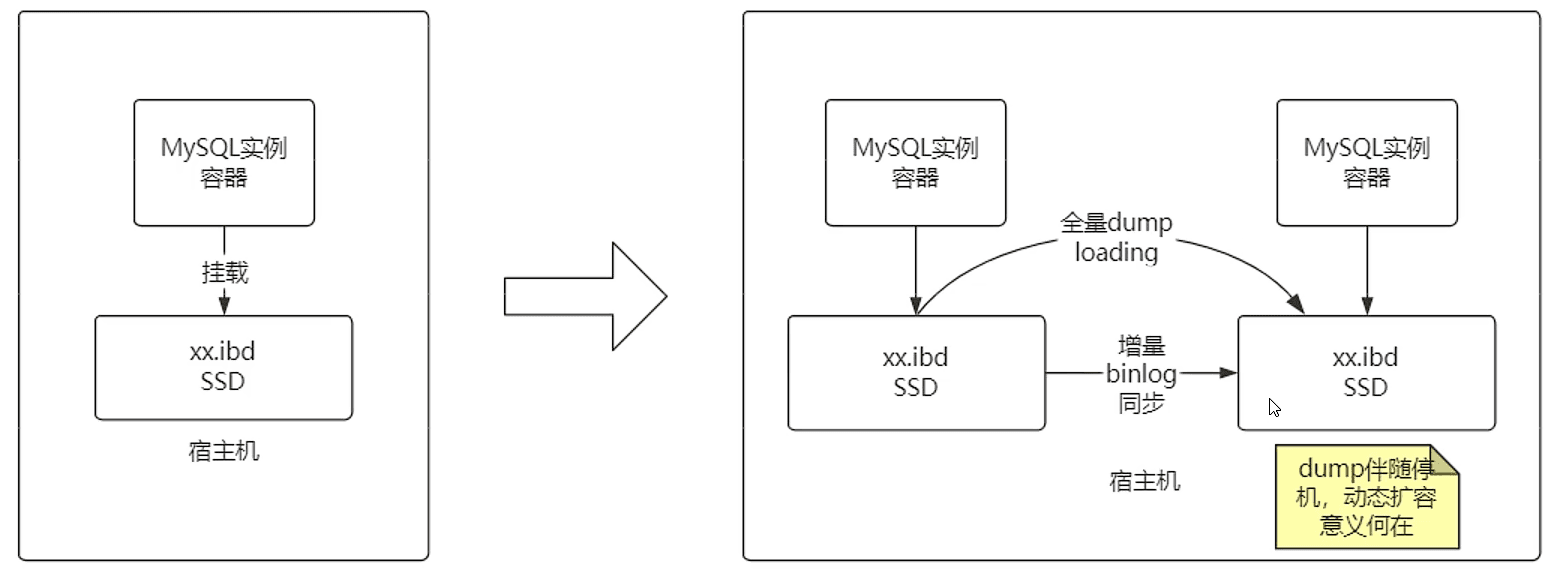
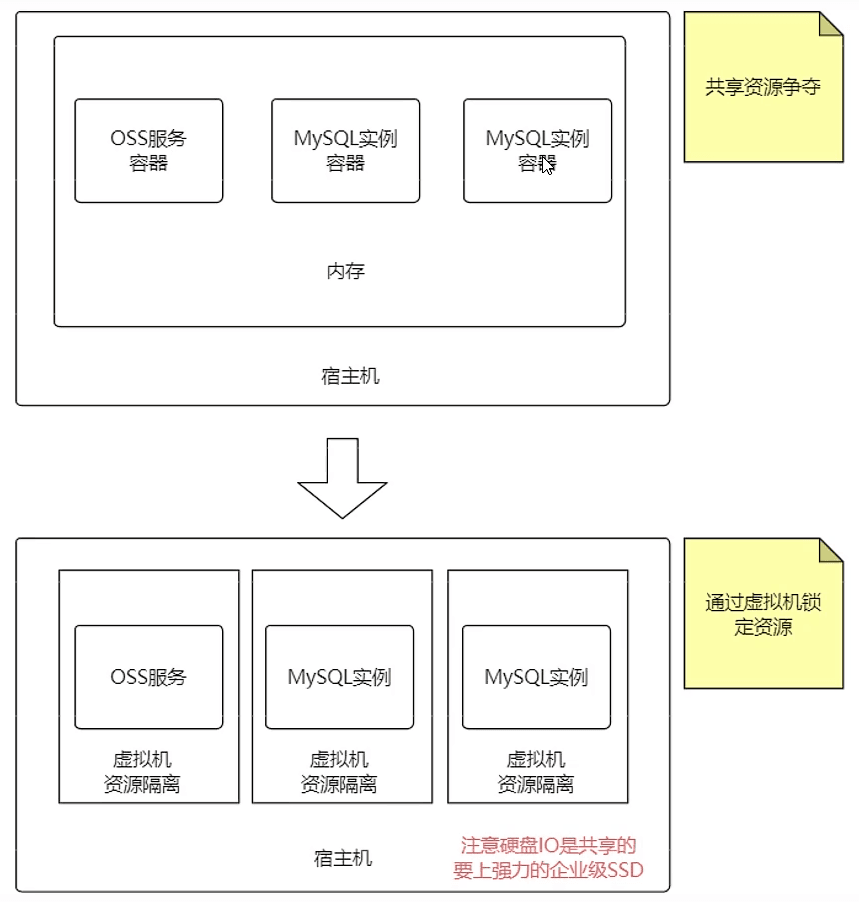
从应用场景上,数据存储节点是少量而稳定的
大多数场景并没有“灵活扩容”的需求
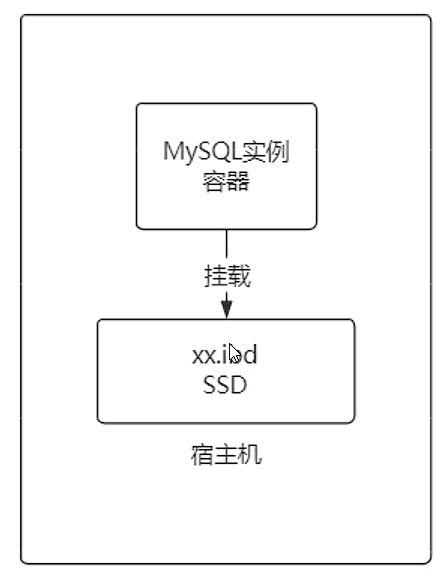
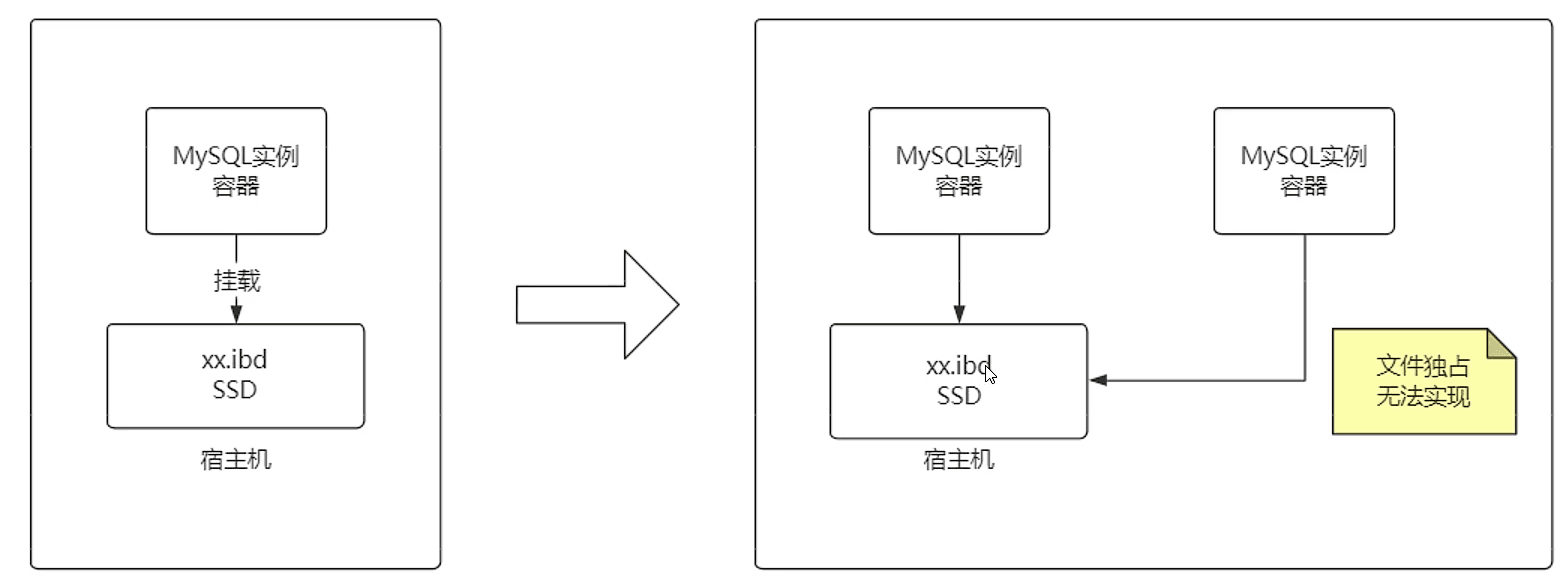
从技术方面,MySQL容器是“有状态”的
无法轻易的水平扩容
【116】如何优雅的保存 mysql 数据变更历史?
来源:https://www.bilibili.com/video/BV12L4y1T74v/?spm_id_from=pageDriver
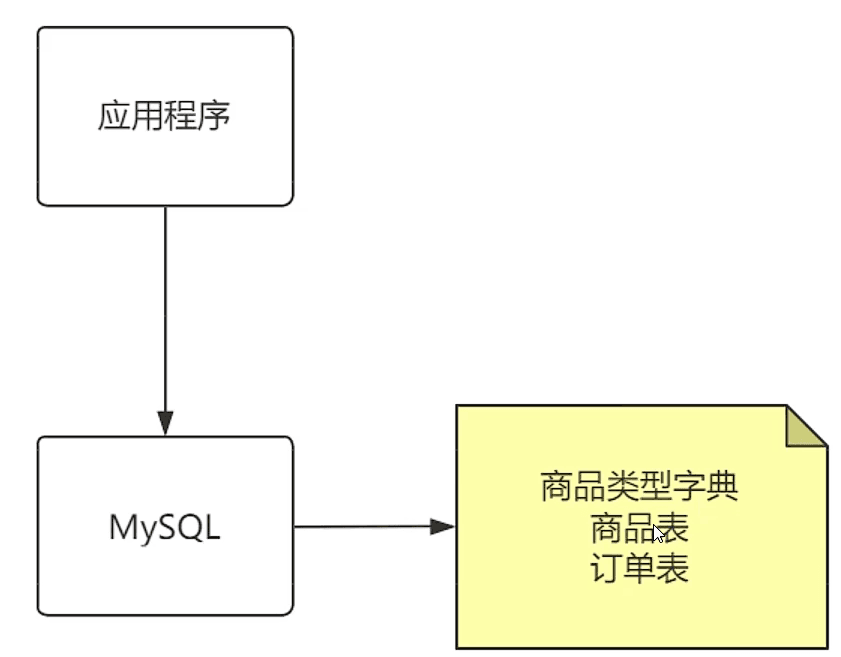
需要记录订单表的任何记录变更

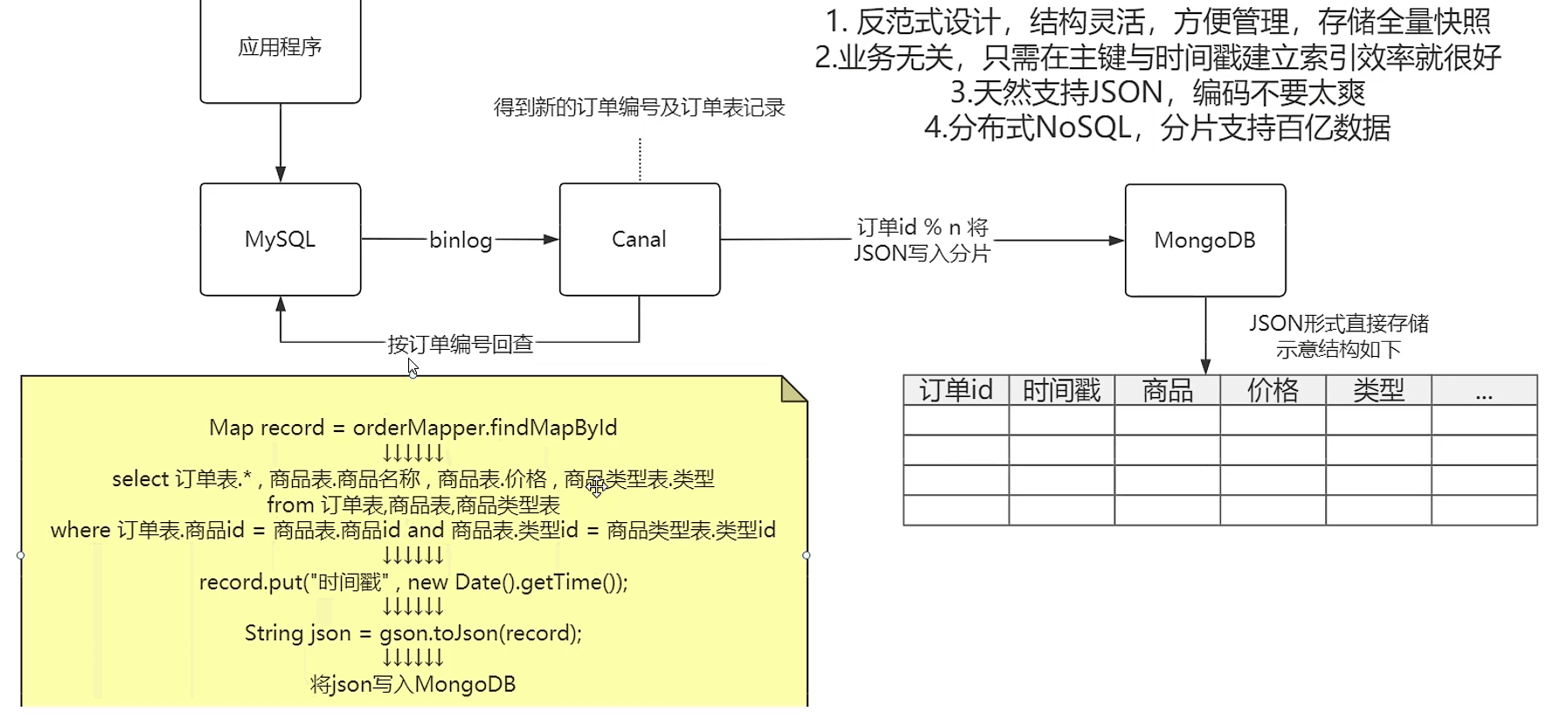
【120】MySQL 什么时候需要分库分表,又有哪些新问题?
来源:https://www.bilibili.com/video/BV1b44y1N7Up/?spm_id_from=333.788
单表数据量超过1000W
或单表数据文件(.ibd)超过 20GB
单库单表:原始方案
单库多表:有效缩小磁盘扫描范围
多库多表:提供数据库并行处理能力
分库分表后的新挑战
一、分布式事务问题
引入XA、TCC、SAGA 等分布式事务解决方案
二、跨库 JOIN 关联查询
解决方案1:程序先查 A 表,再循环查询 B 表
解决方案2:MyCat、ShardingSphere 支持两表跨库 Join
三、跨节点分页查询问题
单节点各取 n 条,之后在程序合并运算取 top n
四、全局主键 ID 问题
采用分布式主键生成器,推特 SnowFlake、美团 Leaf
(不建议 UUID,无序主键会产生页分裂)
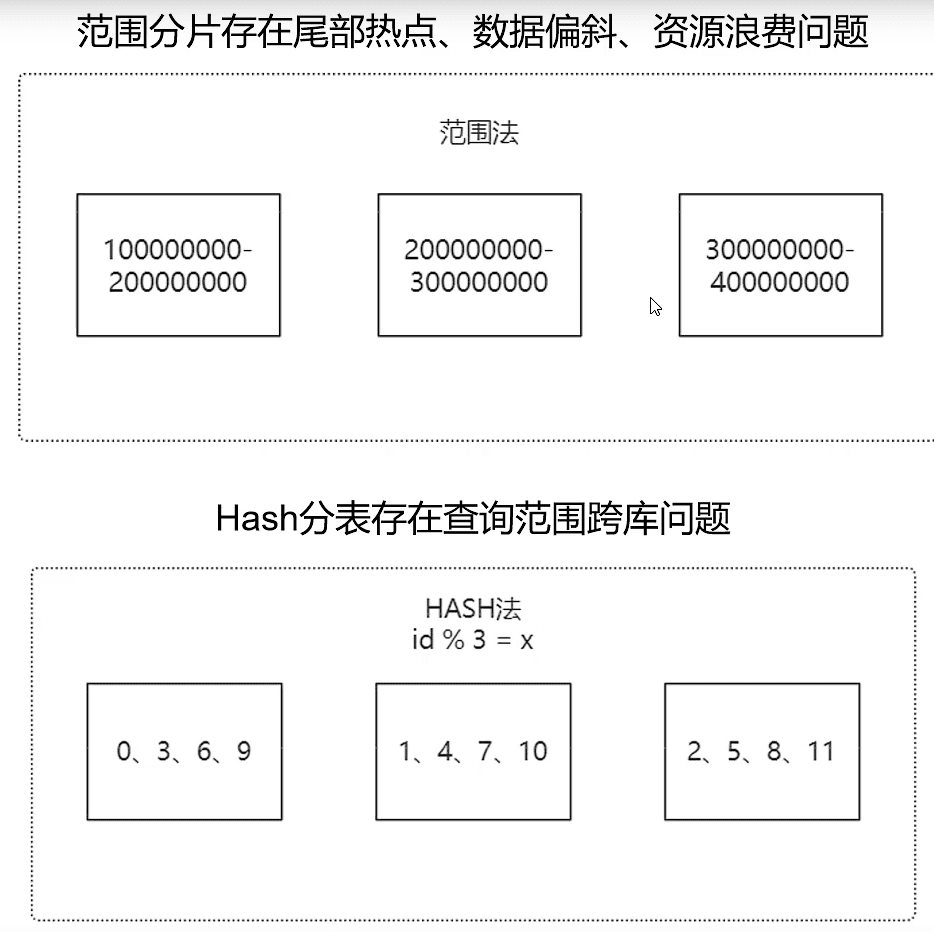
五、扩容问题
范围分表容易扩容,但存在尾部热点问题
Hash 分表极难扩容,建议改为一致性 Hash,但迁移难度较大
【127】用好了性能直接起飞,基因法与倒排索引在 MySQL 分库分表的应用
来源:https://www.bilibili.com/video/BV1QL4y1771n?spm_id_from=333.999.0.0
分库分表时的挑战
按 uid 分库,如果按 username 查询数据时就需要扫描全表,如何优化呢?
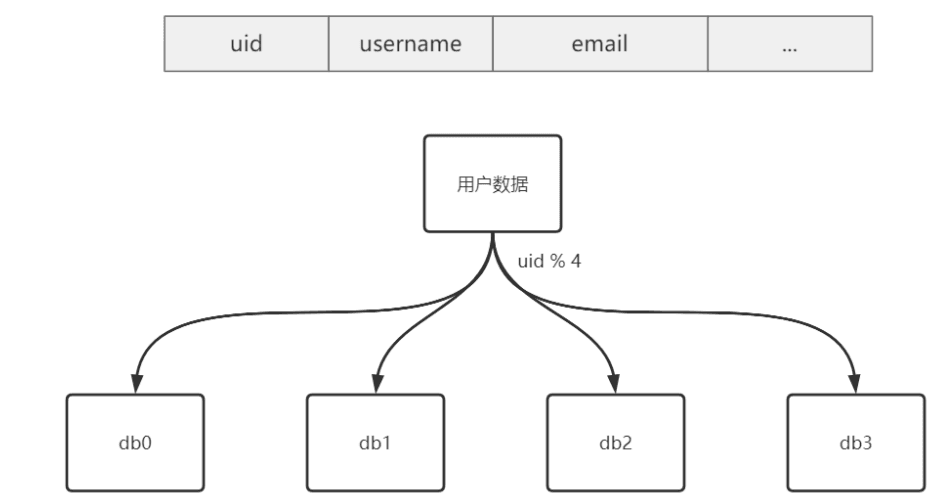
基因法
基因法的生成原理

基因法的快速定位

基因法优缺点
● 基因法优点
1.性能极好,不用额外查询便可快捷分表查询
● 基因法缺点
1.建议2(1)/4(2)/8(3)/16(4)数据库节点,提前规划不具备迁移条件
2.主键生成器算法要求更高,如 62+2 全局唯一
3.只能由1个非主键字段与之主键对应
使用场景
在关键字段上使用
倒排索引法
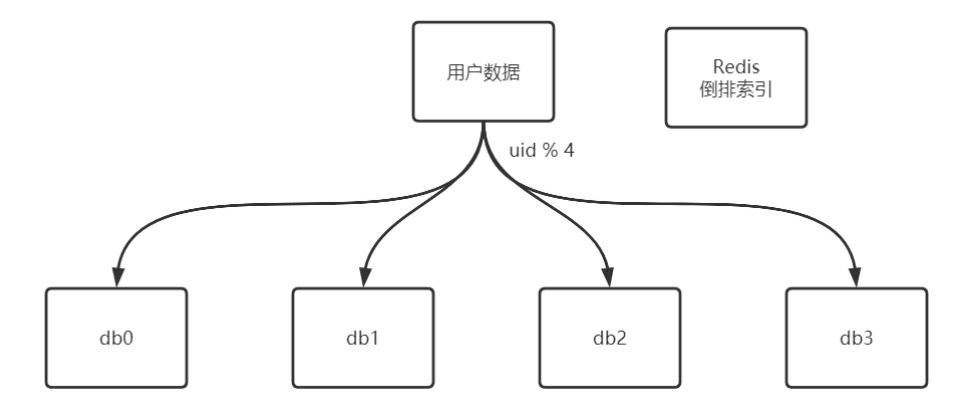
Redis倒排索引示例
Redis 倒排索引
| key | value[uid,server] |
|---|---|
| ur_email:xx@itlaoqi.com | 9,1 |
| ur_email:abc@itlaoqi.com | 11,0 |
| ur_mobile:133xxxxx | 247,3 |
| ur_mobile:178xxxxx | 2136,2 |
倒排索引优缺点
● 倒排索引优点
—-· 最通用的分库分表检索方案,几乎适用于所有系统
● 倒排索引缺点
—-· 多一次查询,性能有所降低
—-· 控制不好数据量爆炸,对Redis内存需求量大(如果 SSD 性能好,也可使用 InnoDB 表替代)
—-· 需要手动维护数据库与缓存间的一致性,存在软状态
【125】眼不瞎就能发现慢 SQL 瓶颈,Visual Explain 可视化执行计划快速上手
来源:https://www.bilibili.com/video/BV13L411A7eM/?spm_id_from=333.788
下载地址:https://dev.mysql.com/downloads/workbench
文档地址:
链接:https://pan.baidu.com/s/10cYotbr1KPN-L6Dn1Q9MEA
提取码:nqpe
【133】牛逼!200 毫秒干到 10 毫秒,利用 MySQL JSON 特性优化千万级文库表
来源:https://www.bilibili.com/video/BV1WP4y1K7xB/?spm_id_from=333.788
系统表结构
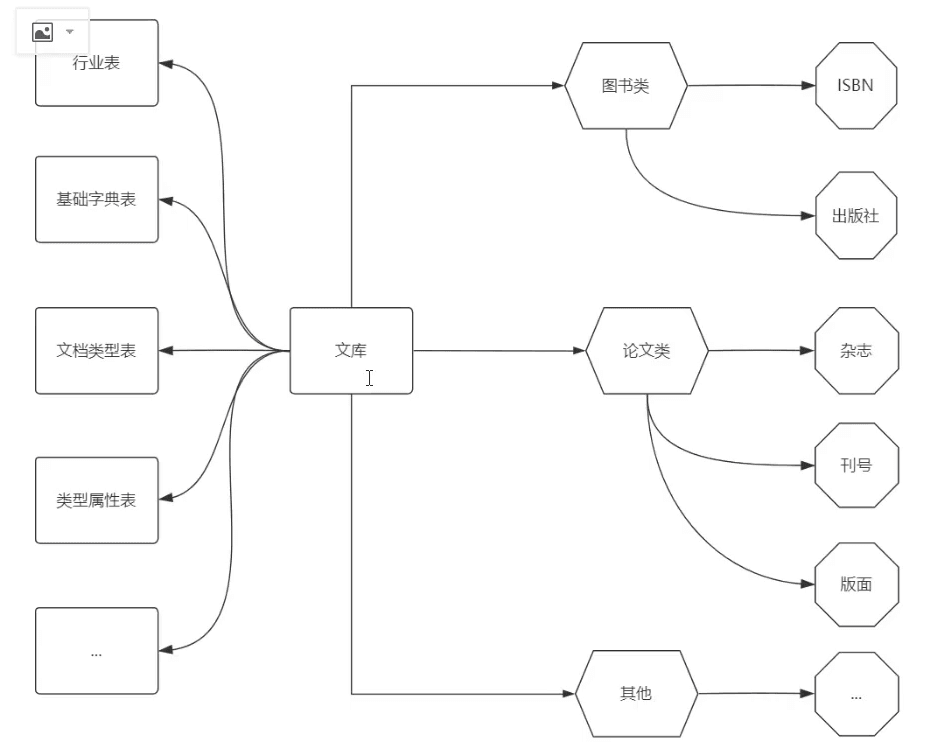
单文档获取流程
1.获取文档主体
2.获取文档类型
3.获取文档拥有属性名
4.提取文档属性数据
5.获取行业信息(多对多)
6.获取若干基础数据
- ..
反范式设计,构建宽表
| doc_id | doc_name | … | isbn | 出版社 | 杂志 | 版面 |
|---|---|---|---|---|---|---|
| . |
select doc_ id,doc_ name,isbn,出版社 from 文库表 where isbn = xXXselect doc id,doc_ name,杂志,版面 from 文库表 where杂志=XXX
1.宽表基于列实现筛选使用不便,且无法表达一对多、 多对多关系
2.Redis 按多条件检索不方便,数据也不能保障强一致
使用 MySql JSON 类型

利用 JSON 解决动态数据问题,MySQL 5.7 以后提供了 JSON 数据类型,可以直接对 JSON 存储、提取与解析。
因为 JSON 是弱约束的,因此存储数据非常灵活,同时也可基于虚拟列实现索引优化。
案例
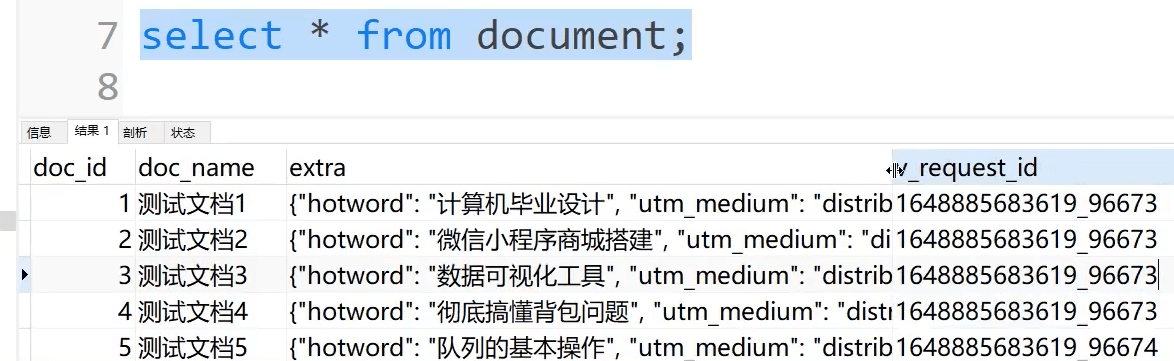
测试表结构
document
| 列名称 | 类型 | 长度 |
|---|---|---|
| doc_id | int | 11 |
| doc_name | varhcar | 255 |
| extra | json | 0 |
表数据

select extra->'$.dist_request_id' from document
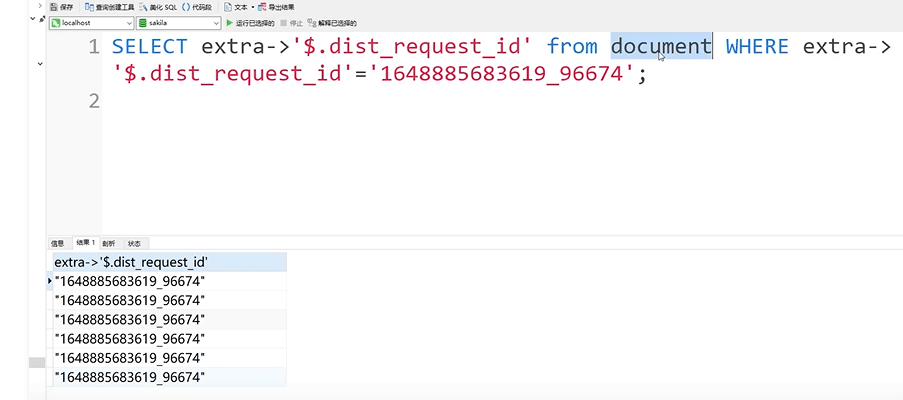
这样查询很麻烦,可以使用新增虚拟列的方式解决
alter table documentadd column `v_request_id` varchar(32)#generated always as() 始终继续虚拟列自动生成#json_extract(`extra`,_utf8mb4'$.dist_request_id') 基于 extra 字段提取表达式 dist_request_id 的值#json_unquote() 解除与 json 的引用#virtual 虚拟列#null 允许为空generated always as(json_unquote(json_extract(`extra`,_utf8mb4'$.dist_request_id'))) virtual null;
建立好之后,当做正常列来使用
还可以建立索引,提高速度
