来源
课件地址:https://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/it300/download/ppt_all_in_one.zip
【004】-为什么架构师对多级缓存架构情有独钟?
来源:https://www.bilibili.com/video/BV1Lq4y1975x?spm_id_from=333.999.0.0
缓存是提升性能最直接的方法
什么是多级缓存架构
多级缓存分为:客户端,应用层,服务层,数据层

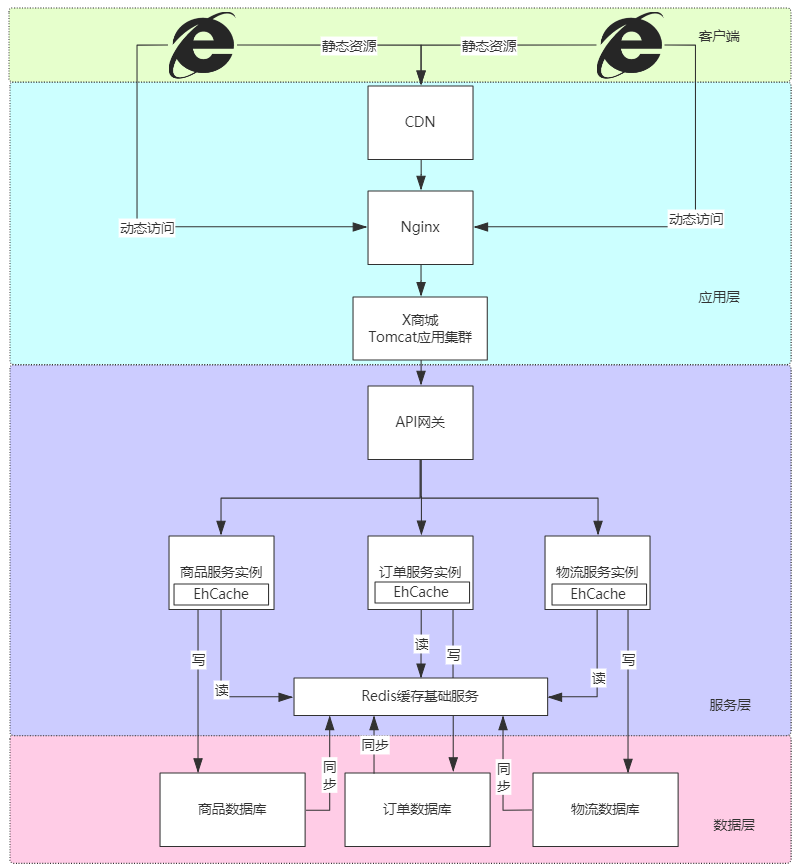
客户端缓存
客户端缓存:主要对浏览器的静态资源进行缓存。
通过在浏览器设置 Expires,时间段内以文件形式把图片保存在本地,减少多次请求静态资源带来的带宽损耗(解决并发手段)。
响应头 Expires 与的 Cache-Control 的区别
● Expires 是指定具体某个时间点缓存到期。
● 而 Cache-Control 则代表缓存的有效期是多长时间。
● Expires 设置时间。
● Cache-Control设置时长。
即:你明天还钱给我 Expires,时间是一天 Cache-control
应用层缓存
应用层缓存: 浏览器只负责读取 Expires,Expires 在 CDN 内容分发网络和 Nginx 进行设置
CDN
CDN 内容分发网络是静态资源分发的主要技术手段,有效解决带宽集中占用以及数据分发问题。
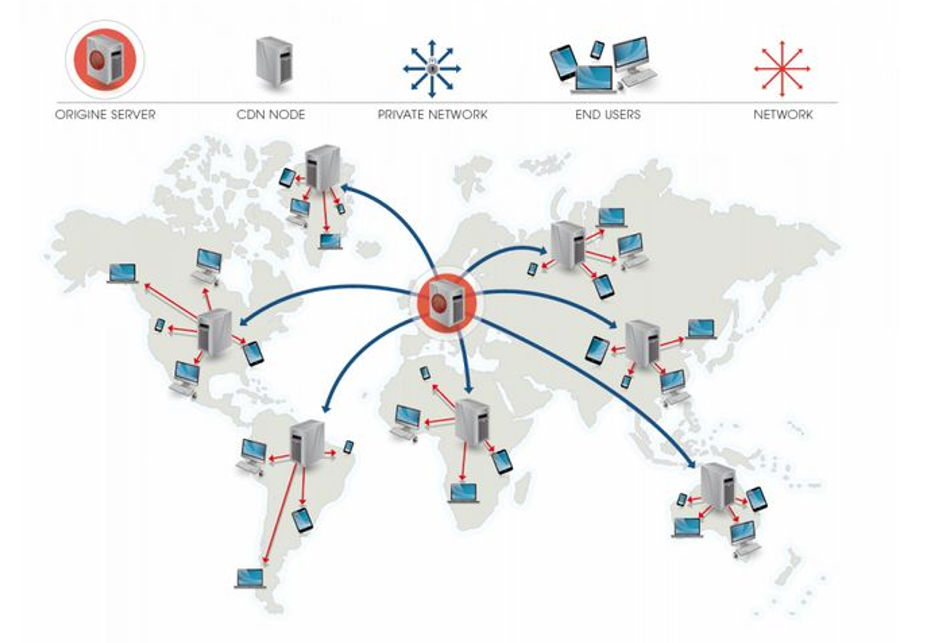
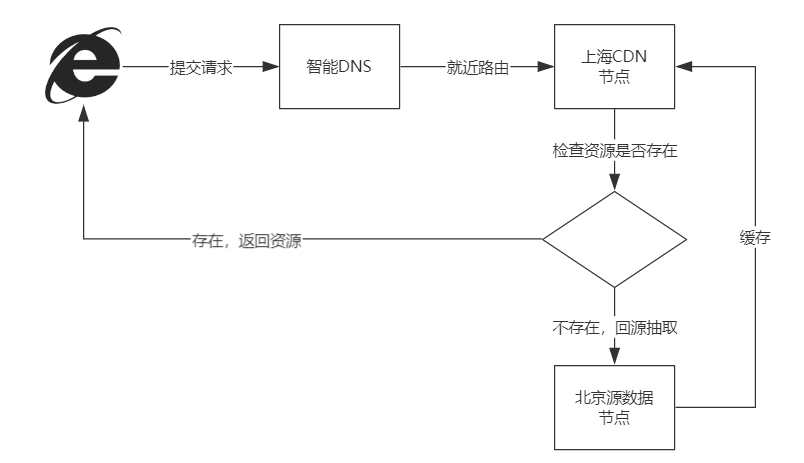
CDN 的核心技术:
根据请求访问 DNS 节点, 自动转发到上海 CDN 节点,检查资源是否被缓存,若已缓存则返回资源否则回源北京提取到并缓存到上海 CDN 节点,再由上海 CDN 节点进行返回。
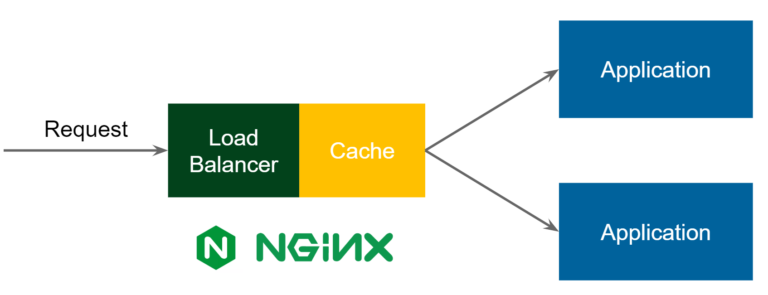
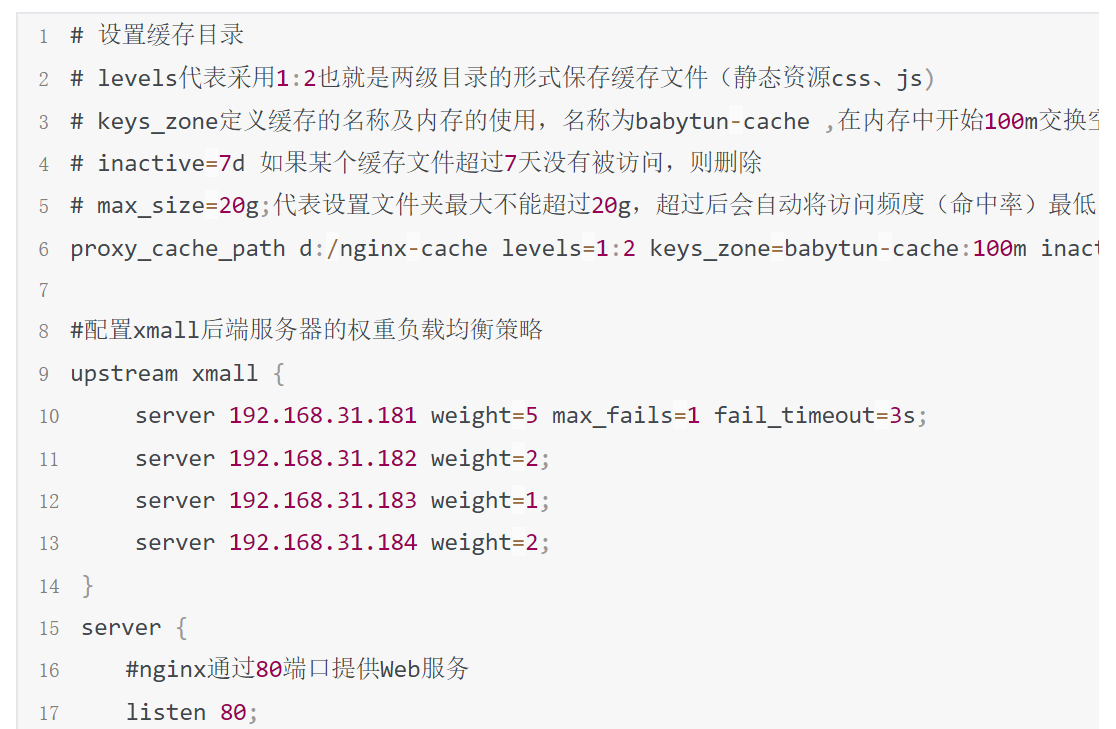
Nginx 缓存管理
Nginx缓存管理:
Nginx 对 Tomcat 集群做软负载均衡,提供高可用性。有静态资源缓存和压缩功能(在本地缓存文件)
服务层缓存
服务层缓存:进程内缓存和进程外缓存
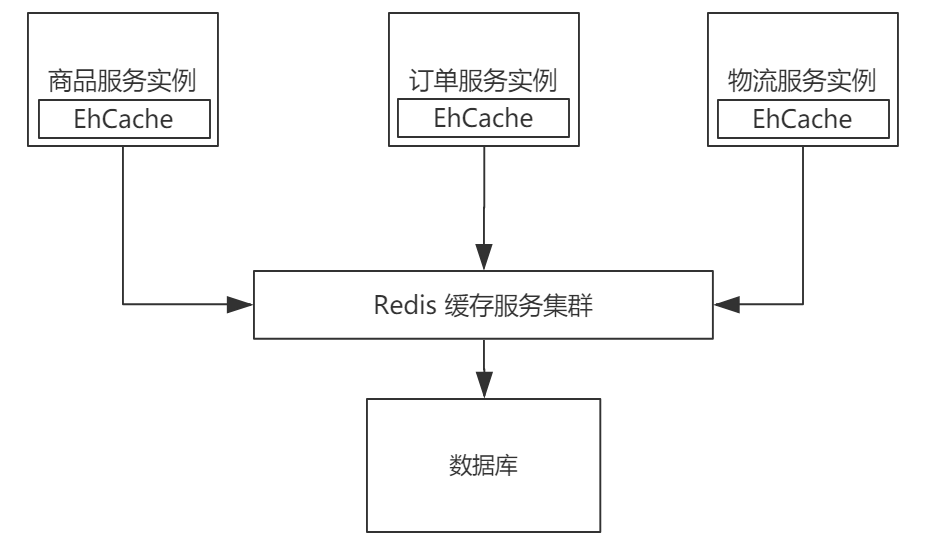
进程内缓存:即数据运行时载入程序开辟的缓存中 JAVA 框架的运用(hibernate,mybatis 一二级缓存, springmvc 页面缓存)
开源实现:ehcache,Caffeine
进程外缓存:即为分布式缓存(redis)
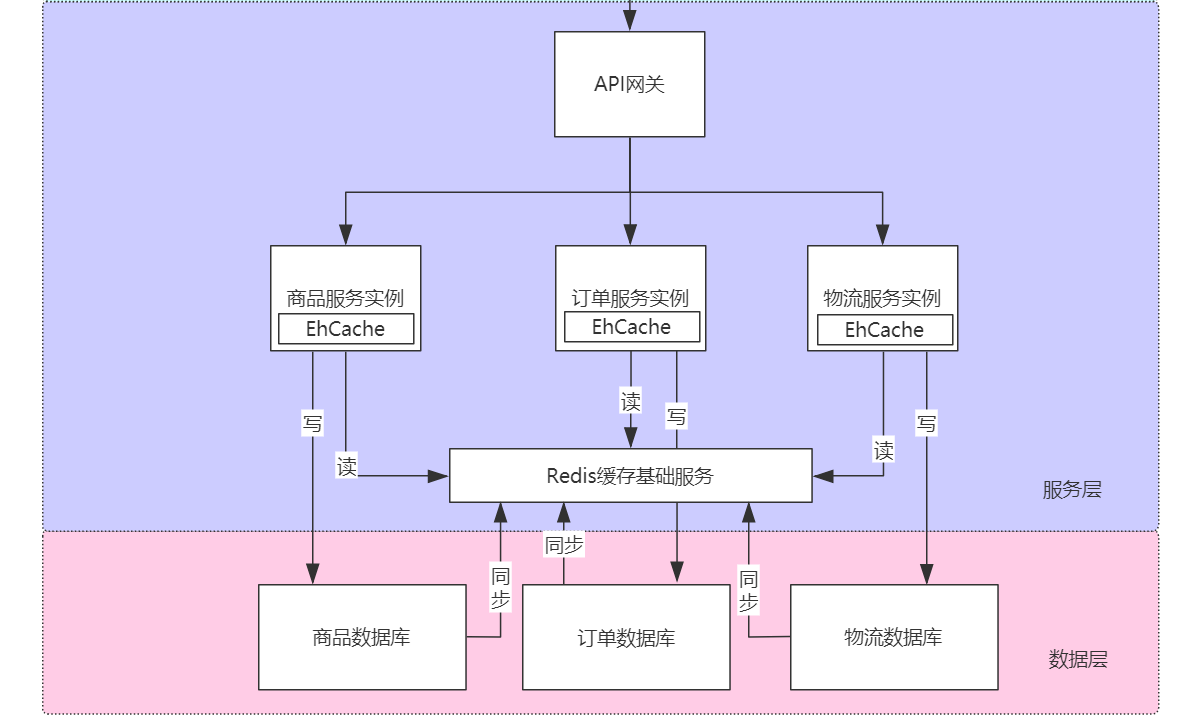
常见的加缓存是直接加 redis 是不严谨的。
需要按照:先近到远,先快后慢逐级访问
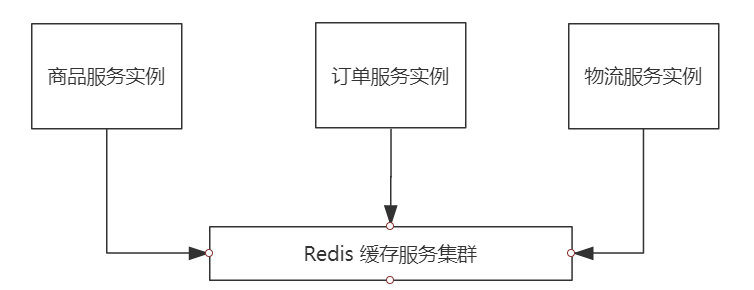
场景:商品秒杀,若无本地缓存,都保存在 redis 每完成一笔交易,局域网会进行若干网络通信,可能存在网络异常不稳定因素
且 redis 会承担所有节点的压力,当突发流量若超过容载上限 redis 会崩溃
所有 java 的应用端也需要设计多级缓存
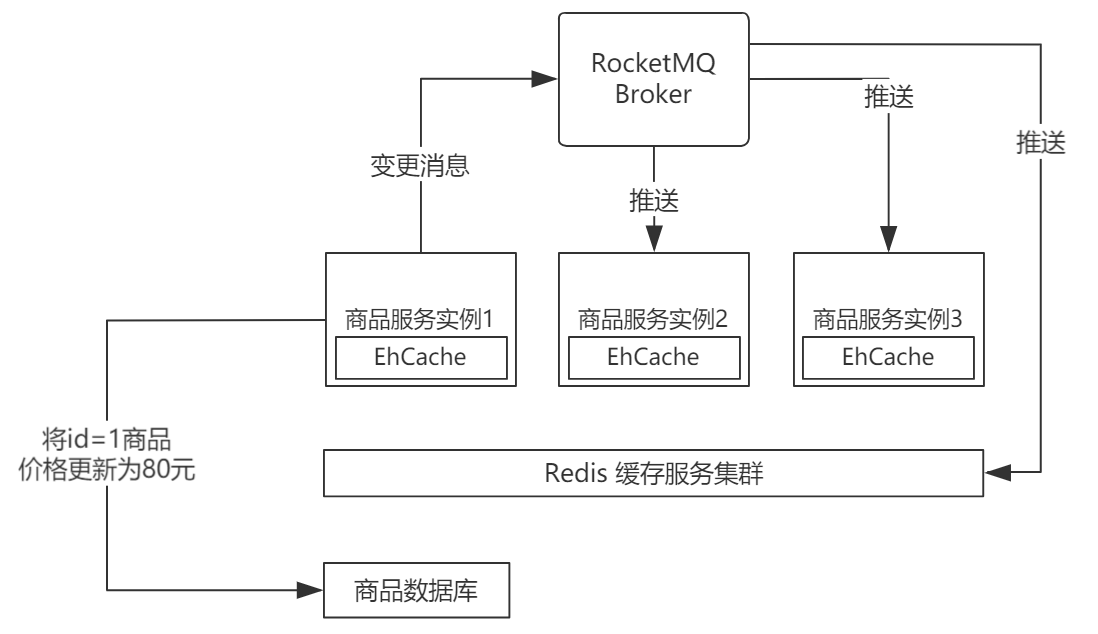
缓存一致性处理:
场景:修改商品价格为 80,如何保证缓存也进行更新
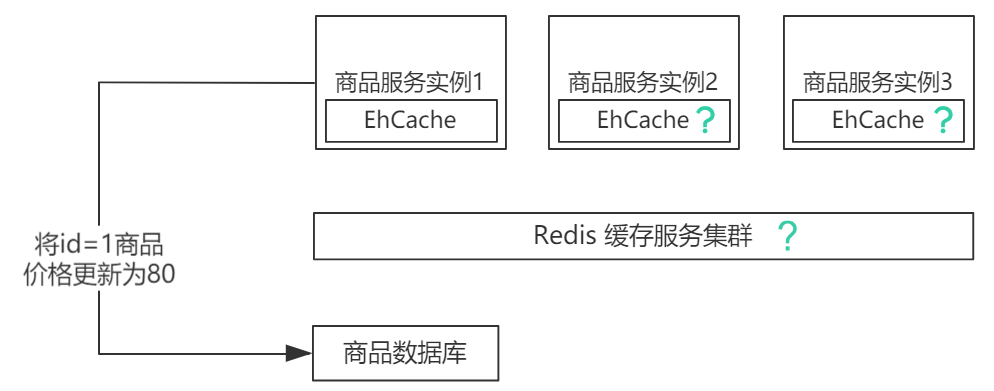
处理方法:引入消息队列(MQ)的主动推送功能,对服务实例推送变更实例
即:修改商品价格为 80,向 MQ 发送变更消息,MQ 将消息推送到服务实例服务实例将原缓存数据删除,再创建缓存
数据层缓存
什么情况适用多级缓存架构?
第一种情况,缓存的数据是稳定的。
第二种情况,瞬时可能会产生极高并发的场景。
第三种情况,一定程度上允许数据不一致。
【008】布隆过滤器在亿级流量电商系统的应用
来源:https://www.bilibili.com/video/BV1eU4y1J7GY?spm_id_from=333.999.0.0

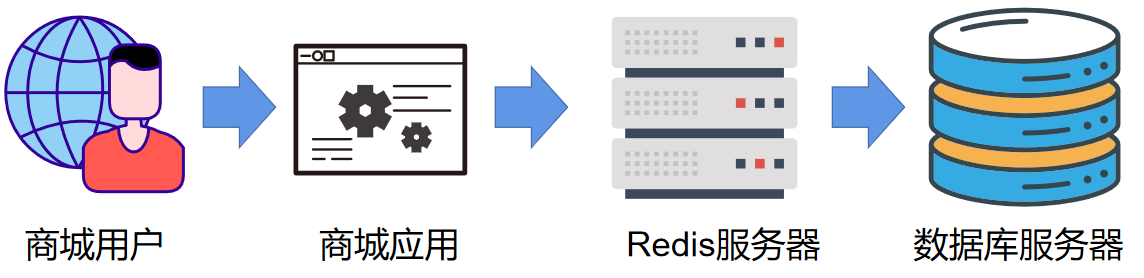
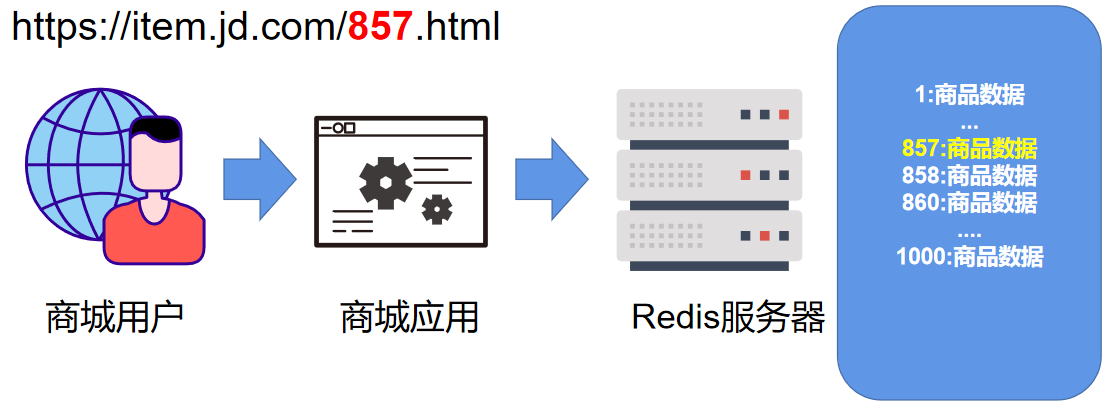
场景:正常 redis 有 1000 条缓存数据,忽然遭到爬虫/流量攻击攻击,大量不存在的于 redis 的数据批量查询,由于 redis 不存在这些数据,会到数据库进行查询。由于数据库对于瞬时高并发访问的承载能力弱,所以可能对数据库造成影响,甚至崩溃。
缓存穿透:缓存穿透攻击是指恶意用户在短时内大量查询不存在的数据,导致大量请求被送达数据库进行查询,当请求数量超过数据库负载上限时,使系统响应出现高延迟甚至瘫痪的攻击行为。
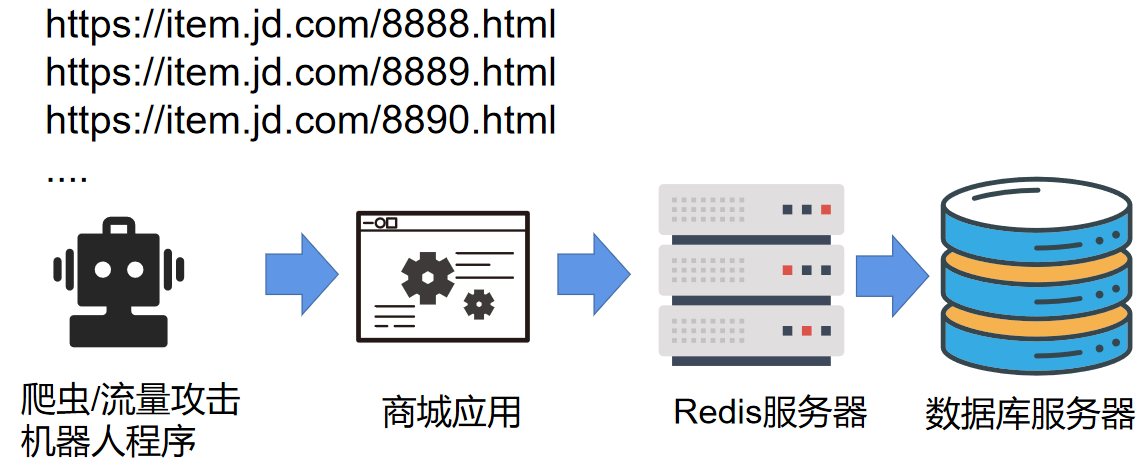
那如何预防缓存穿透呢?布隆过滤器(BloomFilter)
巴顿.布隆于一九七零年提出的,其主旨是采用一个很长的二进制数组,通过一系列的 Hash 函数来确定该数据是否存在。
布隆过滤器:由一个很长的二进制向量和一系列随机映射函数组成,可以用于检索一个元素是否在一个集合中。
特点:
1.一定的误识别率(即某一元素存在于某集合中,但是实际上该元素并不在集合中)
2.但是没有识别错误的情形(即如果某个元素确实没有在该集合中,那么 Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
也就是:我说你不在你就一定不在,我说在,可能不在。
3.删除困难
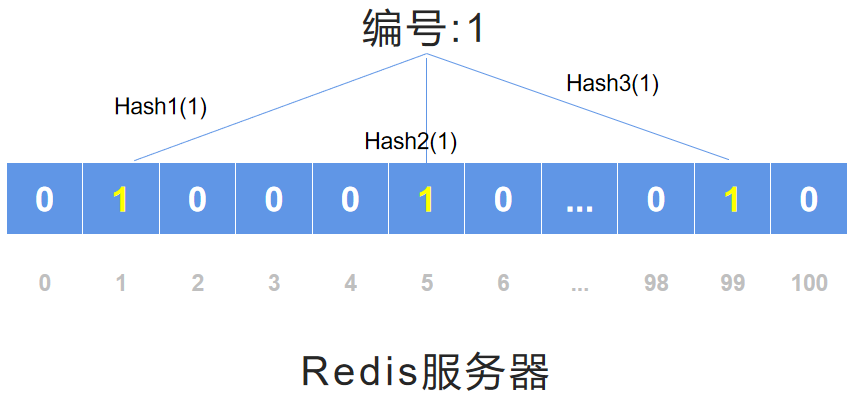
布隆过滤器的初始化过程
Hash (散列函数):是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值。
由于这种转换,可能存在不同的输入可能会散列成相同的输出。
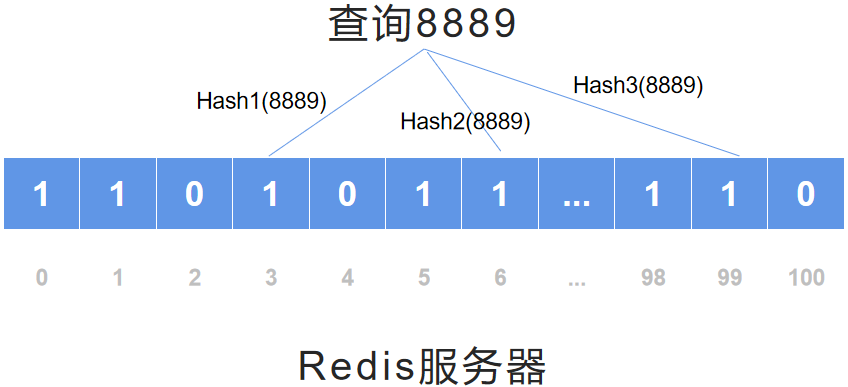
Hash 算法可以将一个数据转换为一个标志,这个标志,就是视频说的 hash,hash 后若不存在,就由 0 变为 1。存在,不变。

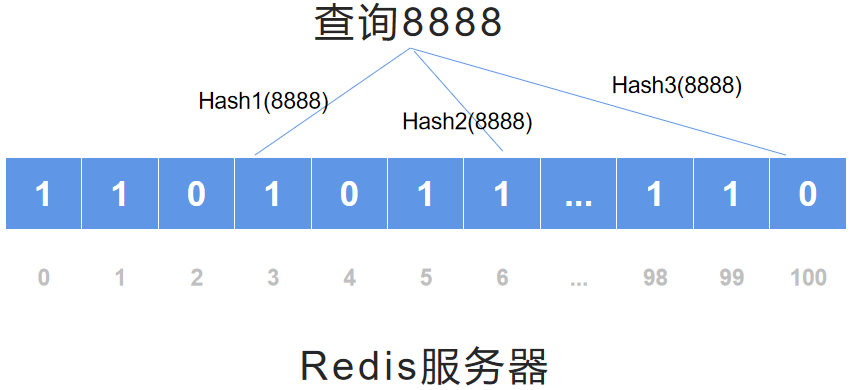
hash1(858),hash2(858),hash3(858)的原理是:
Hash 面临的问题就是冲突。假设 Hash 函数是良好的,如果我们的位阵列长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素。显然这就不叫空间有效了(Space-efficient)。
解决方法也简单,就是使用多个 Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
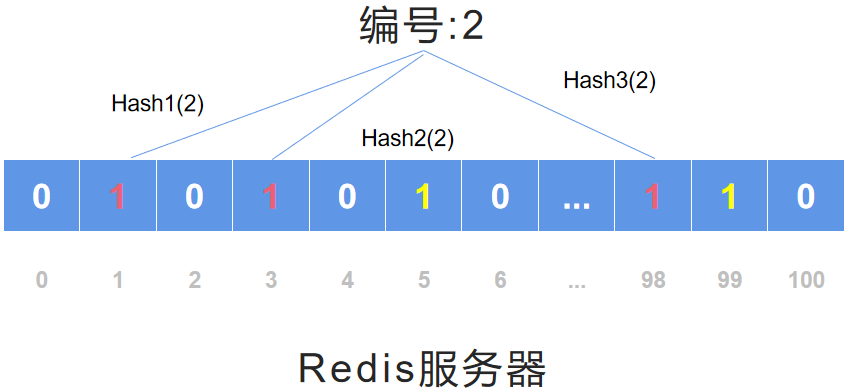
布隆过滤器的初始化完毕状态
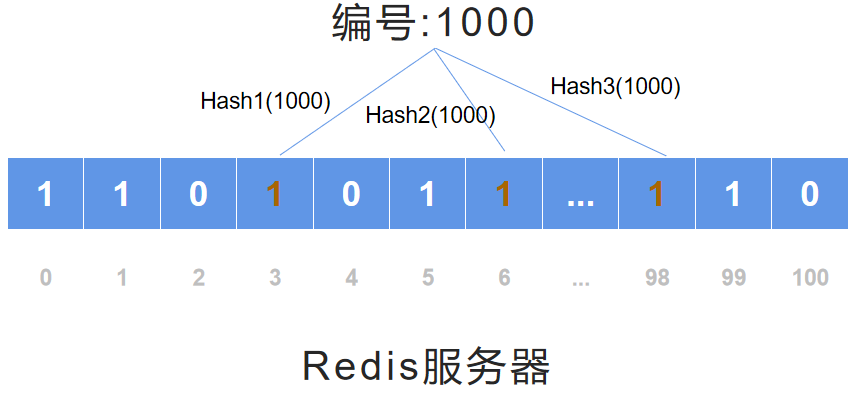
布隆过滤器的判断过程
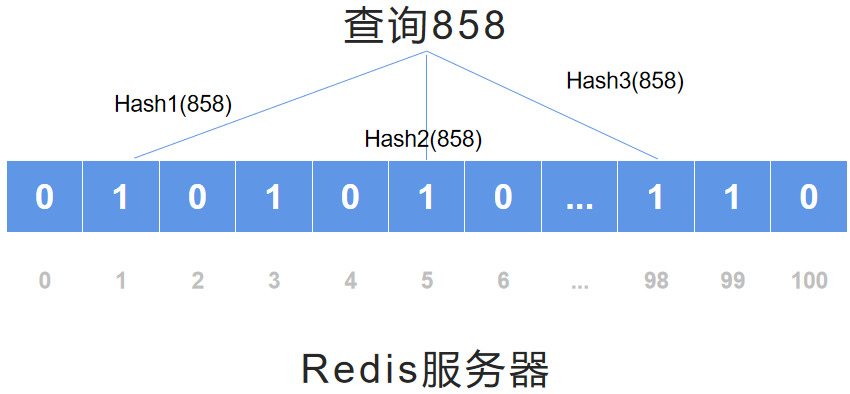
布隆过滤器拦截不存在数据
布隆过滤器的误判情况
减少误判的措施
● 增加二进制数组位数
● 增加 Hash 次数
Java 运用布隆过滤器
开发中如何使用?redisson 组件内置布隆过滤器,导入直接使用。
<dependency><groupId>org.redisson</groupId><artifactId>redisson-all</artifactId><version>3.16.0</version></dependency>
Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379");//构造RedissonRedissonClient redisson = Redisson.create(config);RBloomFilter<String> bloomFilter = redisson.getBloomFilter("bloom");//初始化布隆过滤器:预计元素为1000000L,误判率为1%bloomFilter.tryInit(1000000L,0.01);bloomFilter.add("1"); //增加数据//判断指定编号是否在布隆过滤器中System.out.println(bloomFilter.contains("1")); //输出trueSystem.out.println(bloomFilter.contains("8888"));//输出false
布隆过滤器在项目中的使用流程
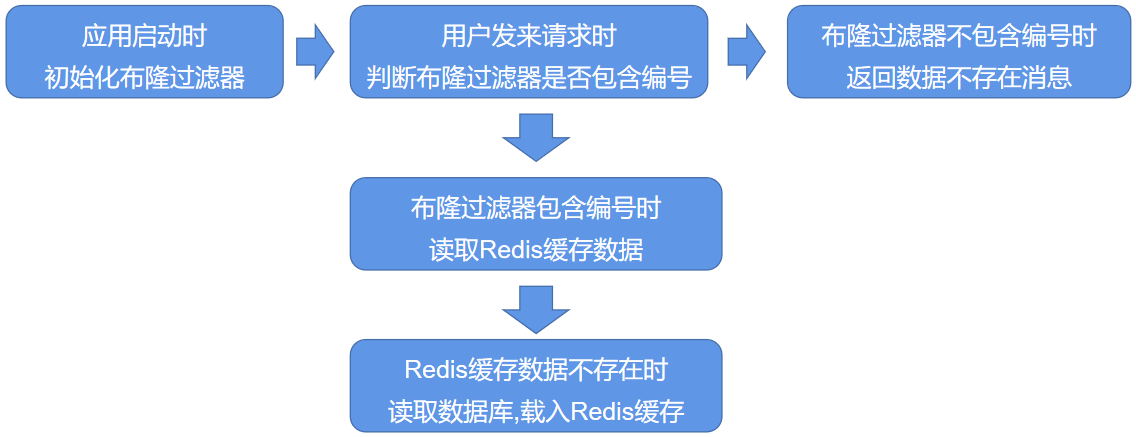
项目中如何使用:
应用启动时初始化布隆过滤器(将商品在布隆过滤器中先从 0 转换成 1)
用户请求时判断布隆过滤器是否有编号,若布隆过滤器有,读取 redis,若 redis 没有,则读取数据库,载入 redis 缓存。
若布隆过滤器没有,返回数据不存在消息。
假如商品被删除了该怎么办
布隆过滤器因为某一位二进制可能被多个编号 Hash 引用,因此布隆过滤器无法直接处理删除数据的情况
● 解决方案1:定时异步重建布隆过滤器
● 解决方案2:计数 Bloom Fliter
【018】Redis 架构很难懂?非也,七张图讲明白 Sentinel 高可用架构
来源:https://www.bilibili.com/video/BV1jM4y1V79K?spm_id_from=333.999.0.0
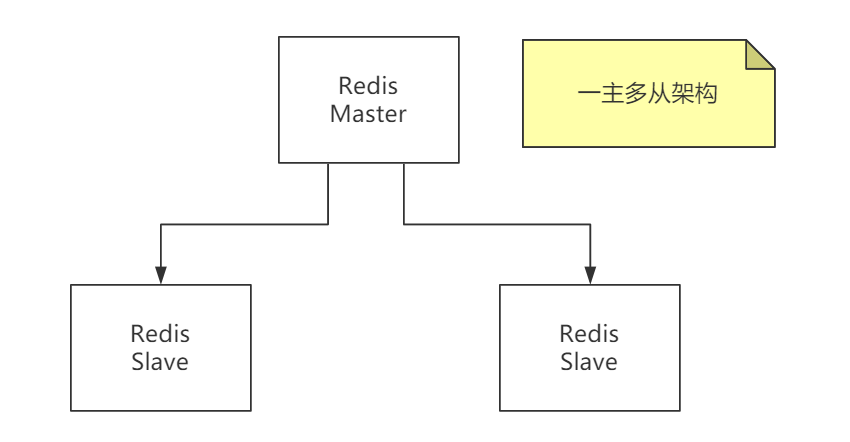
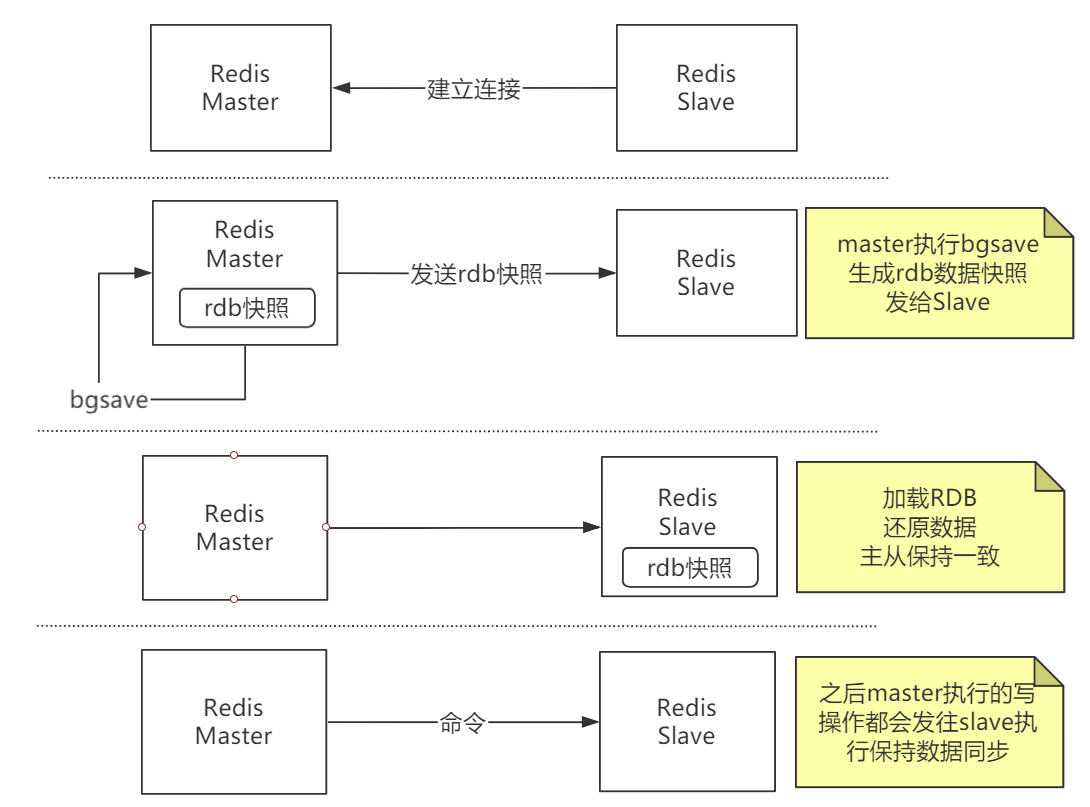
Redis 主从复制过程
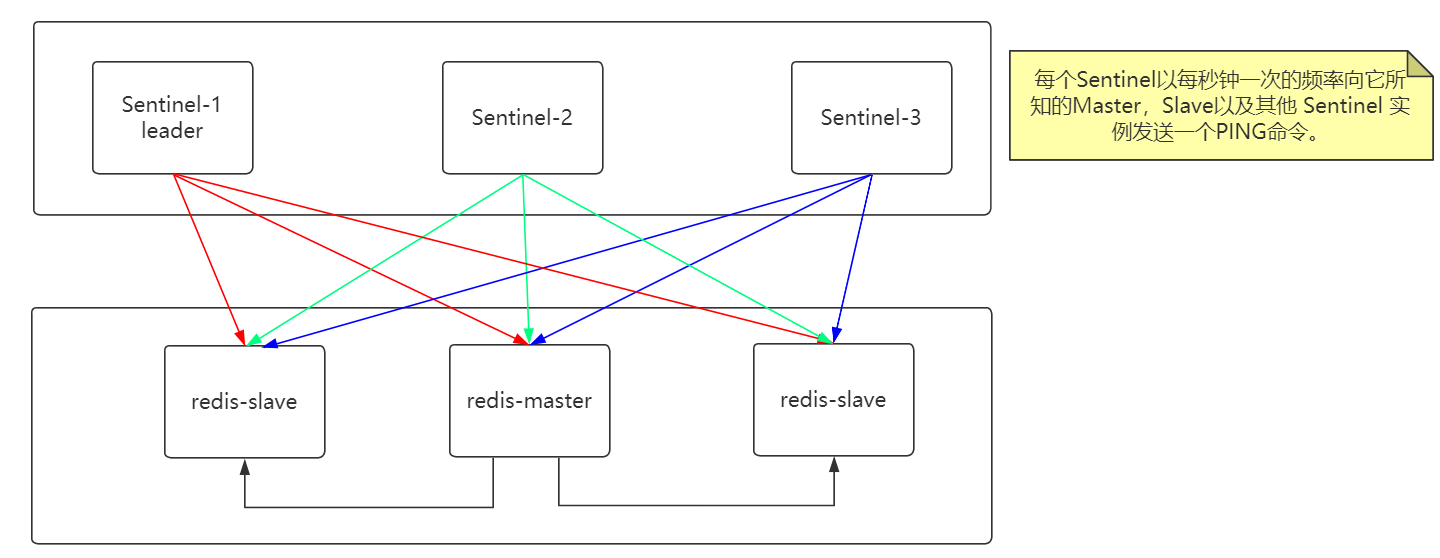
Redis Sentinel 高可用集群
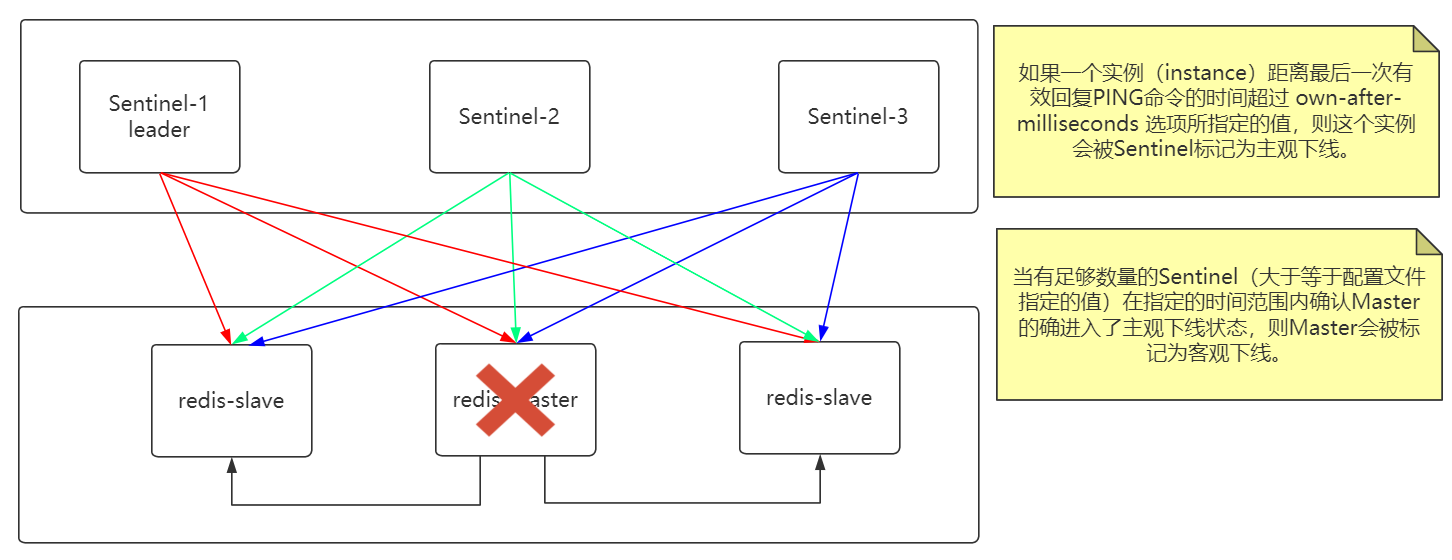
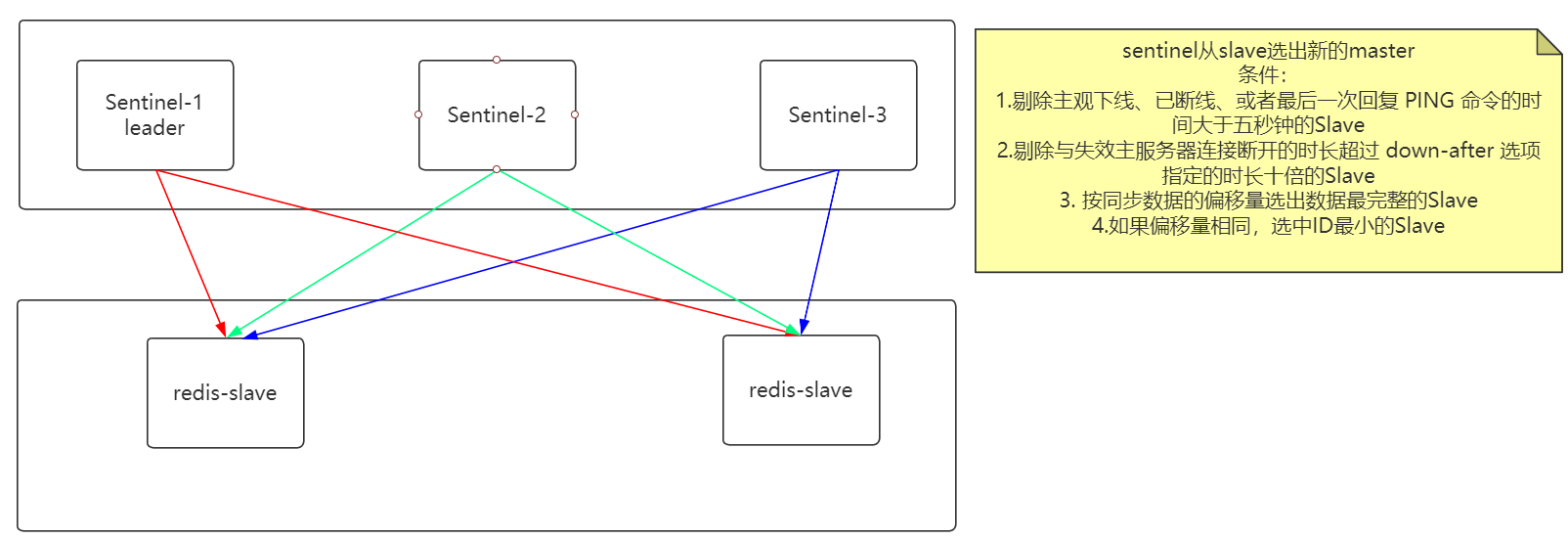
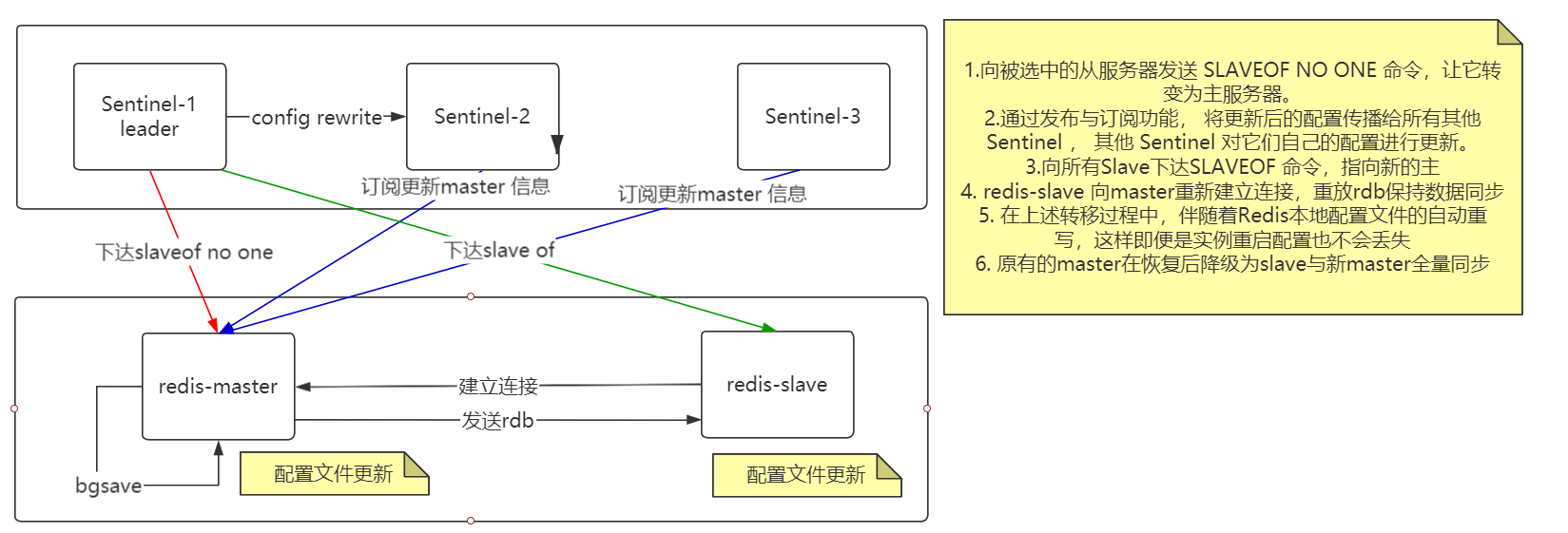
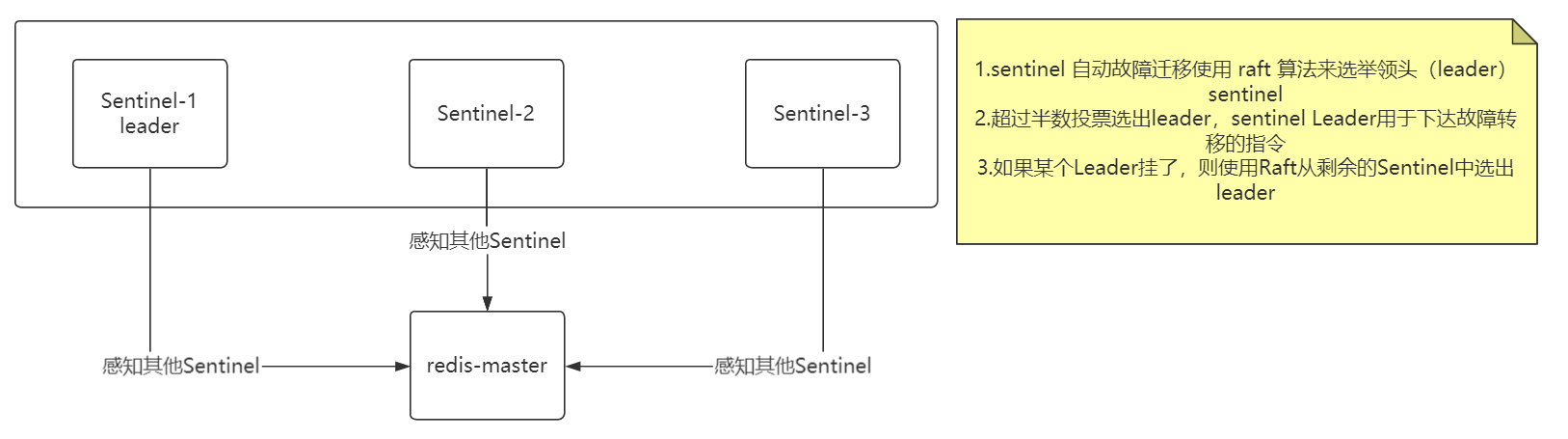
Sentinel 节点挂了怎么办?
【028】大厂必备技能,白话 Redis Cluster 集群模式
来源:https://www.bilibili.com/video/BV1F44y1C7N8/?spm_id_from=333.788.recommend_more_video.0
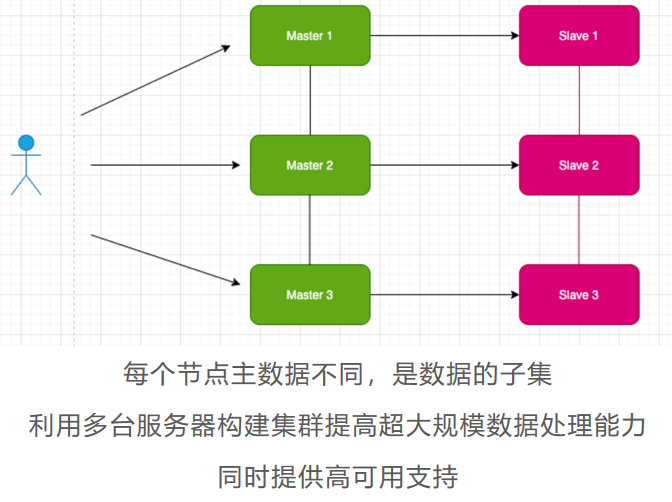
Redis Cluster 集群模式
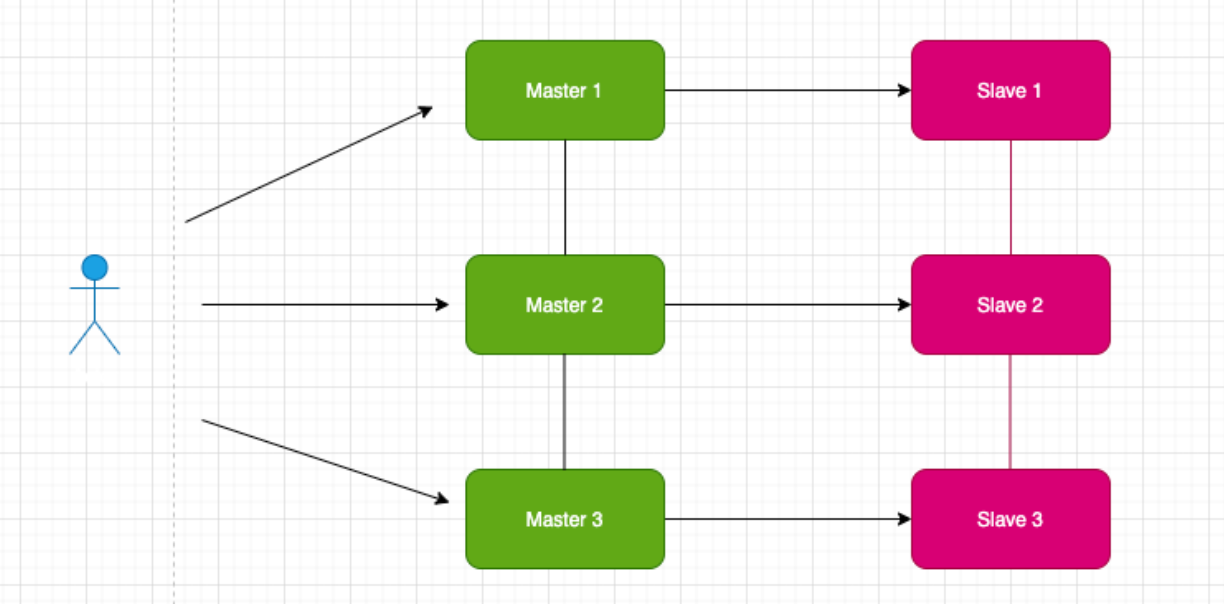
● Cluster 模式是 Redis3.0 开始推出
● 采用无中心结构,每个节点保存数据和整个集群状态, 每个节点都和其他所有节点连接
● 官方要求:至少 6 个节点才可以保证高可用,即 3 主 3 从;扩展性强、更好做到高可用
● 各个节点会互相通信,采用 gossip 协议交换节点元数据信息
● 数据分散存储到各个节点上
Redis Cluster 集群 与 Redis Sentinel 有什么不同?
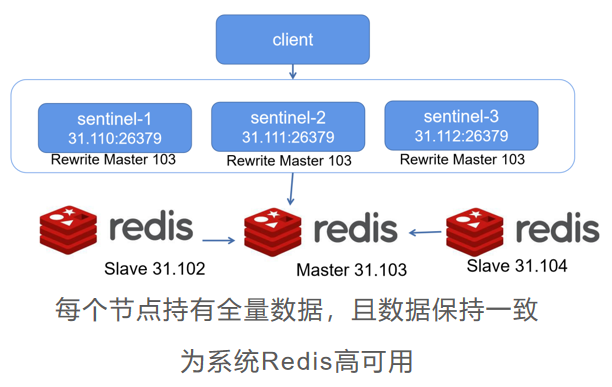
Redis Cluster 集群如何将数据分散存储
Redis Cluster 集群采用 Hash Slot(哈希槽)分配
Redis 集群预分好 16384 个槽,初始化集群时平均规划给每一台 Redis Master
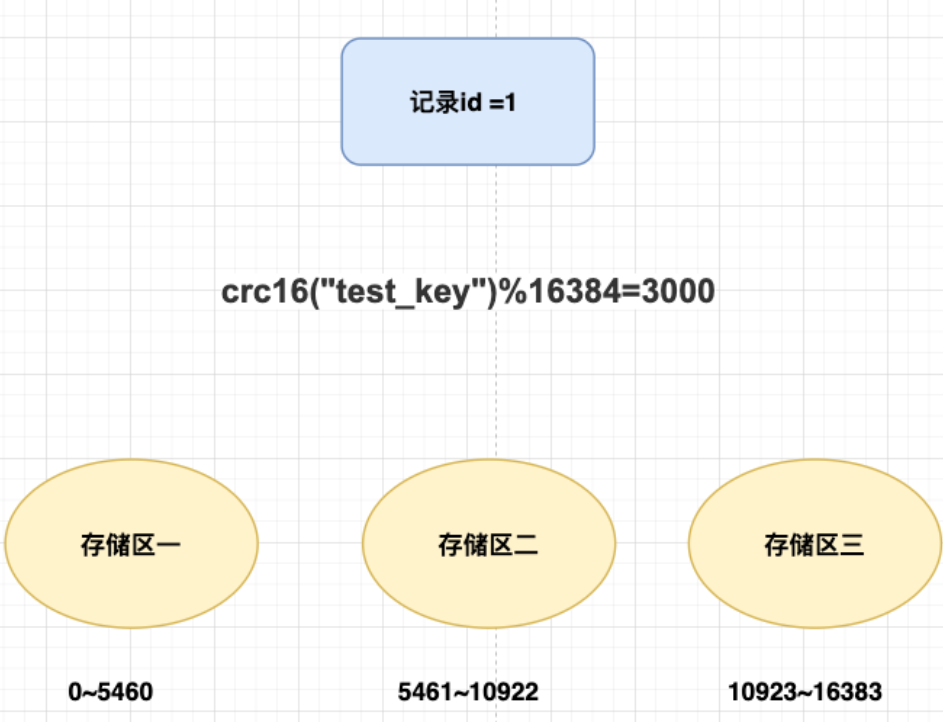
为什么是 16384?
在 Redis 集群中槽分配的元数据会不间断的在 Redis 集群中分发,以保证所有节点都知晓槽的分配情况
16384 = 16k,在发送心跳包时使用 char 进行 bitmap 压缩后是 2k(2 * 8 (8 bit) * 1024(1k) = 16K)
通常我们不同部署超过 10000 个 Redis 主节点,因此 16384 就够用了
Redis Cluster 集群构建流程
redis-cluster.conf
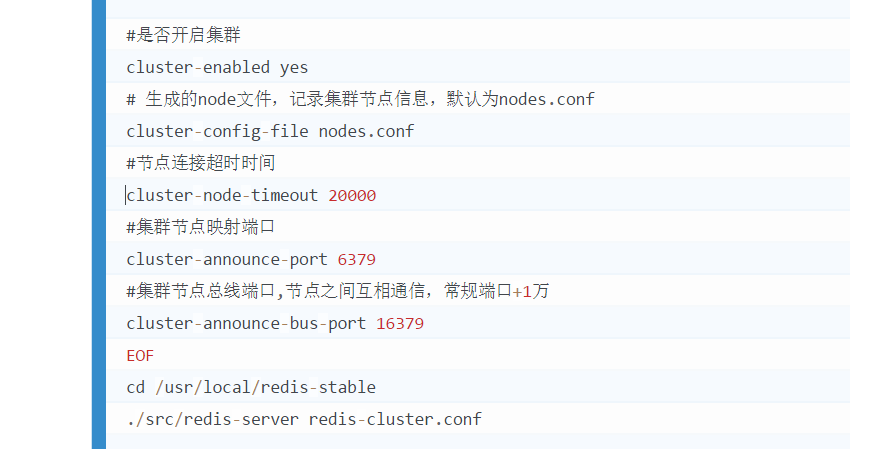
./src/redis-cli -a 123456 --cluster create192.168.31.102:6379 192.168.31.103:6379 192.168.31.104:6379 192.168.31.110:6379 192.168.31.111:6379 192.168.31.112:6379--cluster-replicas 1
启动日志
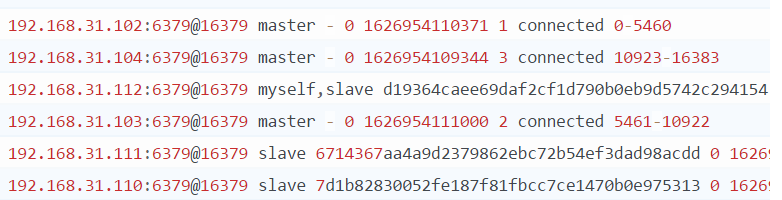
设置
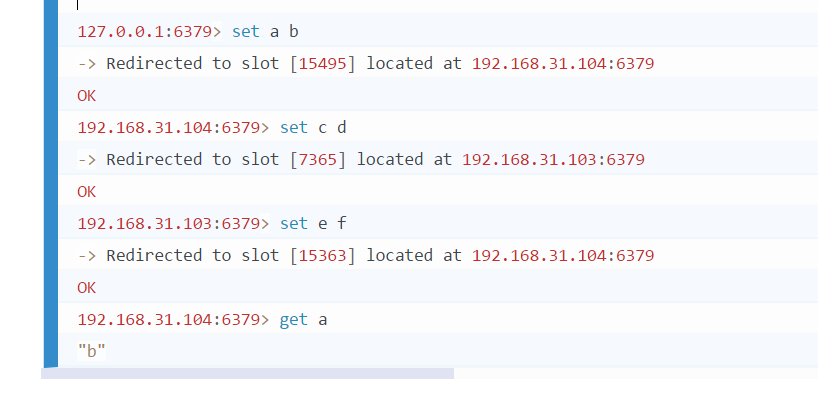
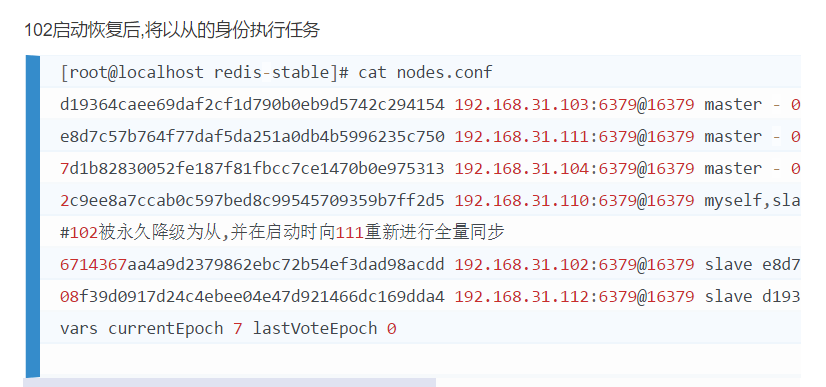
主节点挂掉的情况

主节点恢复变更为从节点
【062】缓存一致性如何保障?先写库还是先写缓存?聊聊 Cache Aside Pattern 与延迟双删
来源:https://www.bilibili.com/video/BV1aF411e7ur?spm_id_from=333.999.0.0
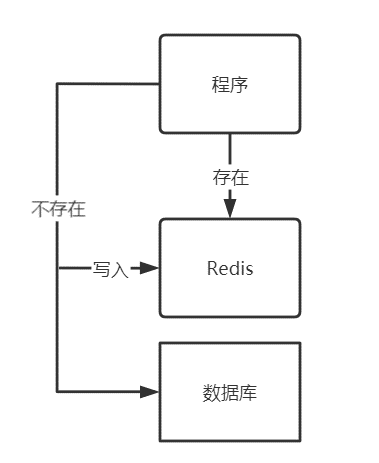
为什么不能直接更新缓存
正常情况下的 Redis 使用方法

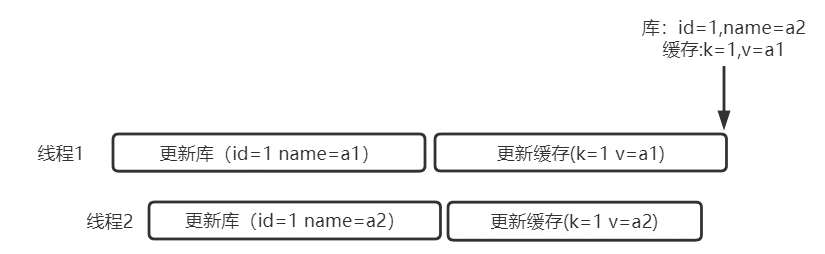
更新缓存高并发情况会遇到的问题
Cache Aside Pattern 到底说了什么
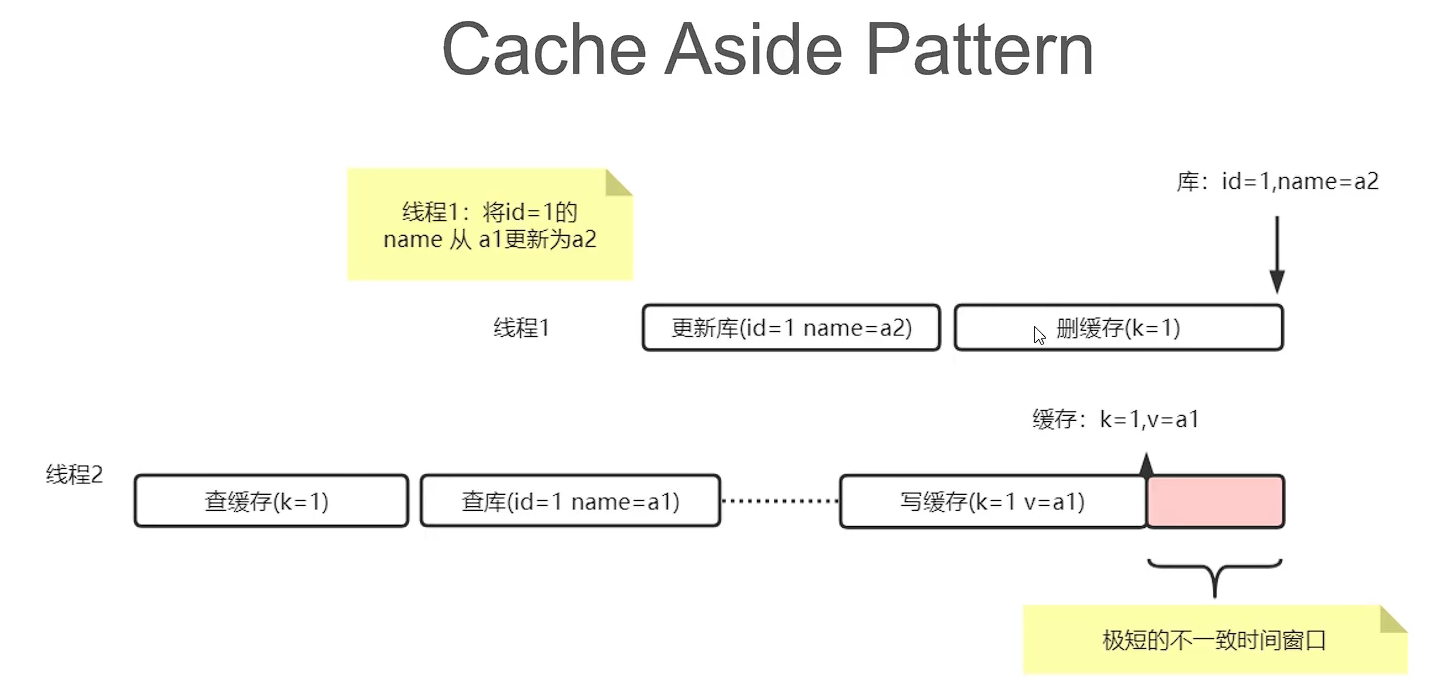
Cache Aside Pattern 是经典的缓存一致性处理模式
本质是“先写库,再删缓存”
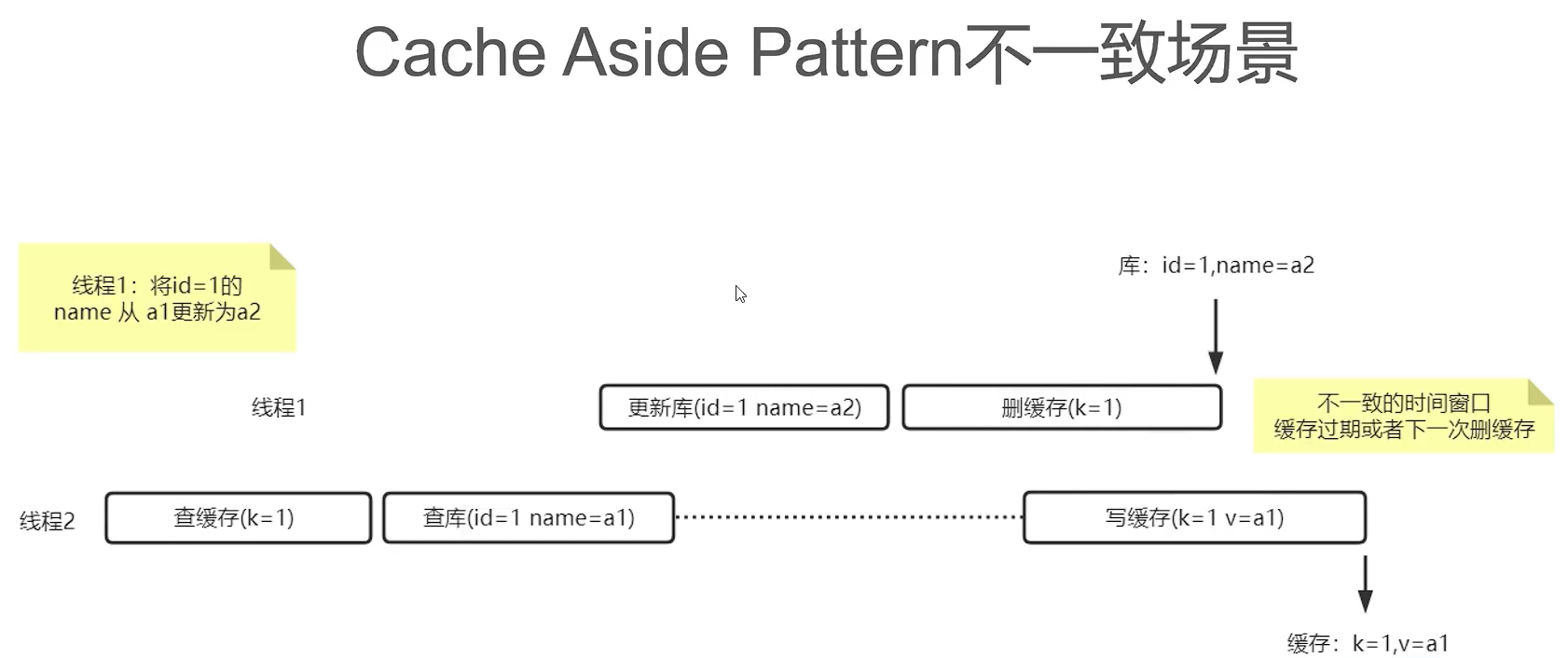
为什么不是“先删缓存,再写库”
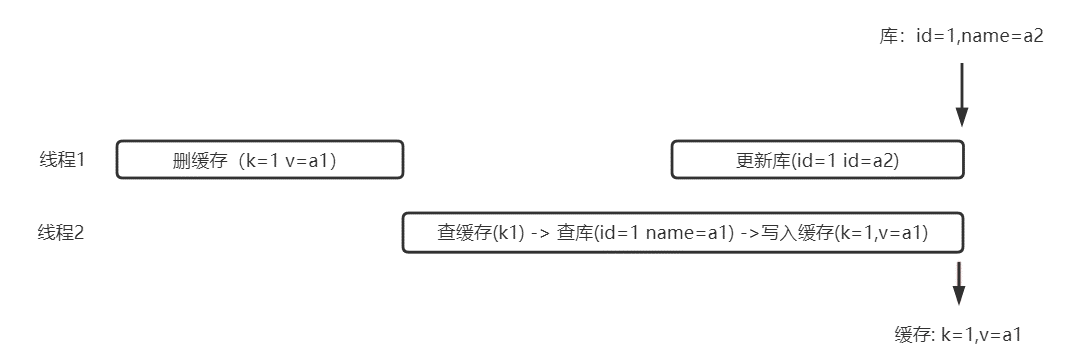
Cache Aside Pattern
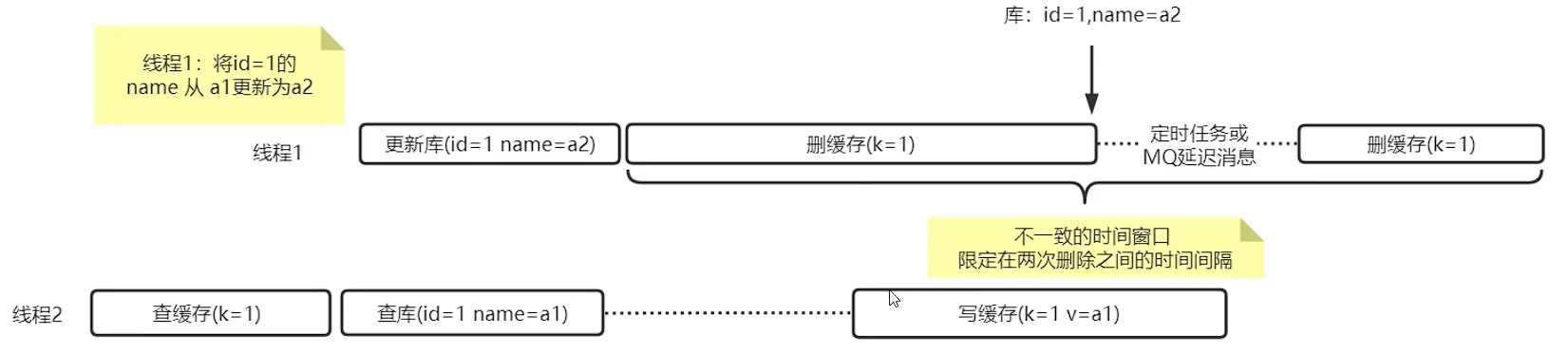
延迟双删解决极端场景数据不一致
【068】高并发电商热门商品缓存访问倾斜,该怎么解决?
来源:https://www.bilibili.com/video/BV19Q4y1S7k1?spm_id_from=333.999.0.0
正常情况的缓存
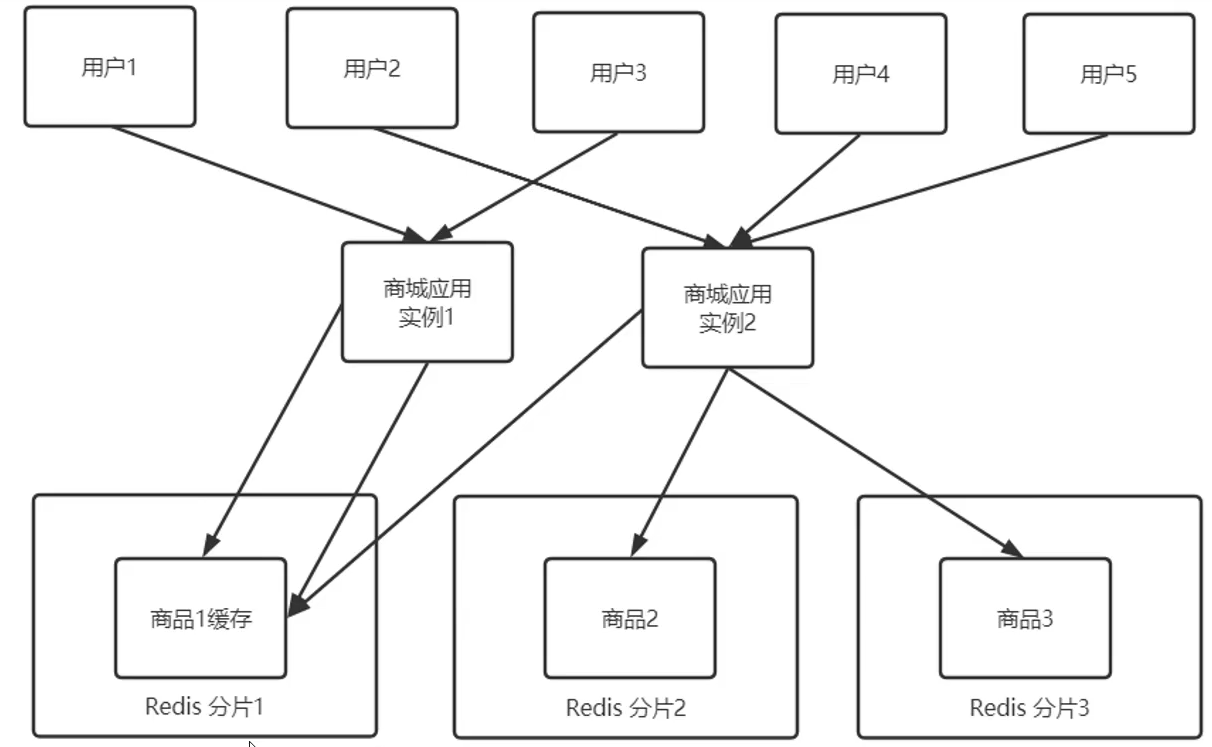
但是遇到热门的商品,比如苹果手机发布会之后,苹果手机的商品数据就会被大量访问,这时候就会发生热门商品缓存访问倾斜。
热门数据分片
热点数据特征:短时访问超高,数据总量相对较少
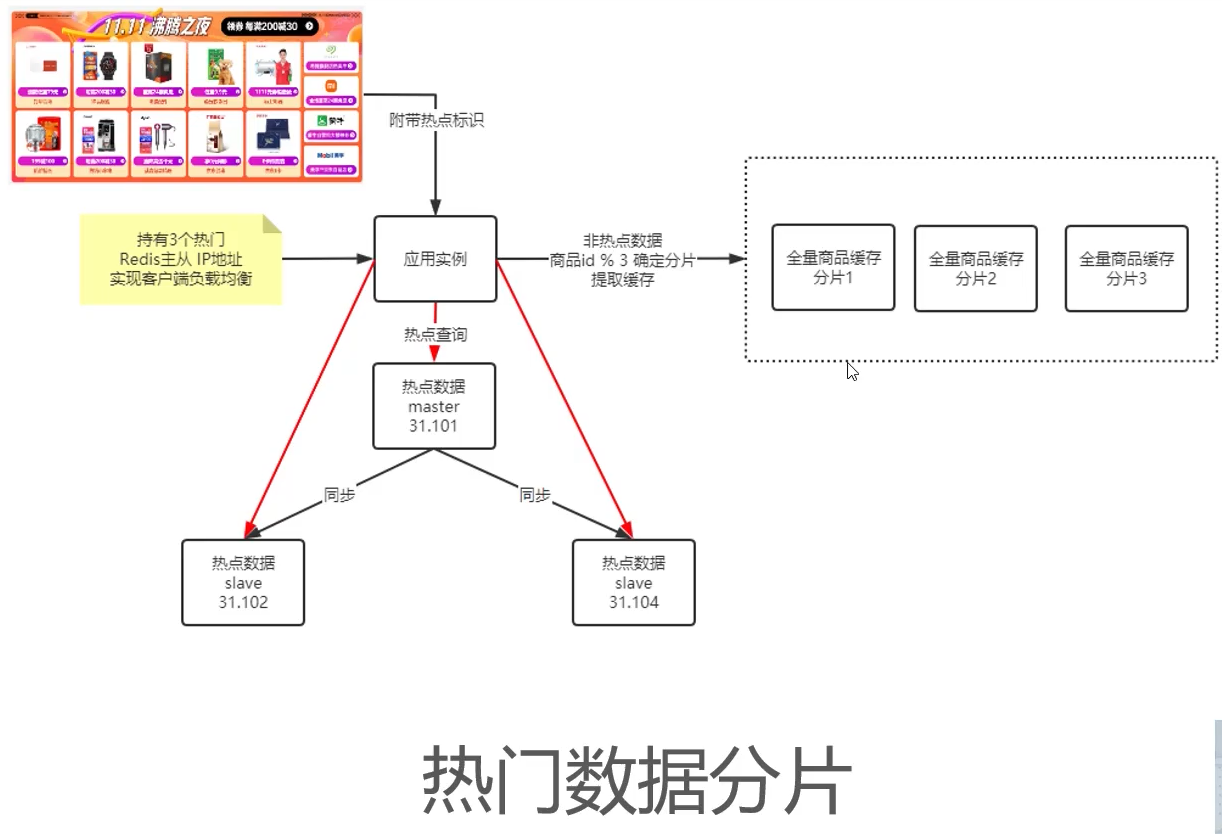
如何区分热点数据?
美团:默认大促时参与活动的商品
京东:用户行为分析与大数据评估
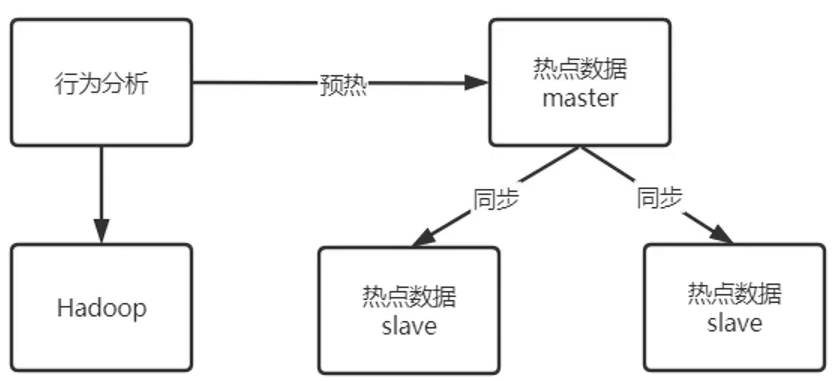
缓存前置+闪电缓存
