- 来源
- 【002】-MySQL 集群模式与应用场景
- 【003】-为什么大厂要做数据垂直分表?
- 【012】阿里开发规范解读:为啥禁用外键约束?
- 【022】阿里开发规范解读,为啥禁止三表 Join 关联?
- 【023】阿里开发规范解读,存储过程:阿里我 tmd 谢谢你啊!
- 【036】阿里开发规范解读,小心 MySQL 索引选择性陷阱
- 【016】七张图讲明白 MySQL 高可用 MHA 架构方案
- 【021】京东金融是如何通过乐观锁解决并发数据冲突的?
- 【026】公共表在分布式架构下该如何访问?
- 【029】面试官:MySQL 脏读、幻读、不可重复读你能分清吗?
- 【030】这可能是最直白的 MySQL MVCC 机制讲解啦!
- 【007】-为什么大厂在大表做水平分表时严禁使用自增主键
- 【040】面试官:为什么表的主键要使用代理主键(自增编号),不建议使用自然主键?
- 【047】避坑分享,财Z部金财平台用主键用了 UUID 后,我们都疯了!
- 【050】CPU、内存、硬盘三大件,MySQL 服务器该如何选择?
- 【055】MySQL 模糊查询还在用like?Mysql Ngram 全文检索技术快速上手
来源
课件地址:https://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/it300/download/ppt_all_in_one.zip
【002】-MySQL 集群模式与应用场景
来源:https://www.bilibili.com/video/BV1gP4y1t7DH?spm_id_from=333.999.0.0
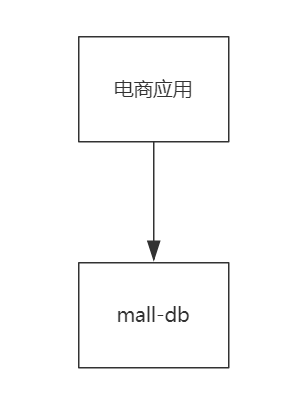
单库模式
单库模式:一个 mysql 数据库承载所有相关数据。
优缺点:
● 简单粗暴
● 适合数据量千万以下小型应用
● 企业网站,创业公司首选
● 不具备可用性与并发性
集群模式
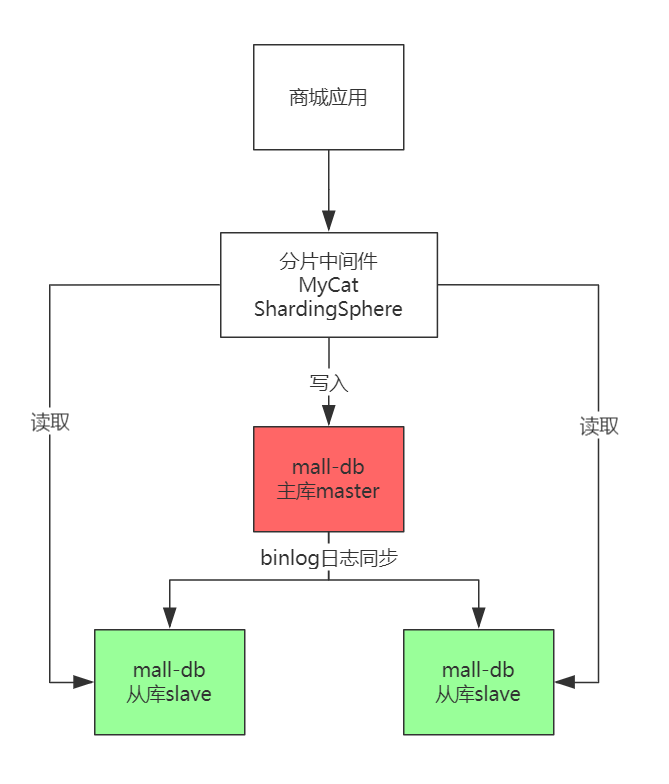
读写分离集群模式
读写分离集群模式:在原有的基础上增加中间层,与后端数据集构成读写分离的集群。
整体基础结构:原有的主库派生出子库 1,子库 2。
利用 mysql 原有的主从同步机制(即为:binlog 日志同步),将主库的数据变化在从库中复现,保证数据同步。主库一般用于写入处理,从库负责读取。
细节:如果直接面对主库进行操作无法完成读写分离,需要在前端分配分片中间件(阿里 mycat,京东ShardingSphere),该中间件通过 curd 请求,来决定由哪个库处理。MHA 中间件实现高可用(即:主服务器坏了,MHA 中间件可以将某个从表提升为主服务器)。
所有节点数据均保持同步。适用于读多写少,单表不过千万的互联网应用。
缺点:
● 架构复杂度提升,成本提高
● 所有节点数据均保持同步
● 适用于读多写少,单表不过千万的互联网应用
● 配合 MHA 中间件方案实现高可用性
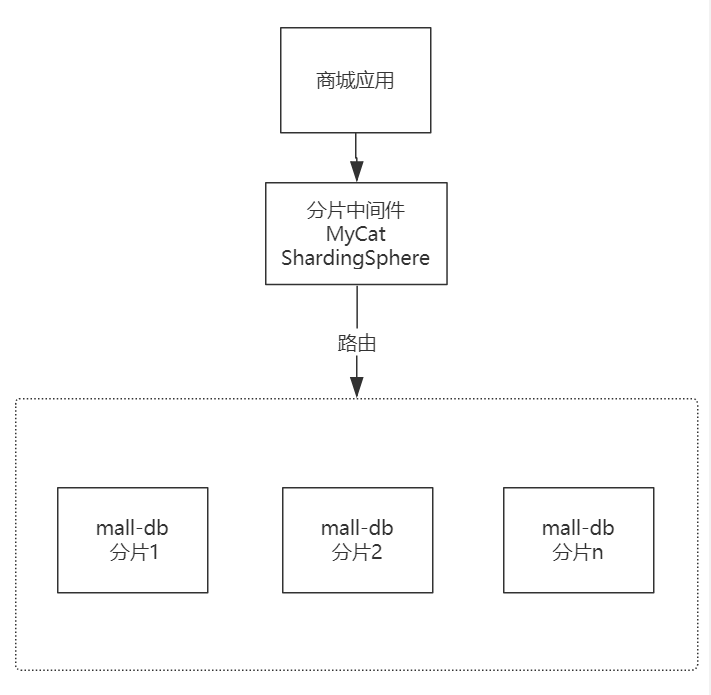
分库分表(分片)集群模式
分库分表(分片)集群模式:一个 mysql 数据库撑不住的情况下。将数据库的数据分到不同的节点数据库(即:节点数据库的数据合起来为完整的数据体)。
需要用到中间件进行路由。(对 sql 进行解析,将请求发到对应的数据库,分发请求的过程叫路由)。不具备高可用性。
特点:
● 架构复杂度提升,成本提高
● 每个节点数据是所有数据的子集
● 适用于十亿级数据总量大型应用
● 不具备高可用特性
分片算法
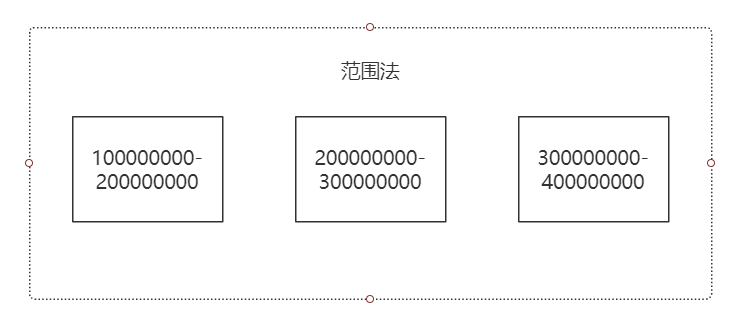
范围法
对主键(即为分片键进行划分。如 id),mysql 默认提供的特性(分区表为典型的范围法),易扩展,适用范围检索,但数据不均匀,局部负载大,适用流水账应用。
特点:
● 范围法结构简单,扩展容易
● 适合范围检索
● 数据分布不均匀,局部负载压力大
● 适用于流水账应用
HASH 法
对 id 取模。取模和一致性 Hash(独特的环形算法)。数据分布均匀。扩展复杂,数据迁移大。建议提前部署。
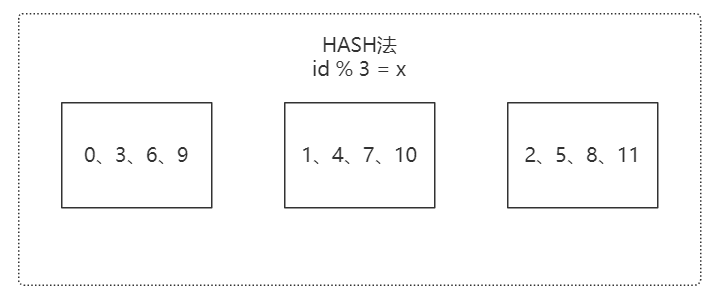
特点:
● Hash 法分为取模与一致性 Hash
● 数据分配均衡
● 节点扩展复杂,数据迁移难度大
● 建议提前部署足够的节点
● 适用于预算充足的大型互联网应用
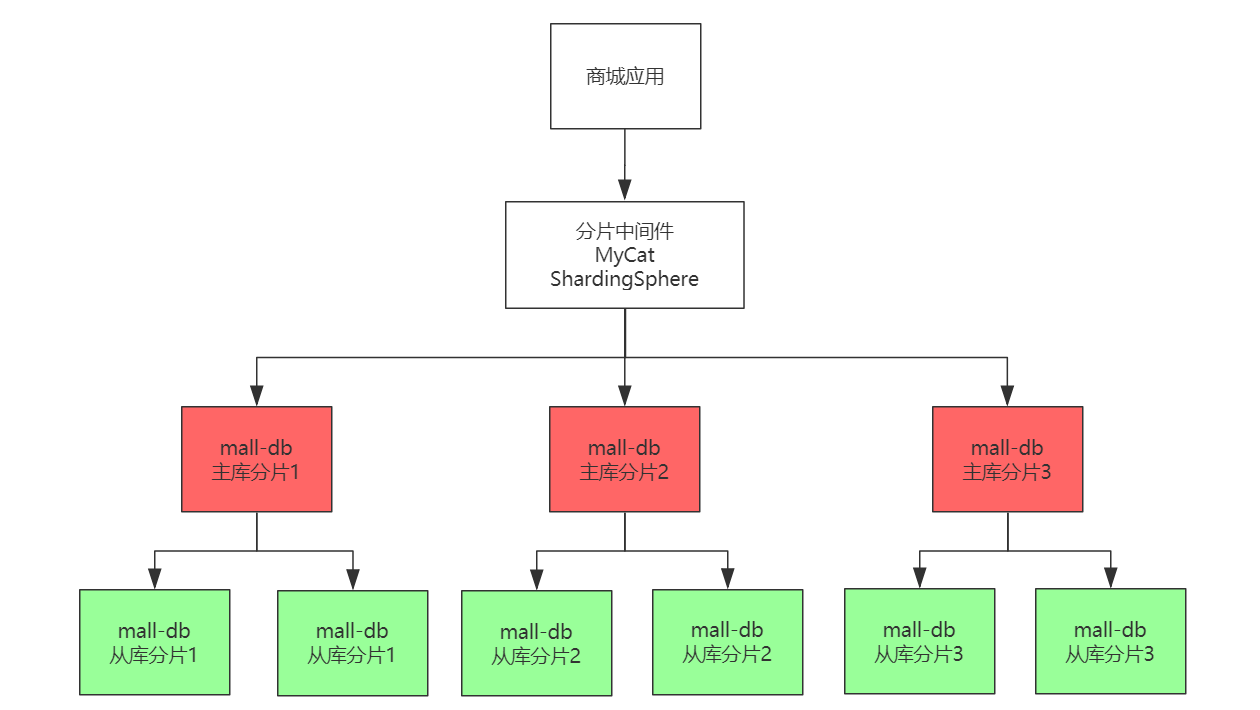
互联网主流 MySQL 集群架构
读写分离和分片的组合运用
【003】-为什么大厂要做数据垂直分表?
来源:https://www.bilibili.com/video/BV1v44y117K9?spm_id_from=333.999.0.0
一张表的字段太多需要做垂直分表。
水平分表
什么是水平分表?
以行为单位对数据进行拆分(范围法,hash 法)。
特点:所有的表结构完全相同。用于解决数据量大的存储问题。
范围法
HASH 法
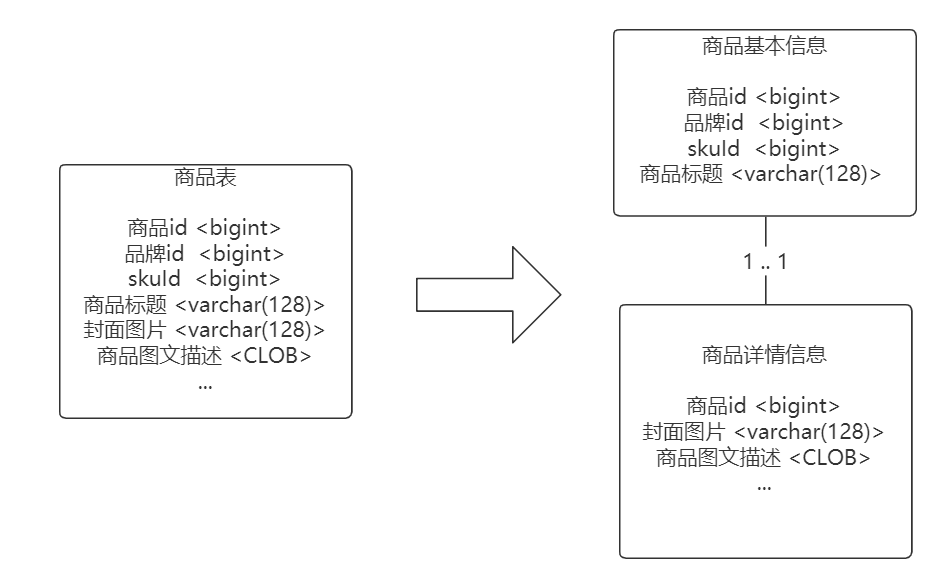
什么是垂直分表?
而垂直分表则是代表将一张大表按“列”拆分为 2 张以上的小表,通过主外键关联来获取数据。
#调整前SELECT * FROM 商品表 WHERE 商品标题='AD钙奶';#调整后SELECT * FROM 商品基本信息表 a,商品详情表 b WHERE a.商品id=b.商品id and a.商品标题='AD钙奶';
垂直分表有哪些依据?
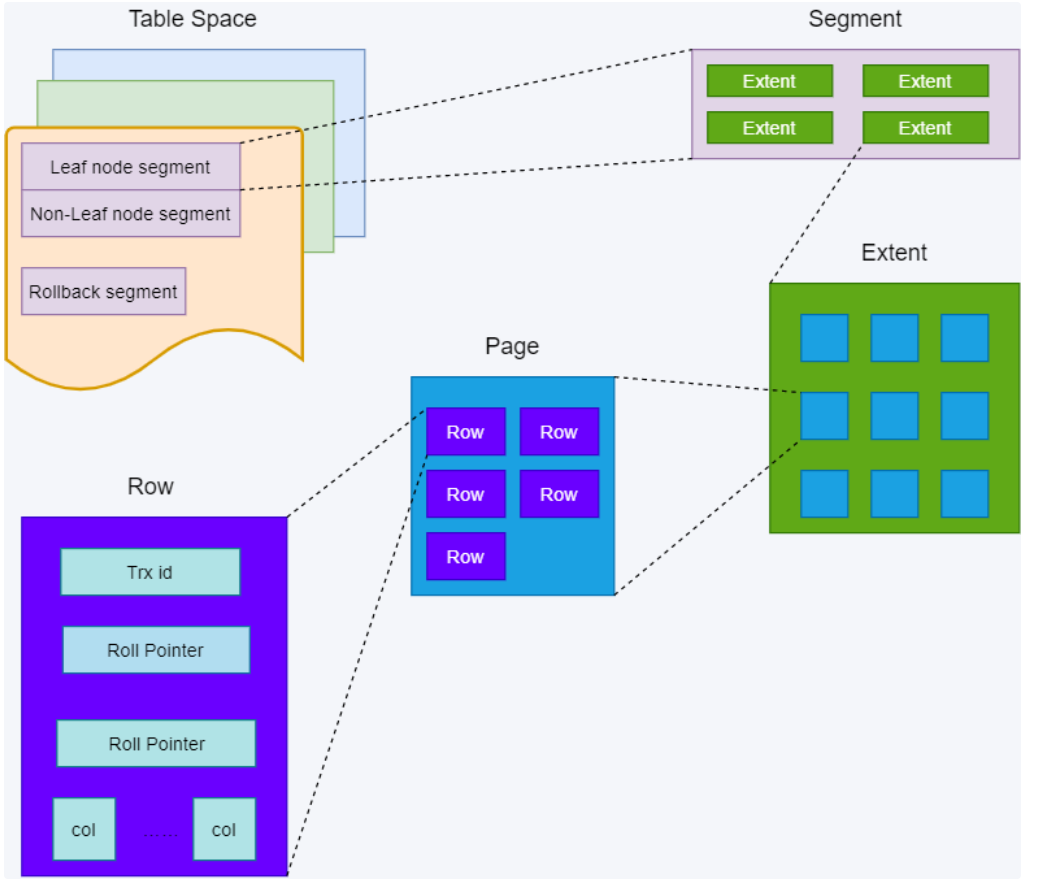
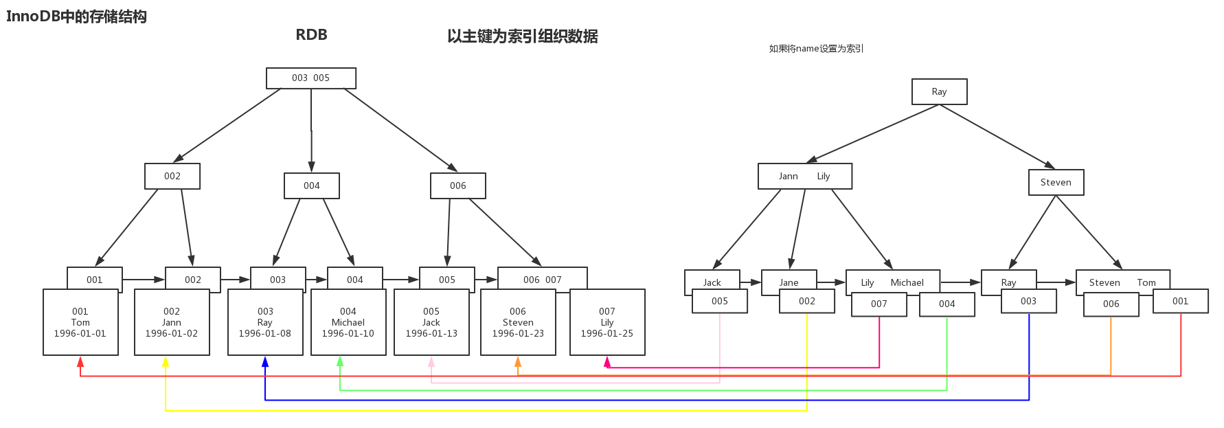
需要了解 mysql 的 InnoDB 处理引擎。
行数据称为:row
管理数据基本单位称为页:page;每一页的默认大小:16k
保存页的单位称为区:Extent。
关系:区由连续页组成,页由连续行组成。1024/16=64(即:一个 1M 的区有 64 个页)
InnoDB1.0 后新特性,压缩页。
压缩页:对数据底层进行压缩,使实际大小小于逻辑大小。
在跨页检索数据的过程中,压缩和解压缩的效率低。在表设计时,尽可能在页内多存储行数据,减少跨页检索,增加页内检索。
分析:
1 行数据为 1K,1 页 16K,即 1 页 16 条数据,1 亿的数据需要 625 万页
垂直分页后,1 行数据为 64 字节(1K = 1024 字节),即 1 页 256 条数据,1 亿的数据需要 39 万页。分页后的数据根据 id 等关系进行快速提取。
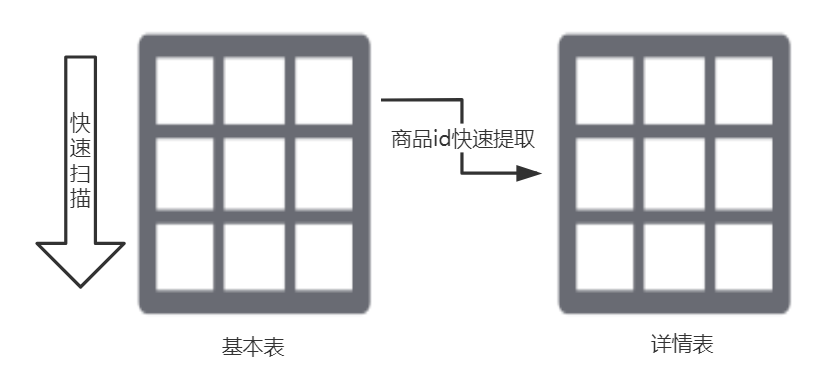
通过将重要字段单独剥离成小表,让每页容纳更多行数据,页减少后,缩小数据扫描范围,达到提高执行效率的目的。
垂直分表的条件:
● 单表数据量未来可能千万
● 字段超过 20 个,且包含了超长的 Varchar、CLOB、BLOB 等字段
哪些字段放在小表中:
● 数据查询、排序时需要的字段,如分类编号、商户 id、品牌编号、逻辑删除标志位等
● 高频访问的小字段,如商品名称、子标题、价格、厂商基本等
哪些字段放在大表中:
● 低频访问字段:配送信息、售后声明、最后更新时间等
● 大字段:商品图文详情、图片 BLOB、JSON 元数据等
【012】阿里开发规范解读:为啥禁用外键约束?
来源:https://www.bilibili.com/video/BV1pf4y1V7VL?spm_id_from=333.999.0.0
【阿里JAVA规范】不得使用外键与级联,一切外键概念必须在应用层解决。
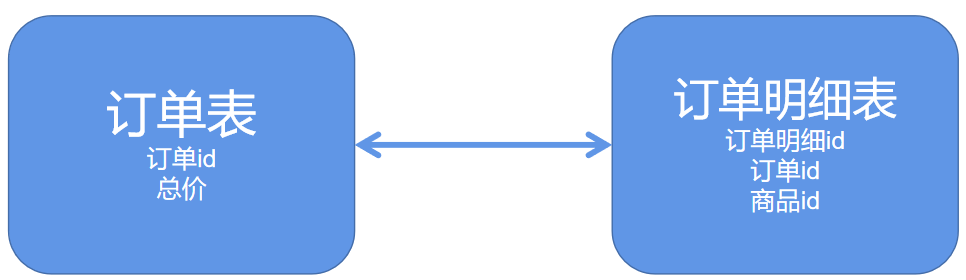
缺点:每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便。
优点:
● 保证数据的完整性和一致性
● 级联操作方便
● 数据一致性交给数据库,代码量小
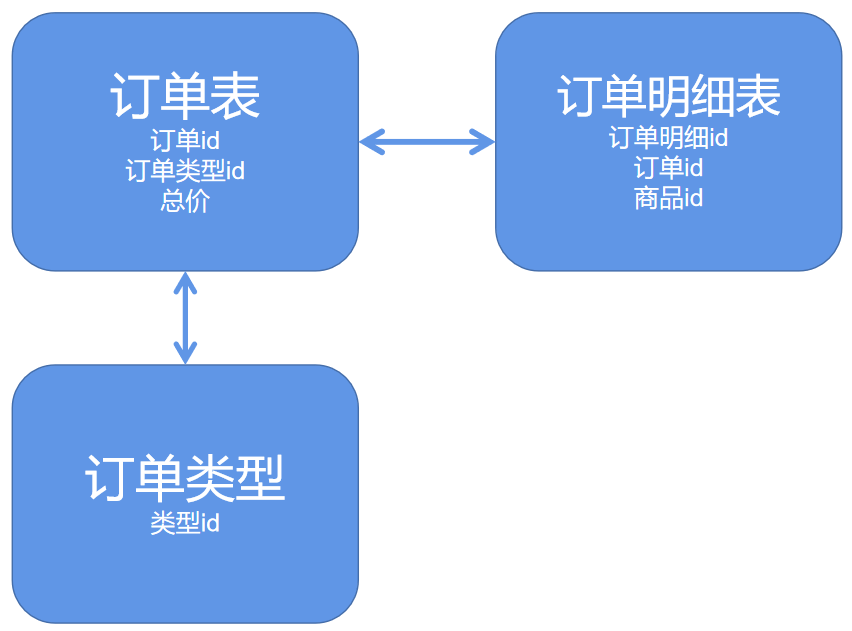
外键约束对数据库的影响:
1.性能问题
● 额外的数据一致性校验查询(往订单明细表添加一条数据,会强制查询对应订单表中的订单 id 是否存在。)
2.并发问题
● 外界约束会启用行级锁(并发环境下,往订单明细表添加一条数据,会强制查询对应订单表中的订单 id 是否存在,所以订单表开启共享锁(共享锁【S 锁】,又称为读锁,可以查看但无法修改和删除的一种数据锁))
● 主表写入时会进入阻塞(某种情况下对订单 id 进行更新操作,这时该数据开启排它锁(排他锁【X 锁】,又称写锁)。若写锁不被释放,订单明细表处于被锁定的状态。会造成线层积压,系统崩溃)
3.级联删除问题
● 多层级联删除会让数据变得不可控
● 触发器也严格被禁用
4.数据耦合
● 数据库层面数据关系产生耦合
● 数据迁移维护困难(场景:订单明细表数据增长,数据量 10 亿后,需要迁移到 Hbase。这时数据不在同一个库,没有了主外键约束,代码上无校验,就会产生数据一致性问题。)
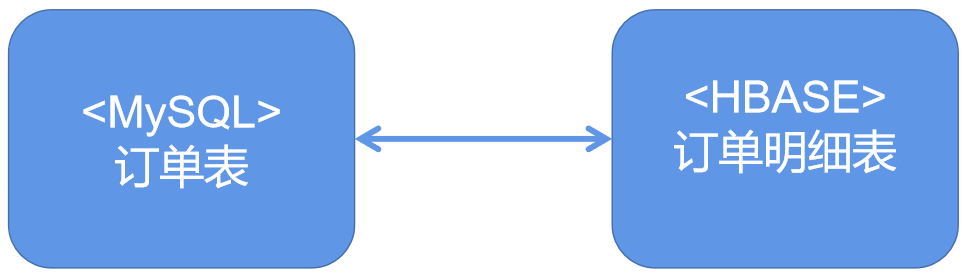
【022】阿里开发规范解读,为啥禁止三表 Join 关联?
来源:https://www.bilibili.com/video/BV1GA411A7gJ/?spm_id_from=333.788.recommend_more_video.0
【强制】 超过三个表禁止 join。
需要 join 的字段,数据类型必须绝对一致;多表关联查询时,保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。
为什么禁用多表关联
1.产品强制要求
● 阿里 OceanBase 只允许 2 表关联
● MyCat 只支持 2 表关联
● ShardingSphere 在中小企业需要分库分表的时候用的会比较多,因为它维护成本低,不需要额外增派人手;而且目前社区也还一直在开发和维护,还算是比较活跃。
2.MySql 自身的设计缺陷
● 超过 3 表关联时 MySql 优化器做得不好
● NLJ 多级嵌套性能差
数据量大,join 临时表会很大,性能差
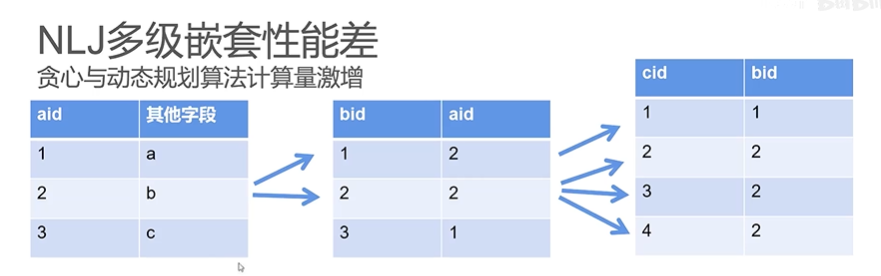
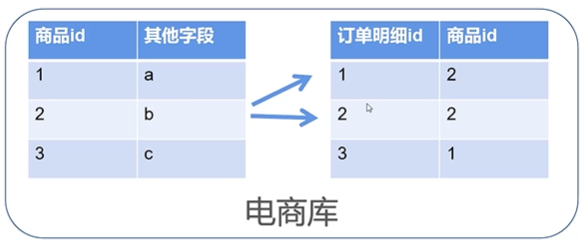
如果数据量大,出现跨库
数据量大时,分表分库分服务,无法继续 join
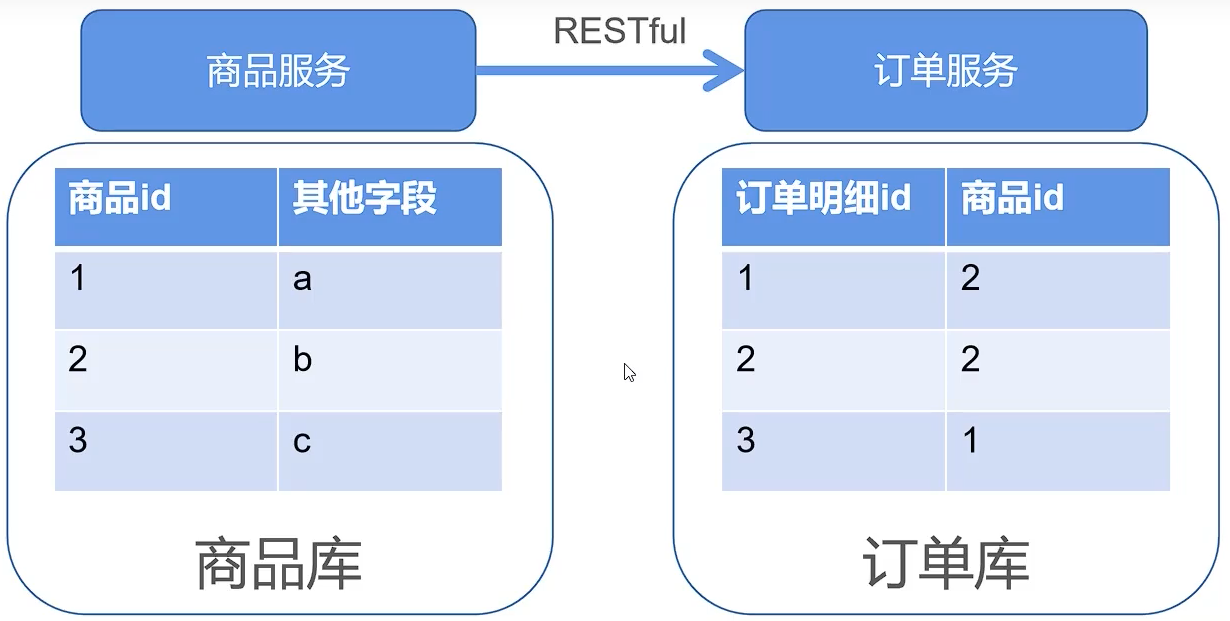
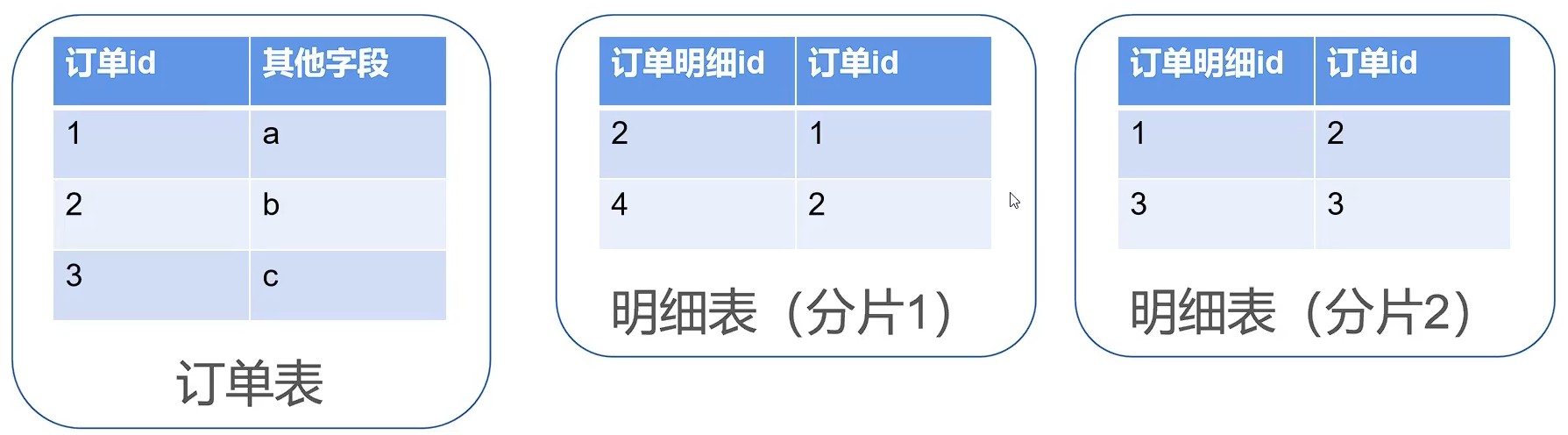
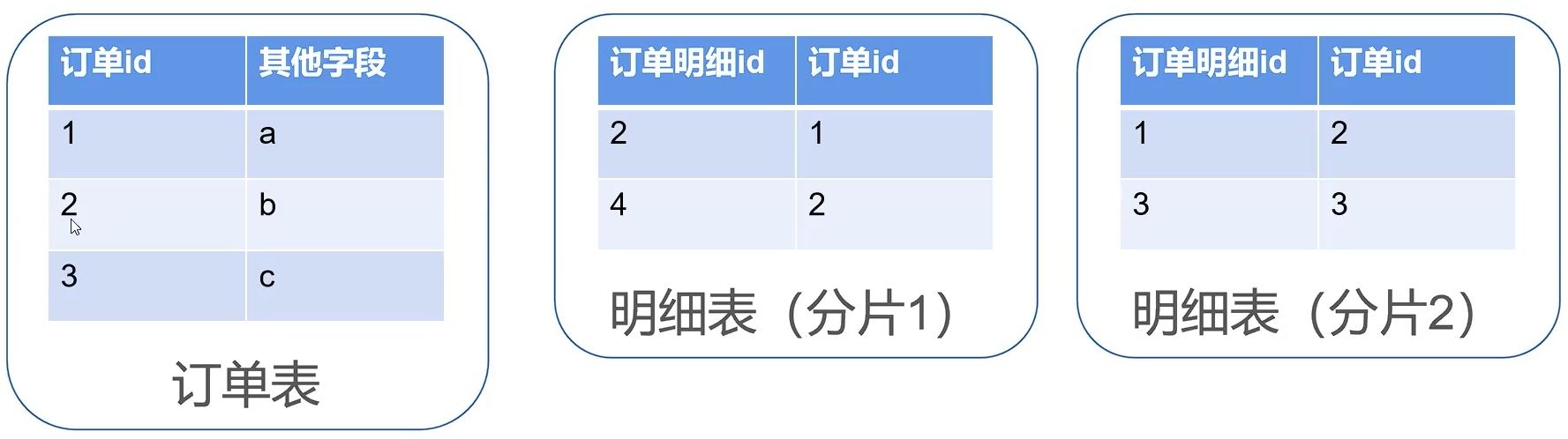
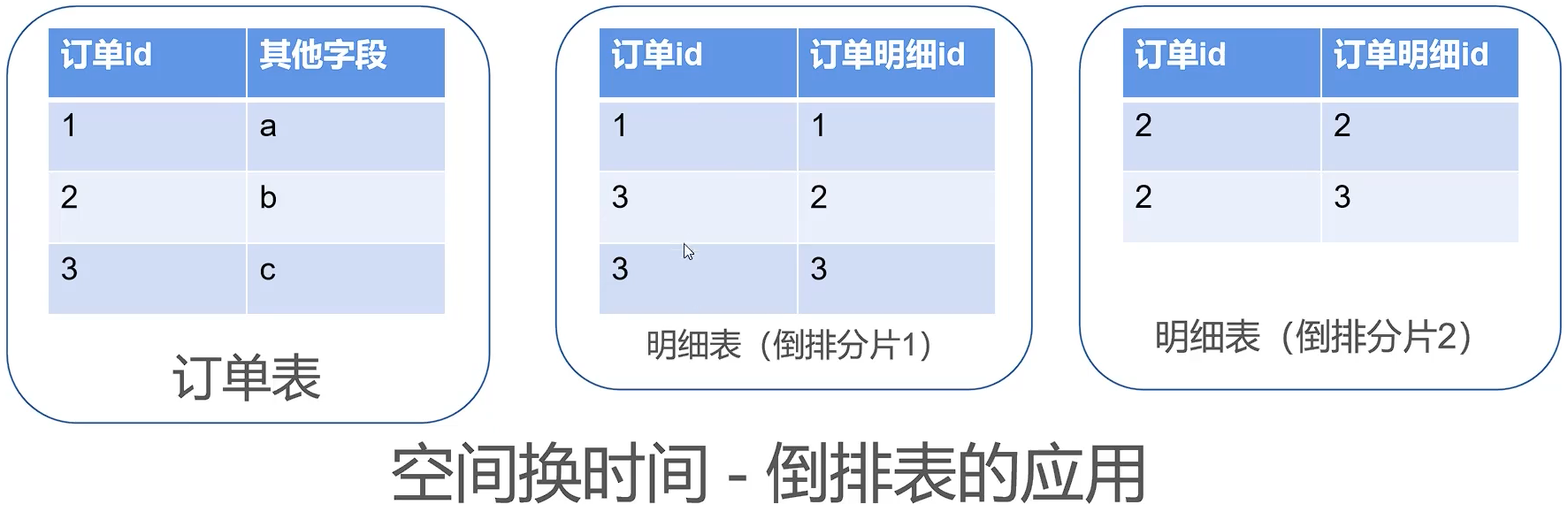
出现多表关联后的解决方案
1.拆成多条 SQL
临时解决方案,适用于数据量小,只适用于 inner join

2.形成一个具有多表信息的冗余表
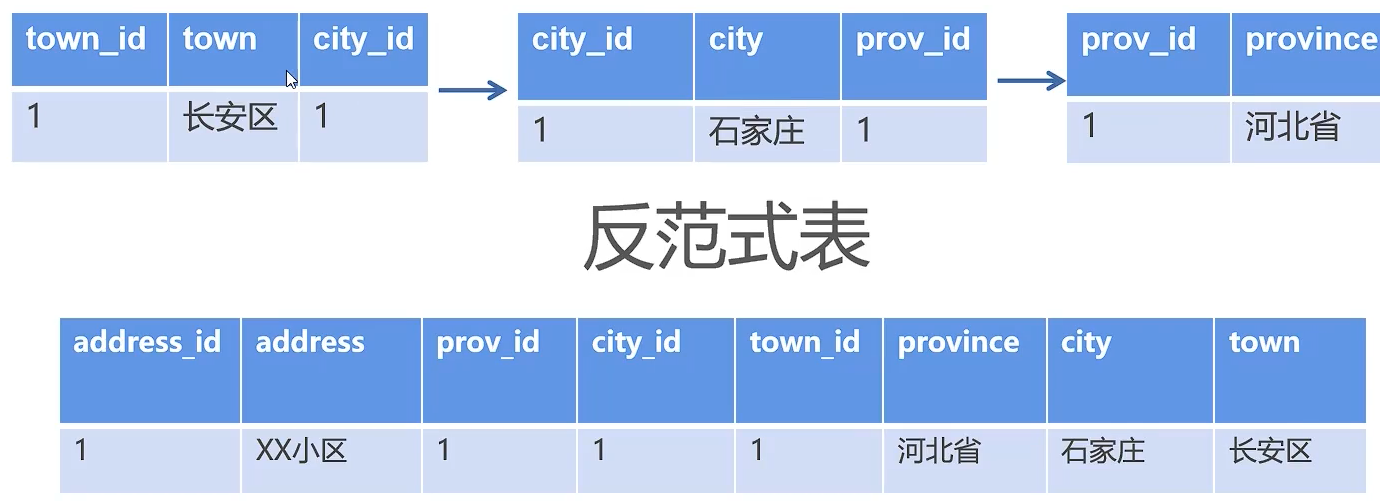
3.定时对多个表进行数据清洗,形成一个涉及多个表重点数据的冗余表。
【023】阿里开发规范解读,存储过程:阿里我 tmd 谢谢你啊!
来源:https://www.bilibili.com/video/BV1FL4y1v7q9/?spm_id_from=333.788.recommend_more_video.-1
- [ 强制]禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
非必要不用存储过程,但个别情况,存储过程还是有好处的,比如减少了 db 交互,部署方便,以前我们产品中有些复杂报表就是存储过程实现的。这个阿里的严禁,只是因为分布式数据库,分库分表,缓存策略等,存储过程已经完全不适用。
1.为什么银行都在用存储过程
● 银行业务以数据为核心
● Oracle、DB2 一统江湖,存储过程与语言无关
● 预算充足,好多个W采购小型机满足性能要求
● 存储过程几乎是每一个信息科技处开发员工的入职要求
● 银行被 Oracle、DB2绑架
● 数据好迁移,存储过程要全部重写
● 谁来/谁敢承担核心业务的风险?
2.存储过程为什么成为互联网弃子
大人!时(shi)代(da)变(bian)了
来自某乎的阿里大佬评论

存储过程在互联网分布式场景的问题
● 分片场景下存储过程只能作用在局部数据
● 数据库压力激增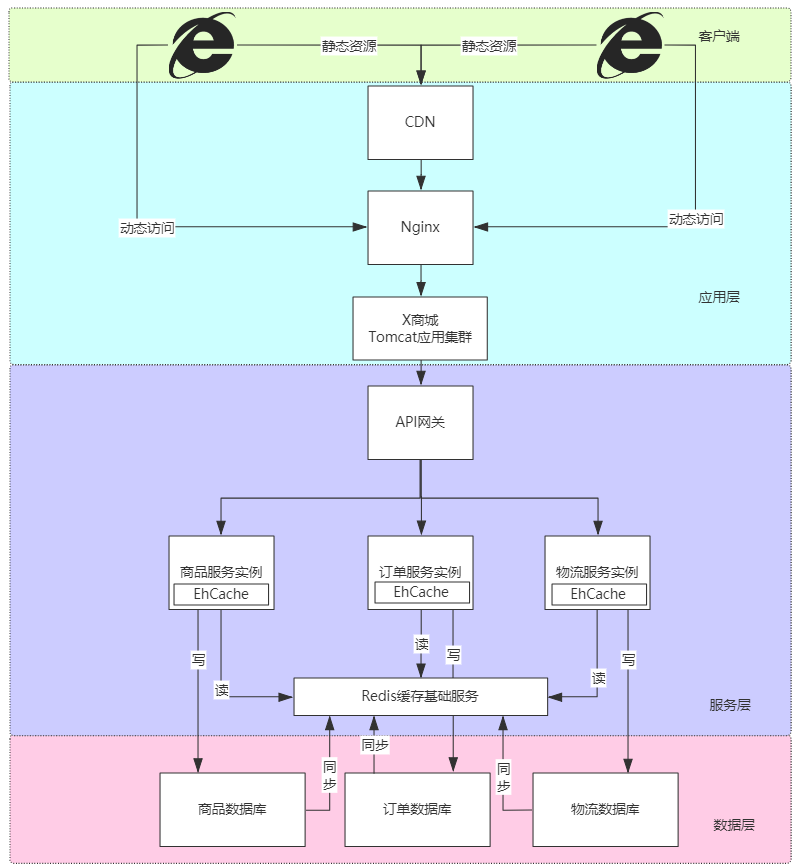
● 无法保证分布式全局事务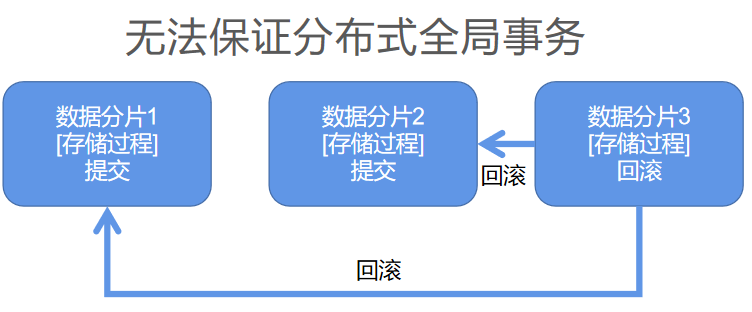
● 存储过程难以调试,没有内置的版本管理方案
● 业务执行碎片化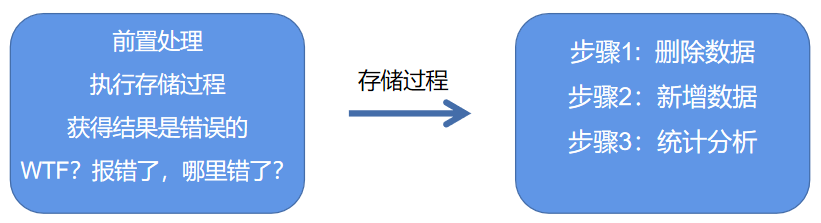
【036】阿里开发规范解读,小心 MySQL 索引选择性陷阱
来源:https://www.bilibili.com/video/BV1xv411P7BY?spm_id_from=333.999.0.0
4.【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明∶索引文件具有 B+Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
什么是索引选择性陷阱?
电竞选手表
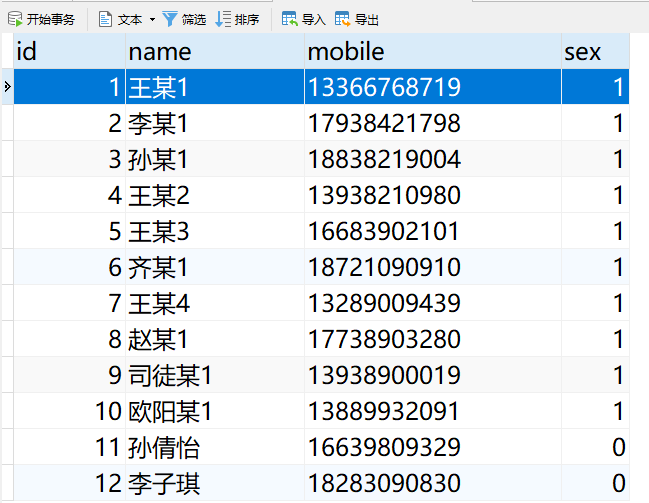
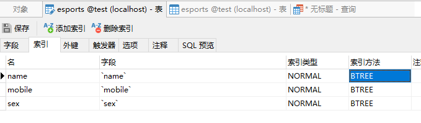
● 头匹配命中索引

● 尾匹配与任意匹配全表扫描

● 索引选择性太差导致全表扫描的案例


不严谨解释
命中的索引值超过总量 25%
就可能产生索引选择性陷阱
导致全表扫描
PS:一切以 Explain 执行计划为准
常见案例
● 在业务表只查询逻辑删 =0 数据
select * from t where is_delete = 0 或 1
● 查询格力集团月薪 <=5 万的人员工资
● 医院护士表查询性别 = 女的工作人员
索引选择性陷阱如何解决?
索引选择性差解决办法
● 强制使用索引(有时会有奇效,以实际运行效果为准)
explain select * from question force index(answer) where answer = 'A'
● 增加缓存,提高全表扫描速度(钞能力)
innodb_buffer_pool_size=16Ginnodb_buffer_pool_instances=2
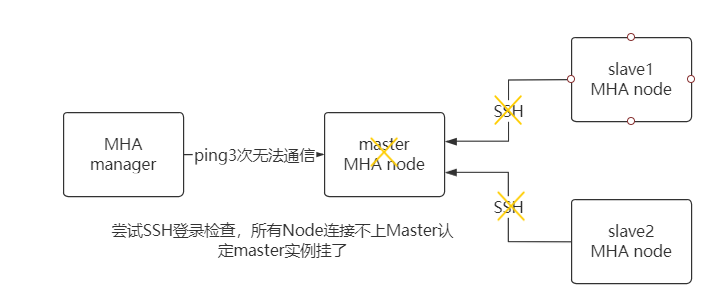
【016】七张图讲明白 MySQL 高可用 MHA 架构方案
来源:https://www.bilibili.com/video/BV1dP4y1W72s?spm_id_from=333.999.0.0
MHA 是小日子过得还不错的霓虹国程序员 yoshinorim 开发的 MySQL 高可用方案
采用 Perl 语言开发
MHA 是最成熟 MySQL 高可用方案
兼容性好不挑食是 MHA 的优势,很多5年以上的老应用使用旧的 MySQL 版本不支持 MGR 等新特性。但也必须考虑高可用,MHA 就是首选了。如果是新项目就别 MHA 了, 采用 MGR 全同步方案还是很棒的。
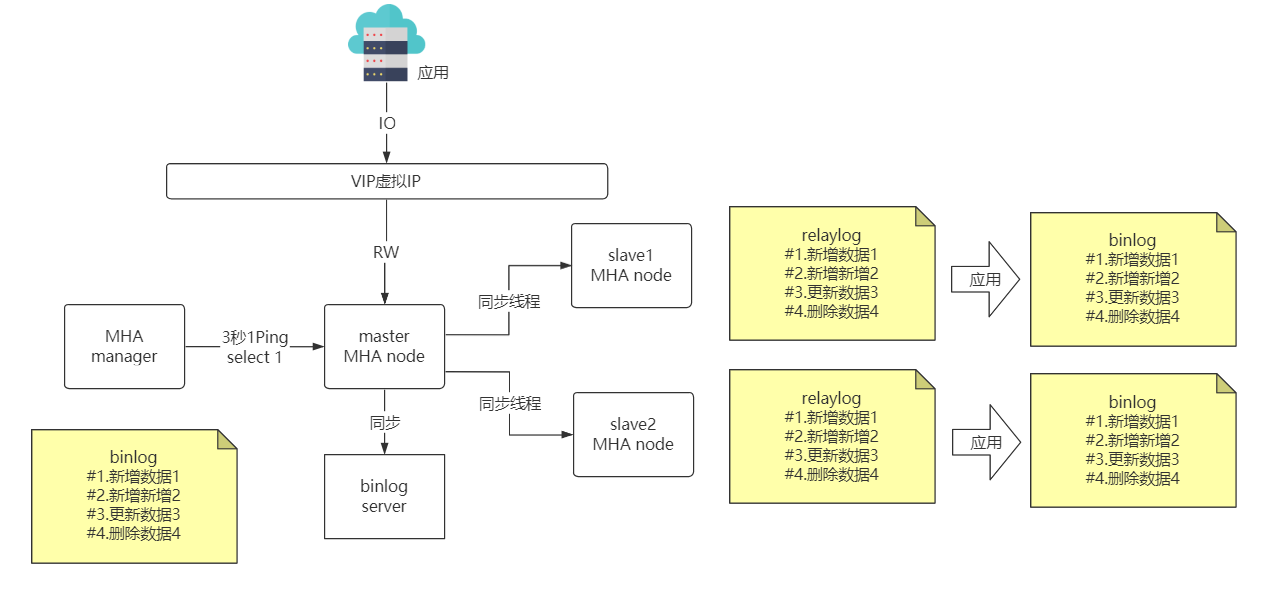

MHA 故障发现与转移过程
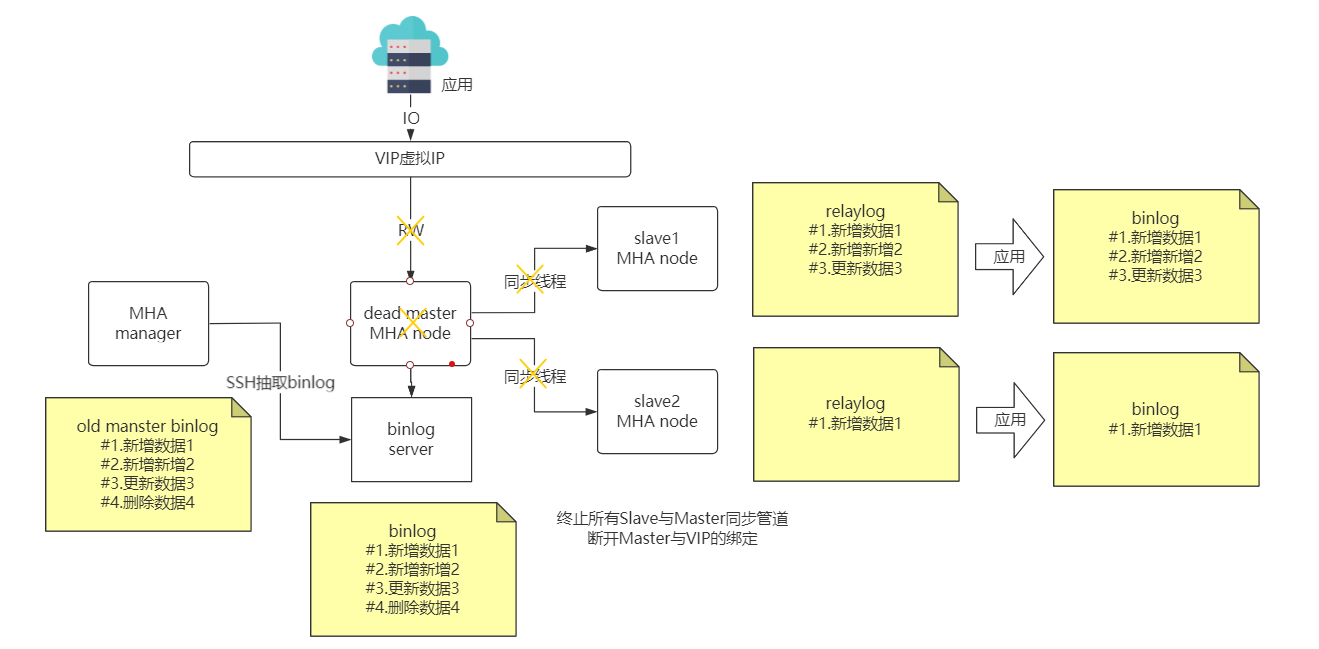
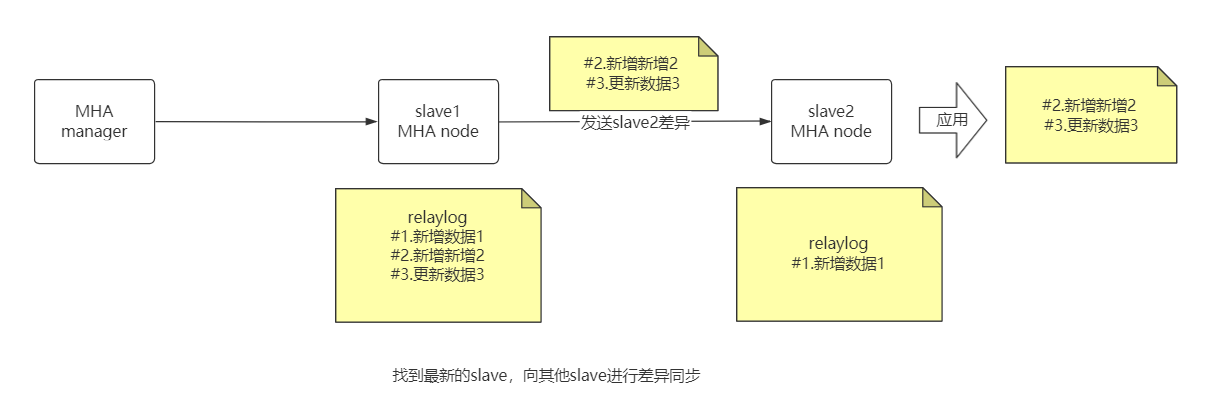
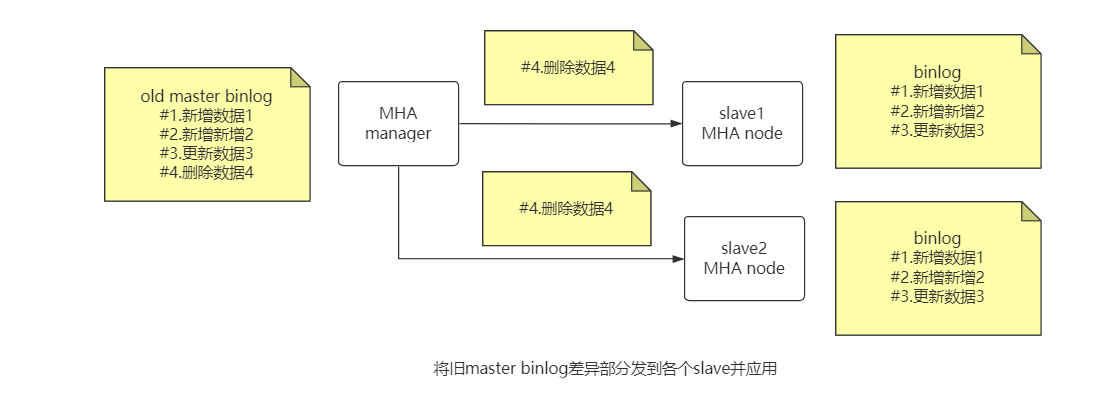
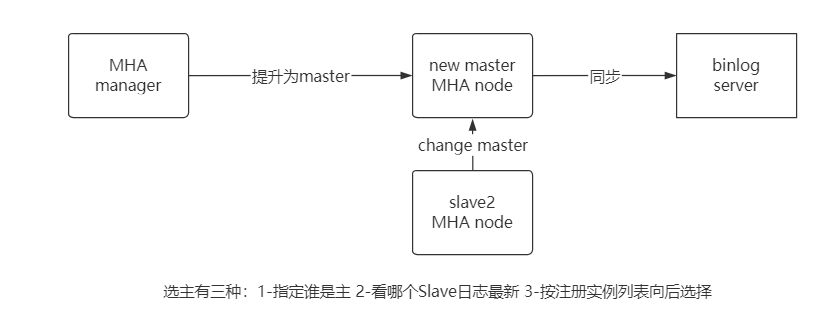
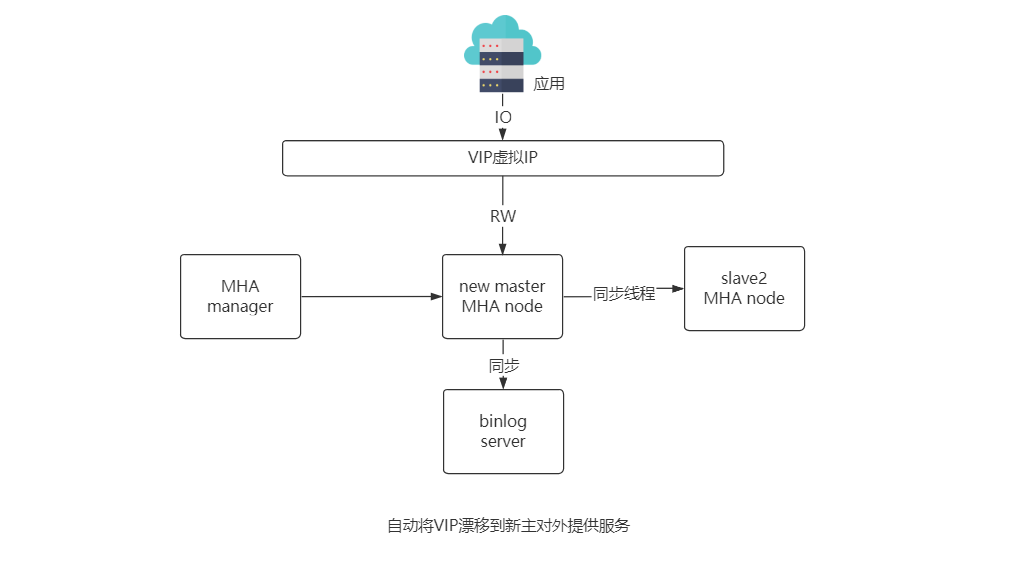
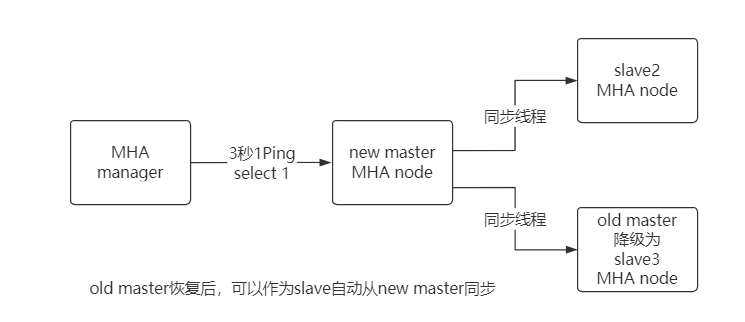
优点:
● 由 per 语言开发的开源工具
● 可以支持基于 GTID 的复制模式
● 当主 DB 不可用时,从多个从服务器中选举出来新的主 DB
● 提供了主从切换和故障转移功能,在线故障转移时不易丢失数据
● 同一个监控节点可以监控多个集群
缺点:
● 需要编写脚本或利用第三防工具来实现 VIP 的配置
● MHA 启动后只只监控主服务器是否可用,没办法监控从服务器
● 需要基于 SSH 免认证登陆配置,存在一定的安全隐患
● 没有提供从服务器的读负载均衡功能
【021】京东金融是如何通过乐观锁解决并发数据冲突的?
来源:https://www.bilibili.com/video/BV15L411b7d5/?spm_id_from=333.788.recommend_more_video.-1
为什么会产生并发冲突?

悲观锁
悲观锁并发性太差
高并发场景用户体验差

实现目标:
既要保证用户体验
也要实现数据可靠
为什么不直接 update acc set bal=bal+400 where id=1001 ?
1.有时候。需要先查。再改。
2.在高并发的情况下,容易出现数据冲突
3.计算的工作要放在代码里(在代码设计时,尽量不要把简单计算任务放在 SQL 中,假设未来数据迁移到 NoSQL,这种带计算的 SQL 就废了)
乐观锁


如果遇到冲突后该怎么办?
前端应用提示“数据正在处理,请稍后再试!”
附加 spring-retry在 service上进行方法重试
伪代码
@Transactional@Retryable(value = {VersionException.class}, maxAttempts = 3)public void updateBal(){Account acc = 执行:”select id,bal,_version from acc where id = 1001”;acc.setBal(acc.getBal() + 400);int count = 执行:“update acc set bal = ${acc.bal} , _version=_version + 1where id = 1001 and _version=${acc.version}”;if(count == 0) { throw new VersionException(“产生并发异常”) };}
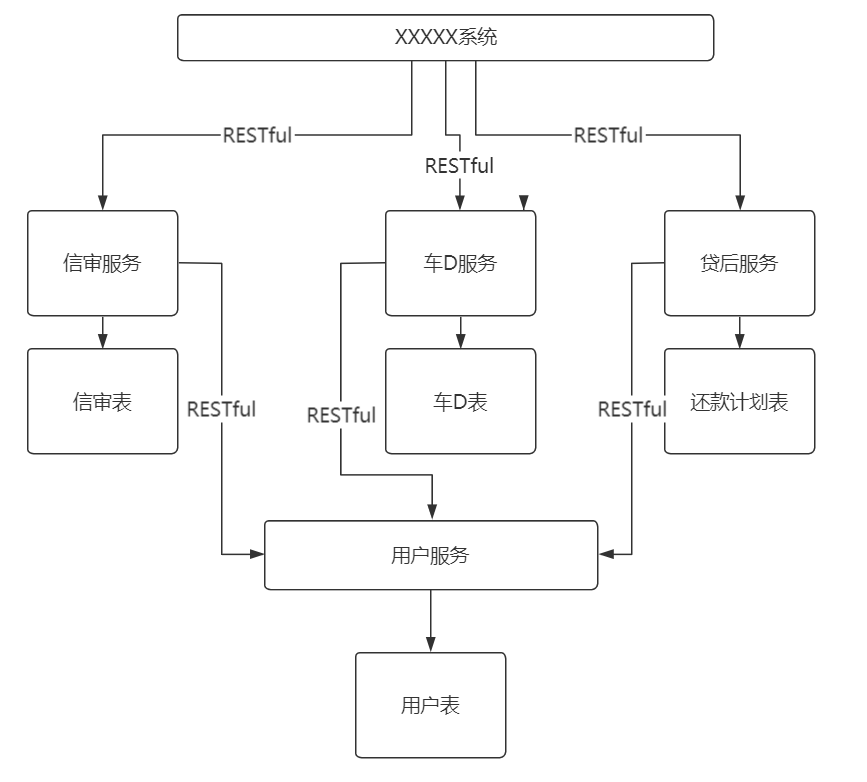
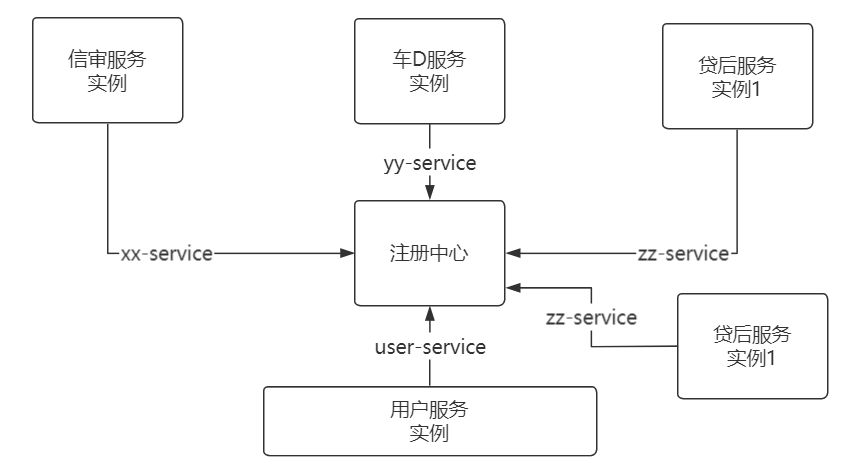
【026】公共表在分布式架构下该如何访问?
来源:https://www.bilibili.com/video/BV1wf4y1N7rF/?spm_id_from=333.788.recommend_more_video.2
什么是公共表?
被其他业务模块共享的基础数据表,被称为公共表
比如:系统用户表、行政区划、组织机构、系统配置
分布式环境下公共表会遇到哪些新问题?
假如用户表有 4000 万数据,在查询时不小心没有索引,导致磁盘 IO 直接拉满,其他表访问就会出现高延迟。
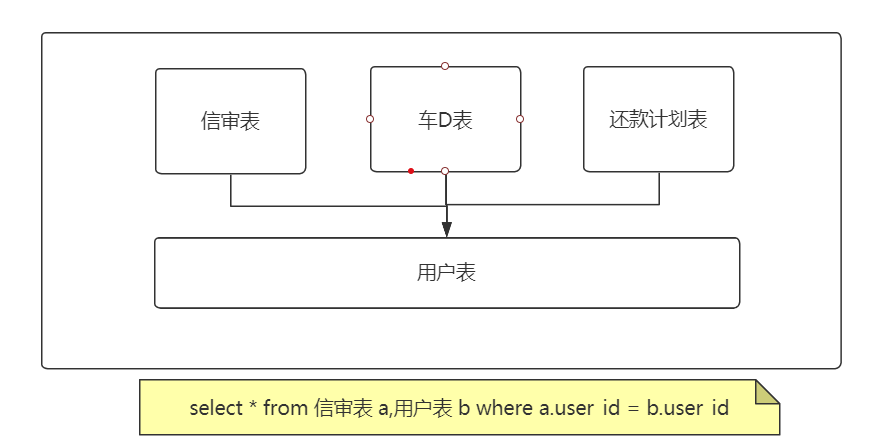
实时数据,将公共表下沉为基础服务
业务模块上浮为业务服务
业务应用通过 RPC、RESTful API 访问


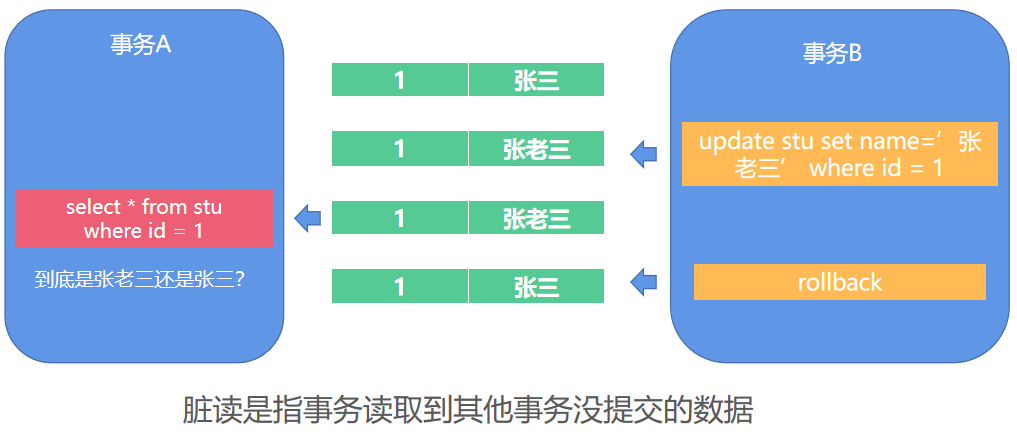
【029】面试官:MySQL 脏读、幻读、不可重复读你能分清吗?
来源:https://www.bilibili.com/video/BV1Pv411P7Fd/?spm_id_from=333.788.recommend_more_video.-1
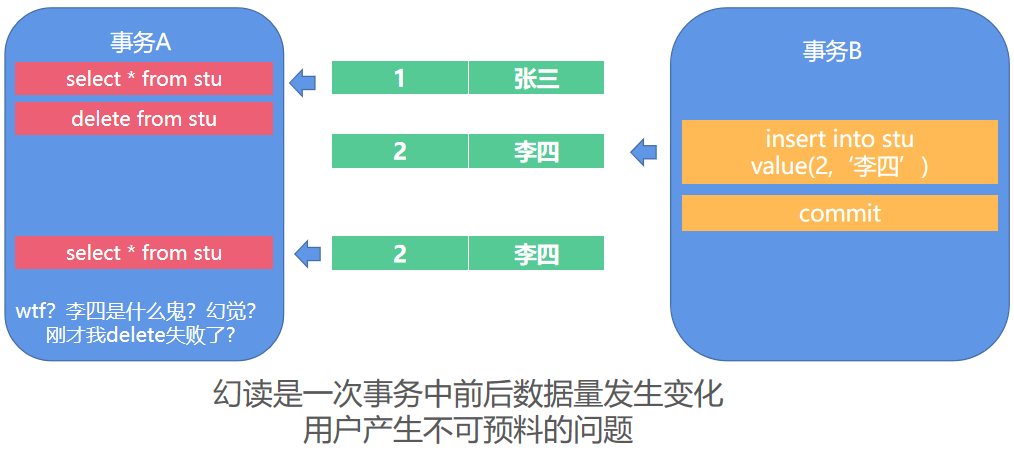
讲解脏读、不可重复读、幻读的区别与出现场景
通过事务隔离级别控制确保事务数据预期可控
脏读指读取到其他事务正在处理的未提交数据
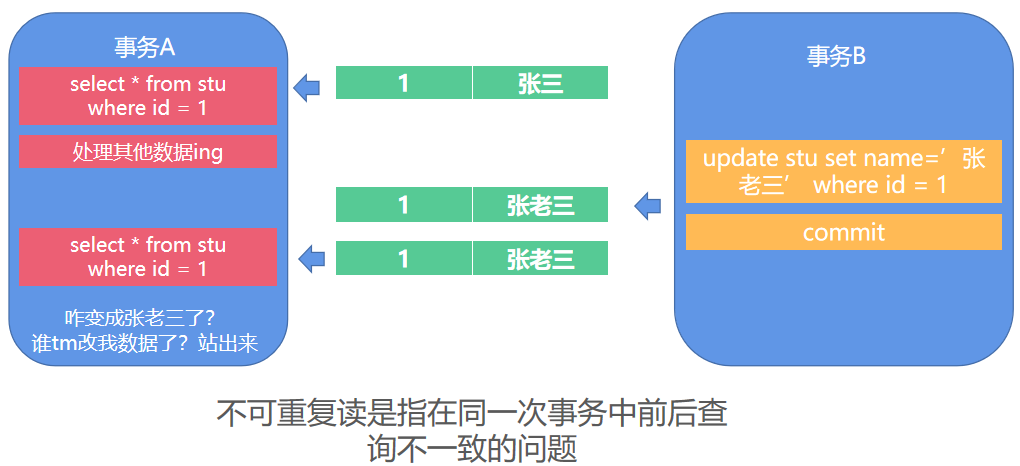
不可重复读指并发更新时,另一个事务前后查询相同数据时的数据不符合预期
幻读指并发新增、删除这种会产生数量变化的操作时,另一个事务前后查询相同数据时的不符合预期
事务隔离级别
| 隔离级 | 脏读可能性 | 不可重复读可能性 | 幻读可能性 | 加锁读 |
|---|---|---|---|---|
| READ UNCOMMITTED | 是 | 是 | 是 | 否 |
| READ COMMITTED | 否 | 是 | 是 | 否 |
| REPEATABLE READ | 否 | 否 | 是 (InnoDB 除外) | 否 |
| SERIALIZABLE | 否 | 否 | 否 | 是 |
#获取当前事务隔离界别,默认RR可重复读SHOW VARIABLES LIKE 'transaction_isolation'; # REPEATABLE-READ#设置当前会话事务隔离级别为“读未提交”SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
MySQL 默认 Repeatable Read(RR)-可重复读MySQL 5.1 以后默认存储引擎就是 InnoDB
因此 MySQL 默认 RR 也能解决幻读问题
【030】这可能是最直白的 MySQL MVCC 机制讲解啦!
来源:https://www.bilibili.com/video/BV1hL411479T/?spm_id_from=333.788.recommend_more_video.-1
| 隔离级 | 脏读可能性 | 不可重复读可能性 | 幻读可能性 | 加锁读 |
|---|---|---|---|---|
| READ UNCOMMITTED | 是 | 是 | 是 | 否 |
| READ COMMITTED | 否 | 是 | 是 | 否 |
| REPEATABLE READ | 否 | 否 | 是 (InnoDB 除外) | 否 |
| SERIALIZABLE | 否 | 否 | 否 | 是 |
在 MySQL InnoDB 存储引擎下
RC、RR 基于 MVCC(多版本并发控制)进行并发事务控制
MVCC 是基于“数据版本”对并发事务进行访问
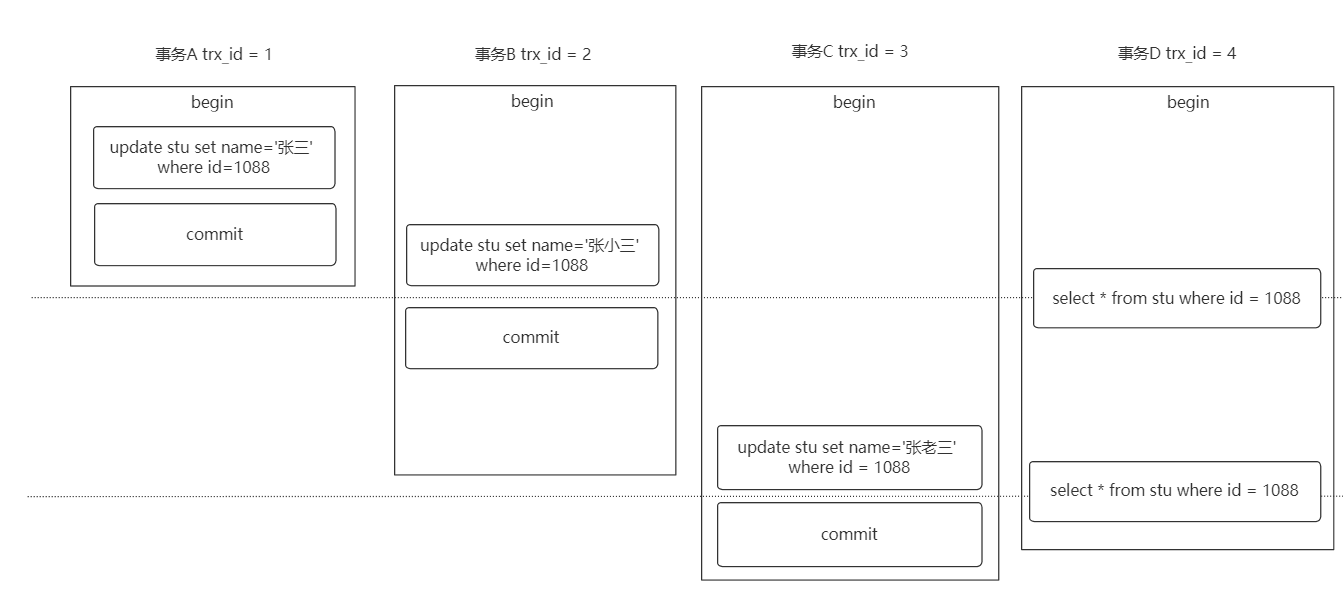
RR 级别: Select1=张三 Select2=张三
RC 级别:Select1=张三 Select2=张小三
RC 级别下出现了“不可重复读”
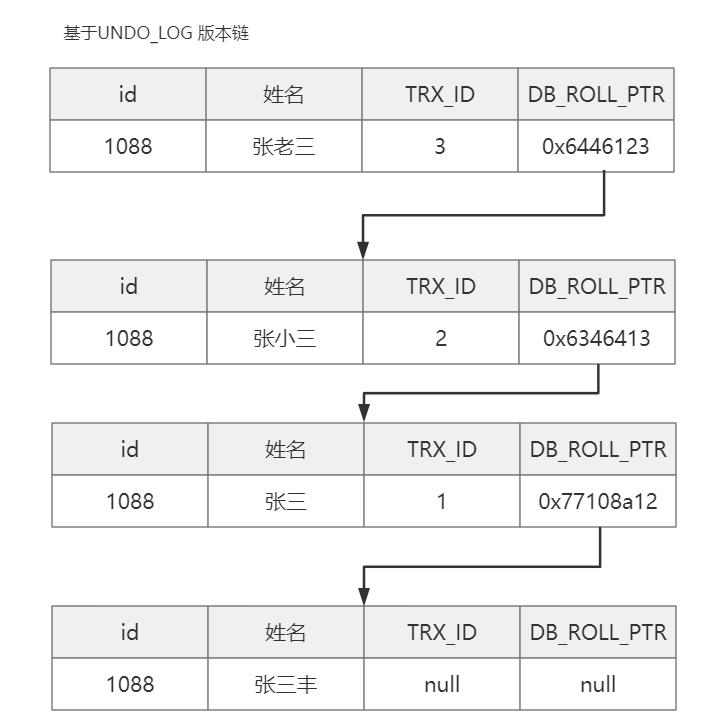
UNDO_LOG 不是会被删除吗?
中间数据万一被删了版本链不就断了?
UNDO_LOG 版本链不是立即删除,MySQL 确保版本链数据不再被“引用”后再进行删除。
ReadView 是什么?
ReadView 是“快照读” SQL 执行时 MVCC 提取数据的依据
快照读就是最普通的 Select 查询 SQL 语句
当前读指代执行下列语句时进行数据读取的方式
Insert、Update、Delete、Select...for updateSelect...lock in share mode
ReadView 是一个数据结构,包含 4 个字段
| 字段名称 | 描述 |
|---|---|
| m_ids | 当前活跃的事务编号集合 |
| min_trx_id | 最小活跃事务编号 |
| max_trx_id | 预分配事务编号,当前最大事务编号 +1 |
| creator_trx_id | ReadView 创建者的事务编号 |
读已提交(RC):在每一次执行快照读时生成 ReadView
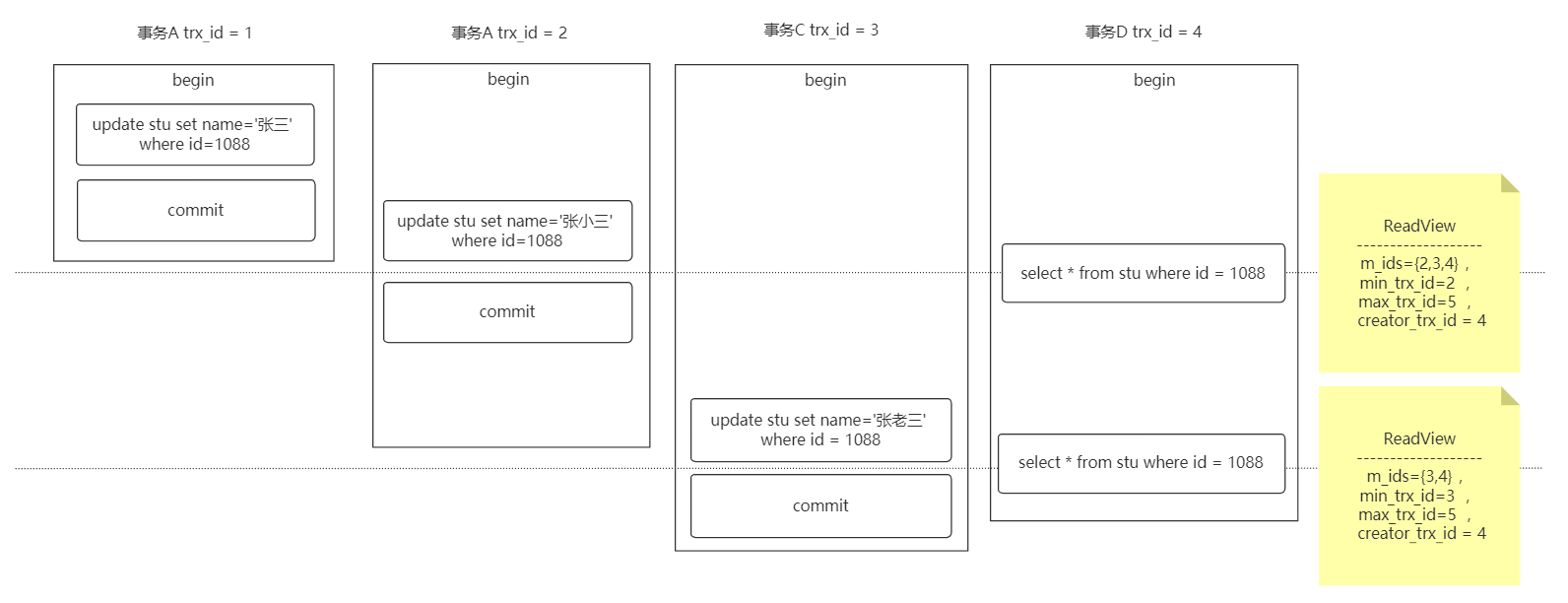
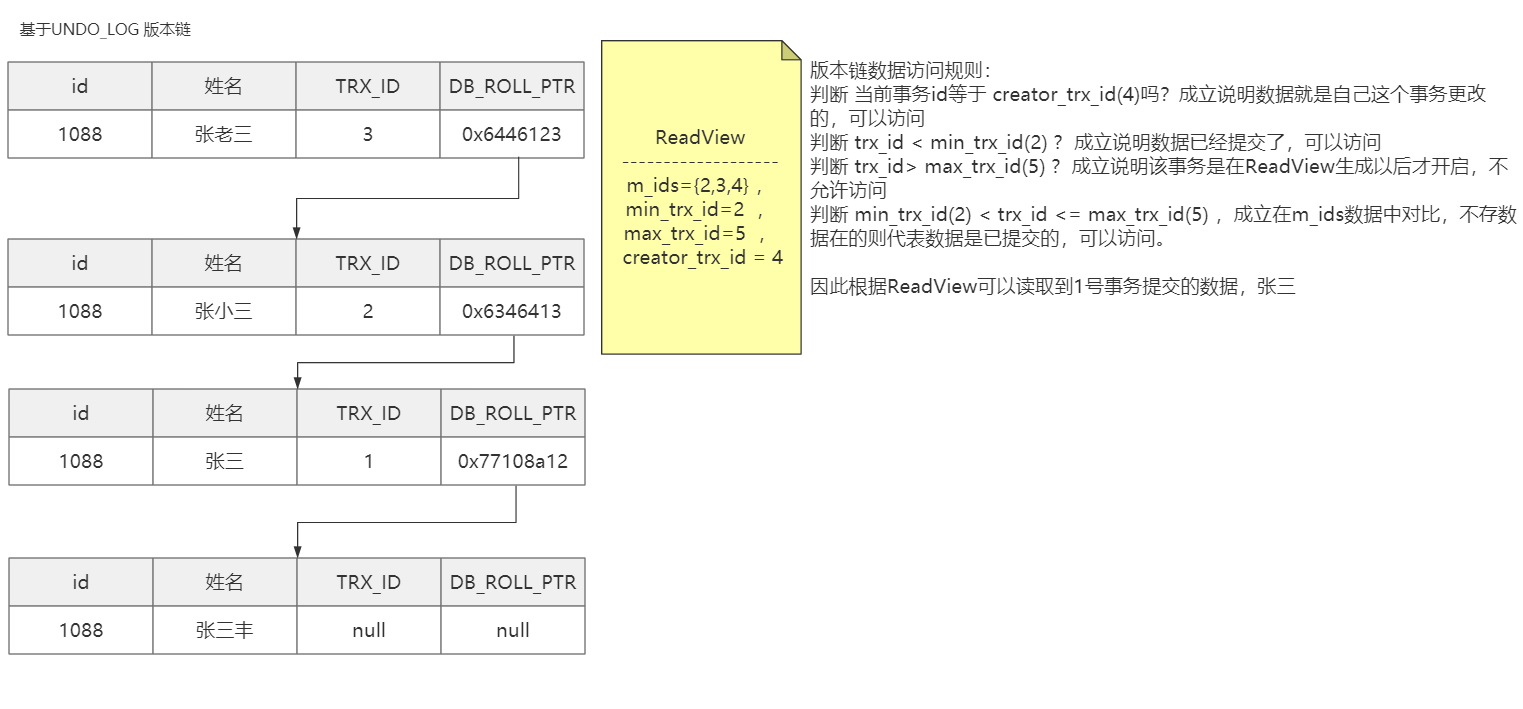
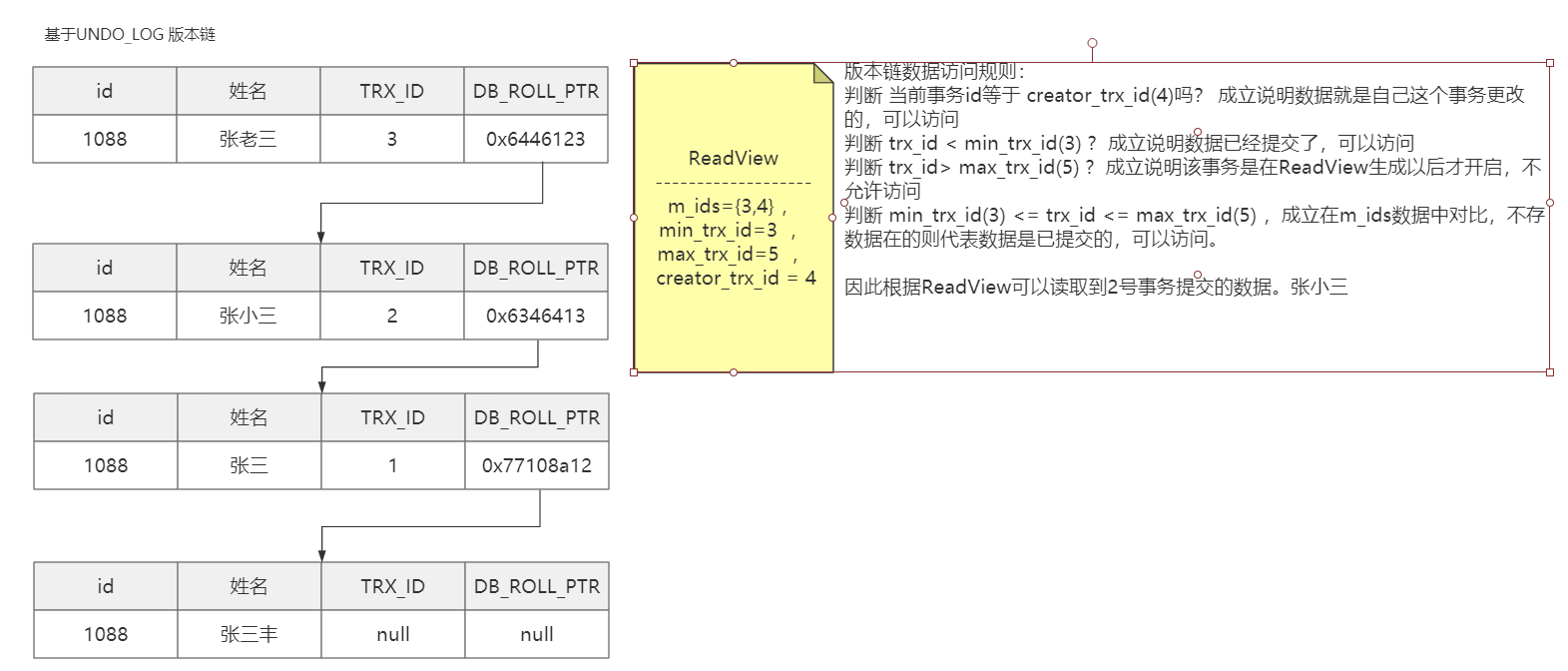
可重复读(RR):仅在第一次执行快照读时生成 ReadView,后续快照读复用(有例外:后面会说)
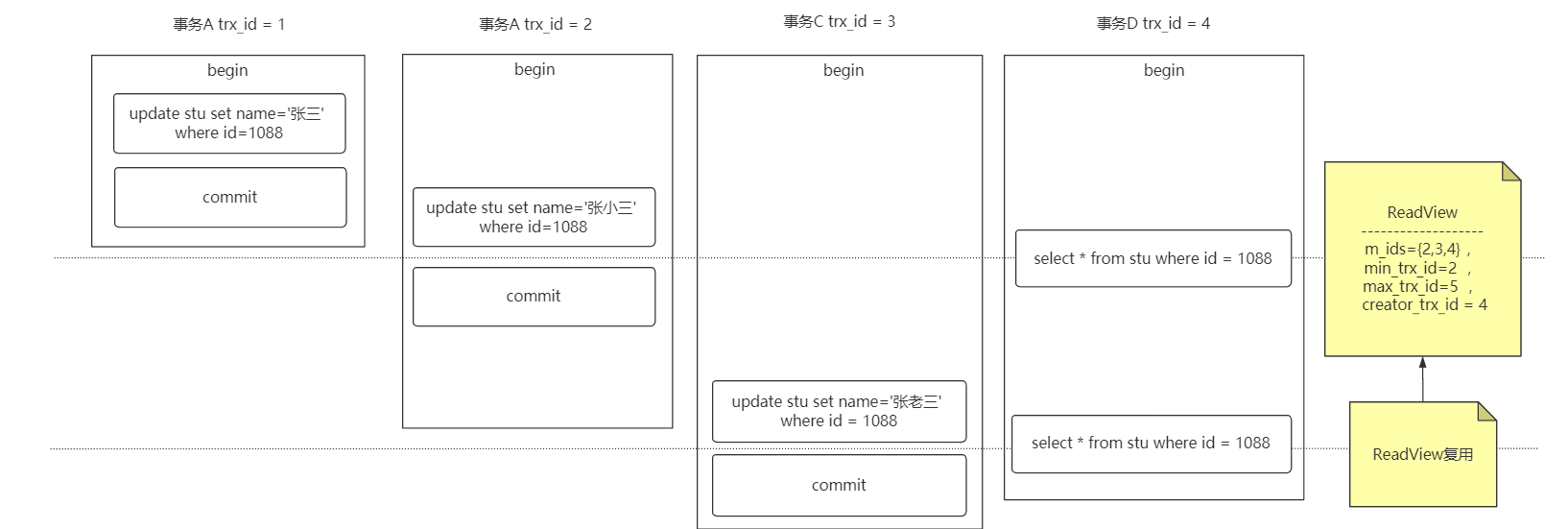
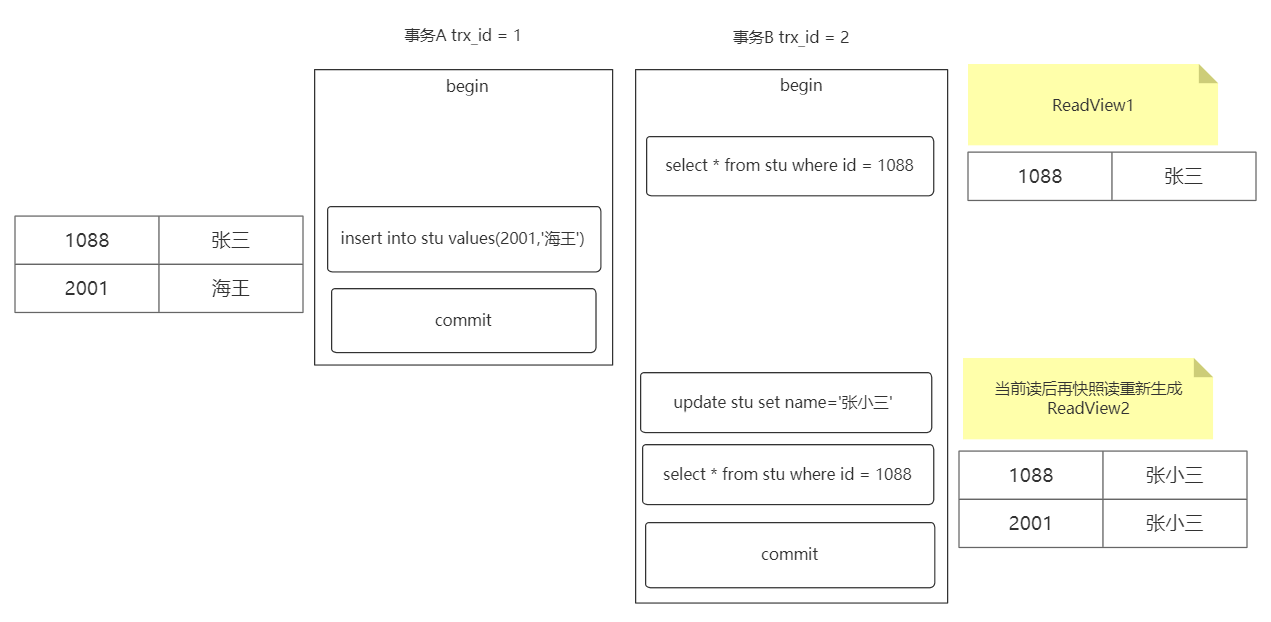
RR 级别下使用 MVCC 能避免幻读吗?
能,但不完全能!
连续多次快照读,ReadView 会产生复用,没有幻读问题
特例:当两次快照读之间存在当前读,ReadView 会重新生成,导致产生幻读
【007】-为什么大厂在大表做水平分表时严禁使用自增主键
来源:https://www.bilibili.com/video/BV15L411n7Xp?spm_id_from=333.999.0.0
大表为什么不能用自增主键?
如果确定这个表永远不会做水平分表,那自增主键是好的选择

自增主键在分布式环境下不适用。
必须提前做好分片规划
造成资源浪费
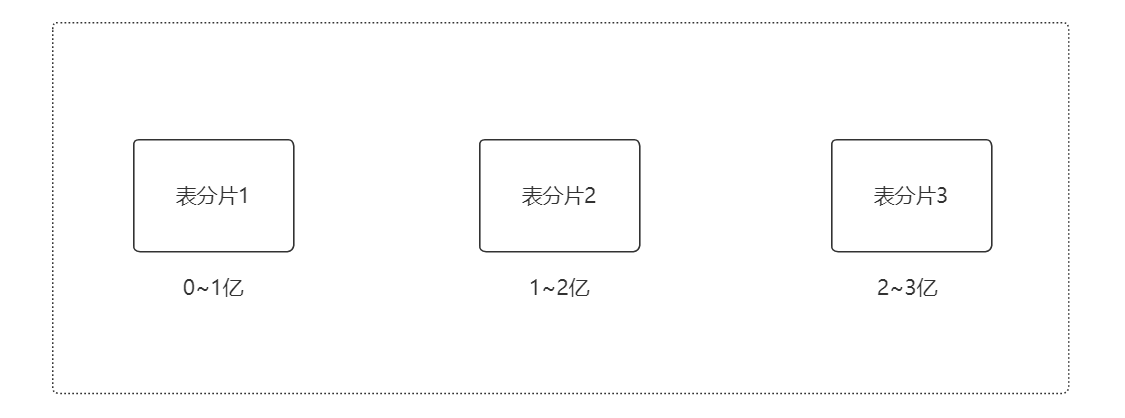
由于自增主键必须连续,所以按范围法进行分片,ID 的数量已固定。无法进行动态扩展。会产生“尾部热点”效应。
尾部热点:即按范围法进行分片后,前面的分片已储存数据,最后一个分片的压力很大。
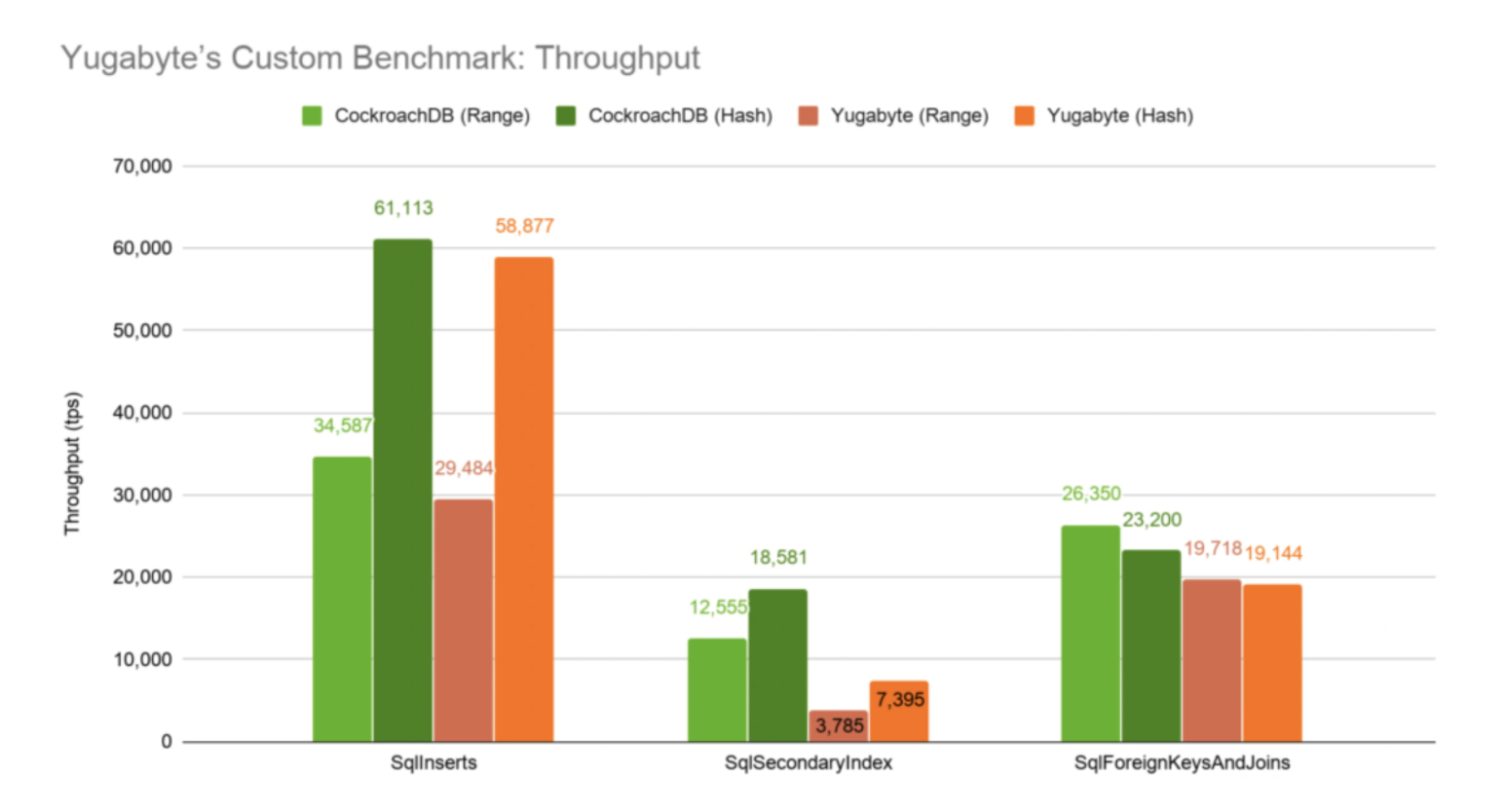
UUID 是好的替代方案吗?
使用 UUID 可以替代自增主键吗?
不可以!
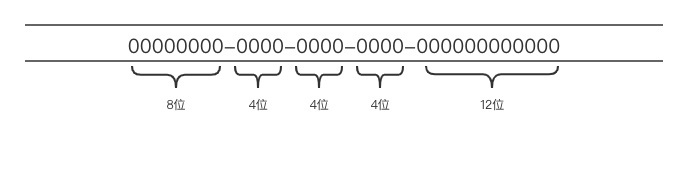
UUID 格式
0b7a900d-7e0c-4d14-b081-a20bdf1f1264d09bc3ab-9670-4355-9614-ab2bc5ca6fd9251ae4de-e3af-43cf-8287-77a944d2703fad397986-4bd9-4986-9f38-eb81042c7492
使用 UUID 是无序的
作为主键会涉及大量索引重排
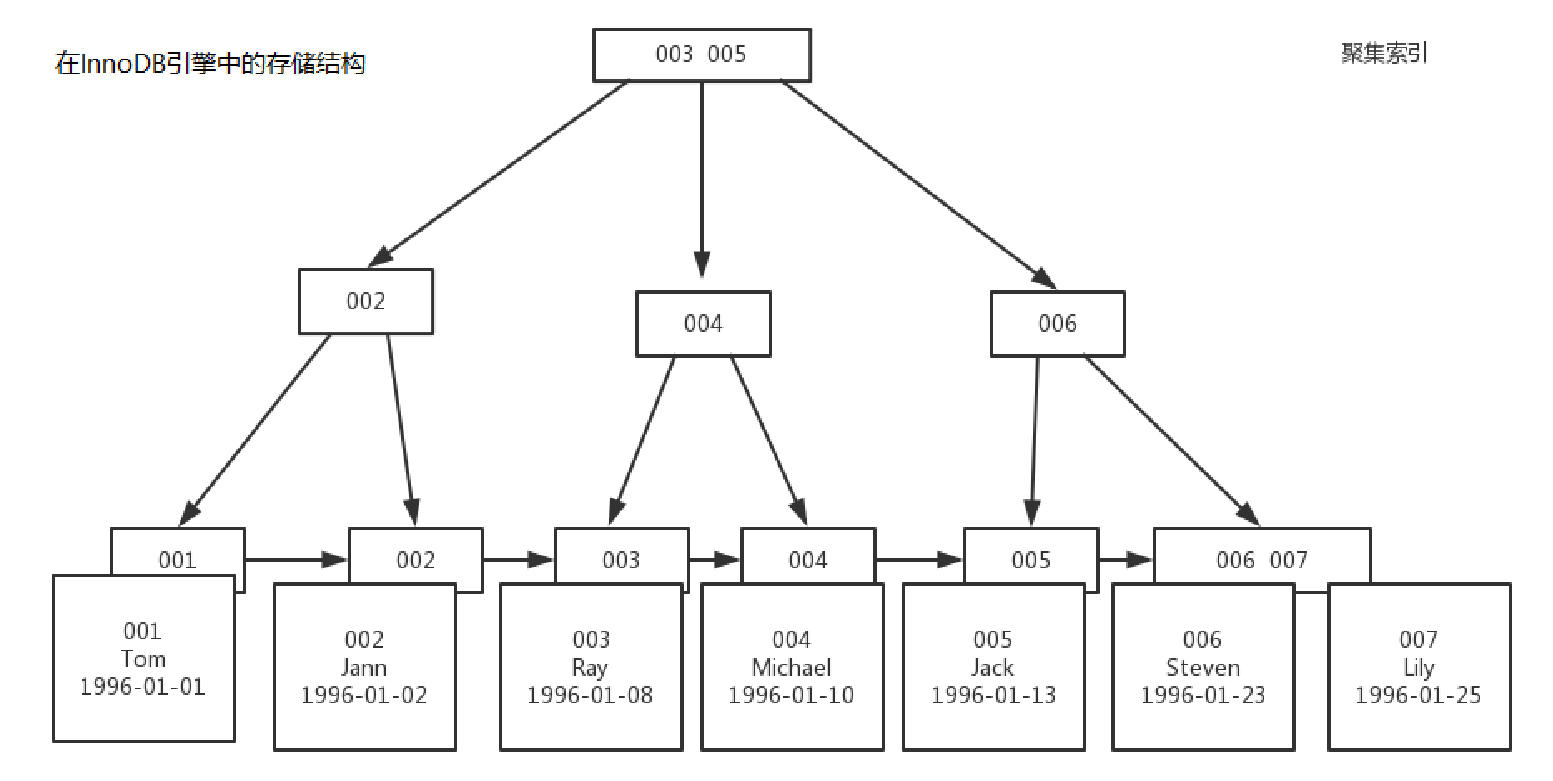
索引重排是指在有序的索引中,头部或者中部插入了某个新的索引,导致大规模索引重新排序计算的情况。正常情况下,如果 id 是有序的,只会在索引 B+ 树尾部追加,并不会引起重排

有没有一种分布式且有序的主键生成算法呢?
SnowFlake 雪花算法是什么?
雪花算法(Snowflake)是 Twitter 公司分布式项目采用的 ID 生成算法。
格式:
第一部分是 1 位的符号位,并没有实际用处,主要为了兼容长整型的格式。
第二部分是 41 位的时间戳用来记录本地的毫秒时间。
第三部分是机器 ID,这里说的机器就是生成 ID 的节点,用 10 位长度给机器做编码,那
意味着最大规模可以达到 1024 个节点(2^10)。
最后是 12 位序列,序列的长度直接决定了一个节点1毫秒能够产生的 ID 数量,12 位
就是 4096 (2^12)。
实现雪花算法时要注意时间回拨带来的影响。
【040】面试官:为什么表的主键要使用代理主键(自增编号),不建议使用自然主键?
来源:https://www.bilibili.com/video/BV13L411x7Bj?spm_id_from=333.999.0.0
业务(自然)主键
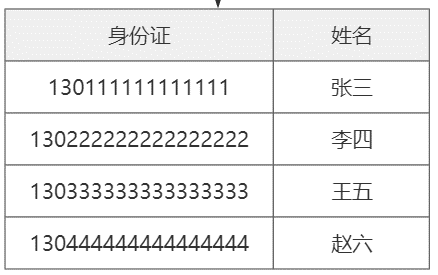
代理主键(无意义自动编号)
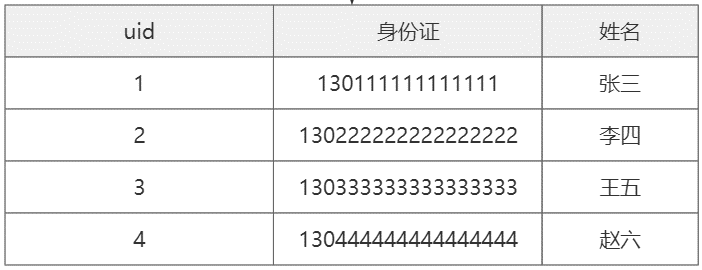
为什么表的主键要使用代理主键,不建议使用自然主键?
1.业务主键更浪费空间
2.业务主键无顺序,可能会造成写入数据时需要更长组织索引
3.业务主键如果是字符串,在分库分表时,无法直接取模运算,需要先转换为数字,处理更麻烦了。
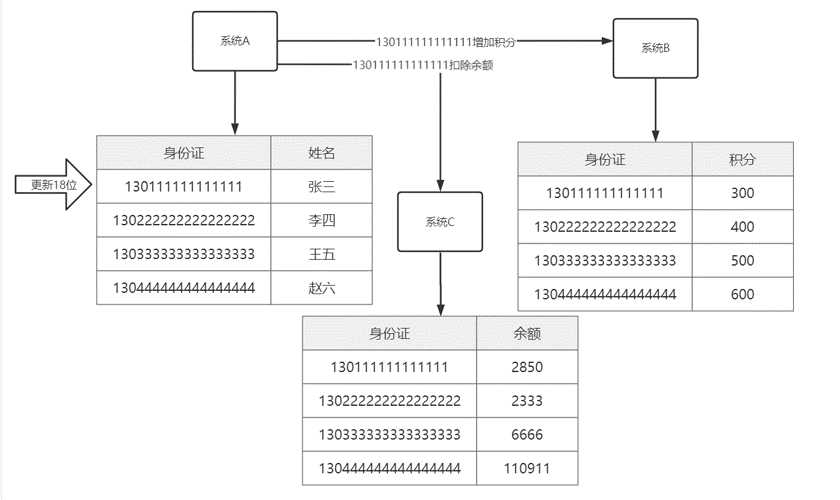
使用业务组件的情况
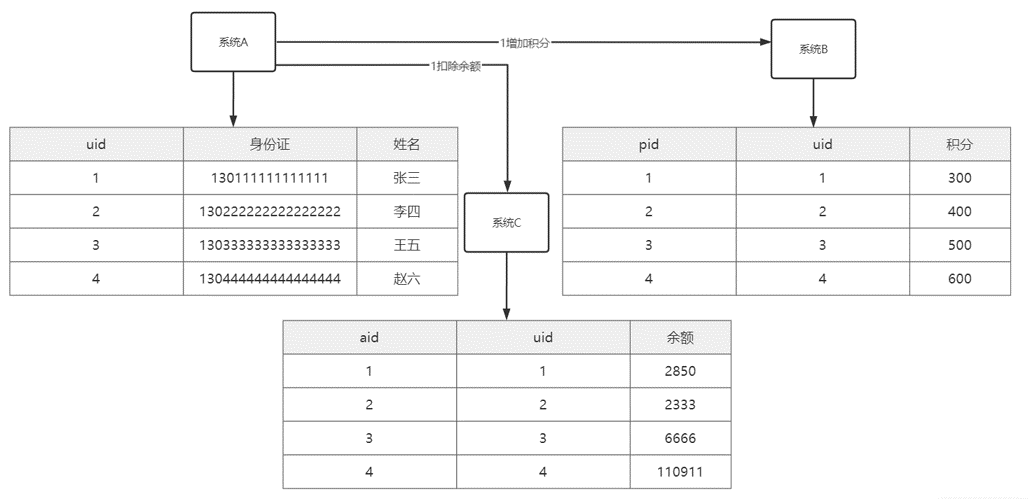
使用的代理主键的情况
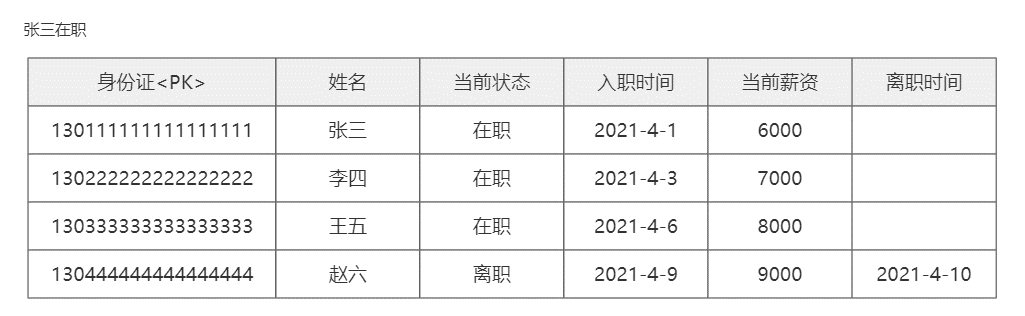
使用业务组件造成业务冲突的案例
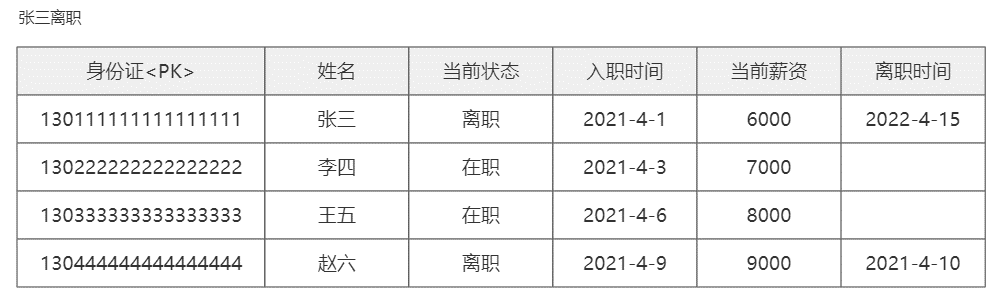
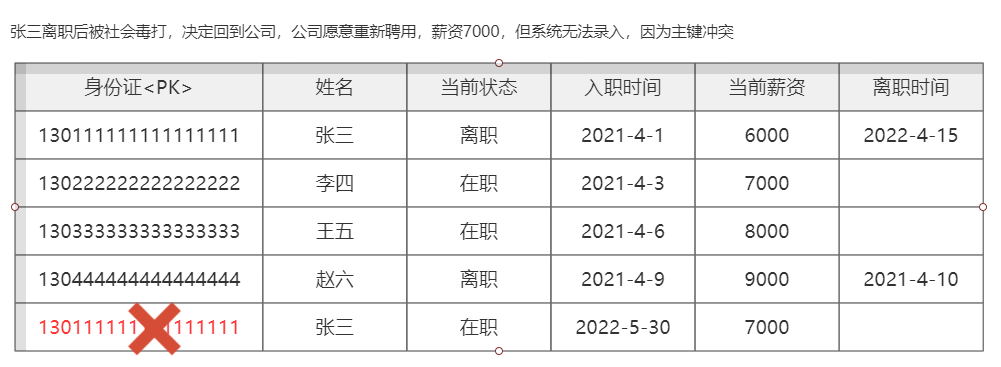
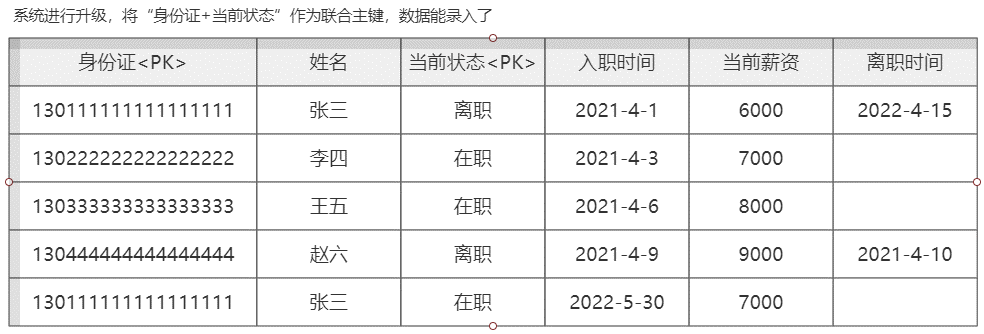
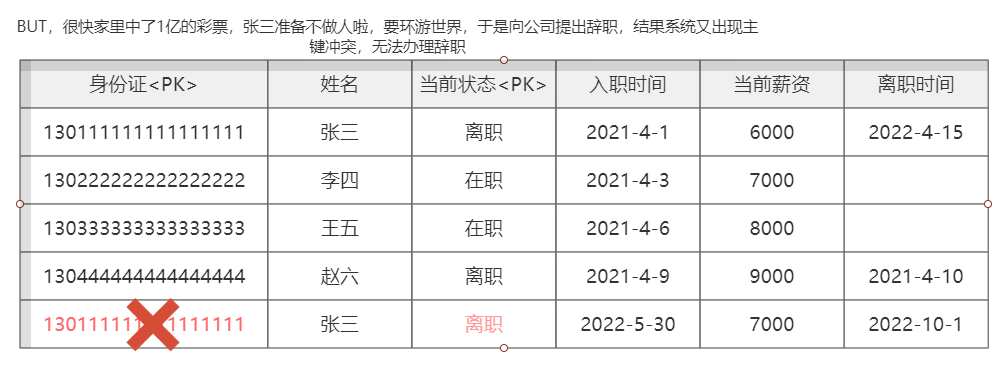
【047】避坑分享,财Z部金财平台用主键用了 UUID 后,我们都疯了!
来源:https://www.bilibili.com/video/BV1fh411p7M6?spm_id_from=333.999.0.0
问题描述:
财政部金财工程平台在代理行日终结算时
经常出现磁盘的 IO 异常,导致经常出现高延迟
这个问题一直困扰我们很长时间,
对比发现在大量数据新增时磁盘 IO 居高不下
多次测试后发现是 UUID 主键在搞鬼,
那究竟是什么原因呢?我来跟大家分享下
UUID(Universally Unique Identifier):
例如:7bf13c38-00a1-489e-b1d3-80c4b9b2fa66
UUID 版本
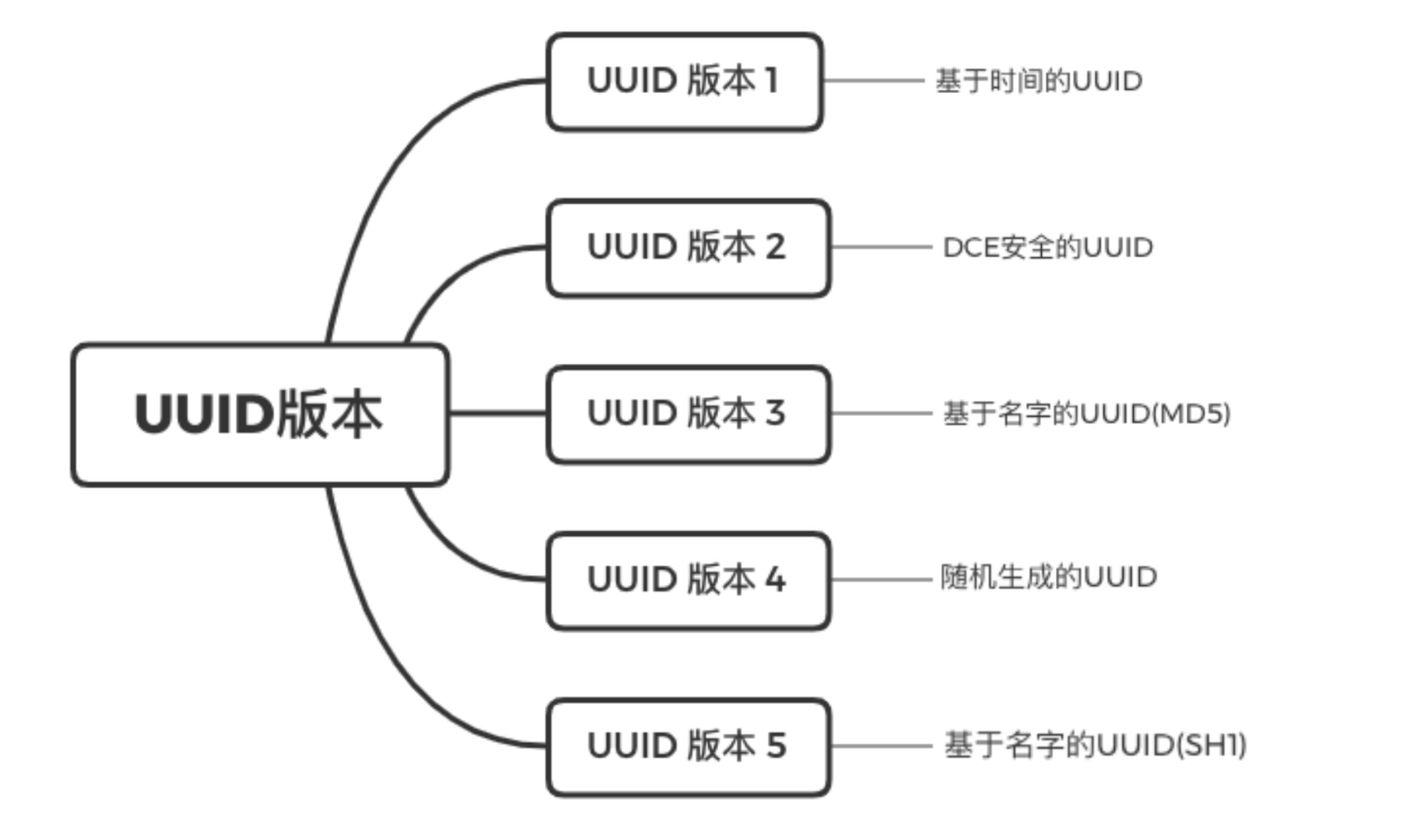
基于时间的 UUID
● 能保证不同设备 UUID 是唯一的
● 在同一设备上生成 UUID 可能重复
DCE 安全的 UUID
● DCE(身份验证和安全服务)
● 涉及侵犯用户隐私
● 有损时间戳导致精度丢失
基于命名空间的 UUID(MD5、SH1)
● 在相同的命名空间下可能会出现 UUID 冲突
基于随机数的 UUID
● 完全随机生成,会存在极小概率重复的情况
● 与外部环境无关,不涉及环境信息
● 生成内容无序无规律
● 目前的主流做法
Java UUID 生成方法
java.util.UUIDpublic static UUID randomUUID();------------------------------------------------------------7bf13c38-00a1-489e-b1d3-80c4b9b2fa66
为什么 UUID 会引起 IO 异常

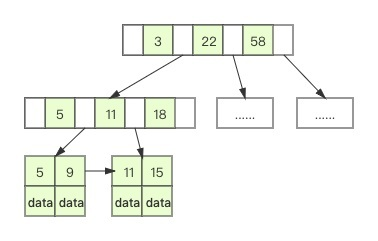
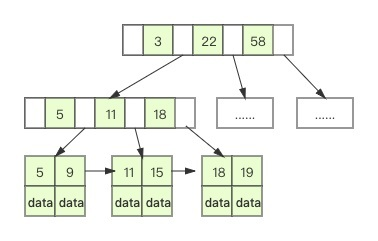
UUID 是无序的,当 UUID 可能在索引中间某一页插入数据时
新增记录所在的数据页已满,数据库需要申请一个新的数据页存储数据
这种现象被称为“页分裂”
页分裂确保后一个数据页中的所有的 ID 值一定比数据页中的 ID 值大
在大并发环境环境下增加了磁盘 IO 的压力,无序 ID 才是罪魁祸首
解决办法:改为有序的数字主键生成策略就可以了
如美团 Leaf / 推特 Snowflake
【050】CPU、内存、硬盘三大件,MySQL 服务器该如何选择?
来源:https://www.bilibili.com/video/BV1KP4y1a7EX?spm_id_from=333.999.0.0
CPU 优先选大核还是选多核?

● 64位的 CPU 一定要工作在 64 位的系统下
● 对于并发比较高的场景 CPU 的数量比频率重要
● 对于 CPU 密集性场景和复杂 SQL 则频率越高越好
物理内存多大合适?
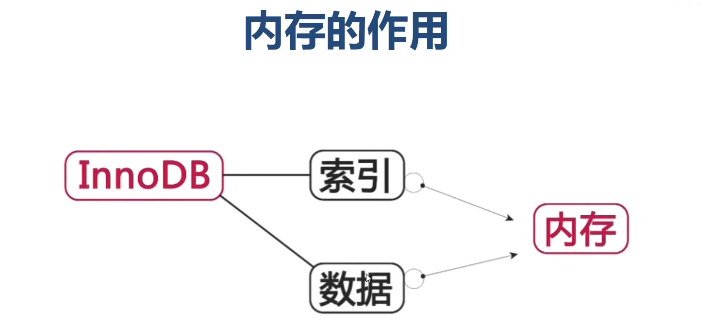
● 理想的选择是服务器内存大于数据总量
● 内存频率越高处理速度越快
● 内存总量小要合理组织热点数据,保证内存覆盖
● 内存对写操作也有重要的性能影响
硬盘 RAID 该怎么选?

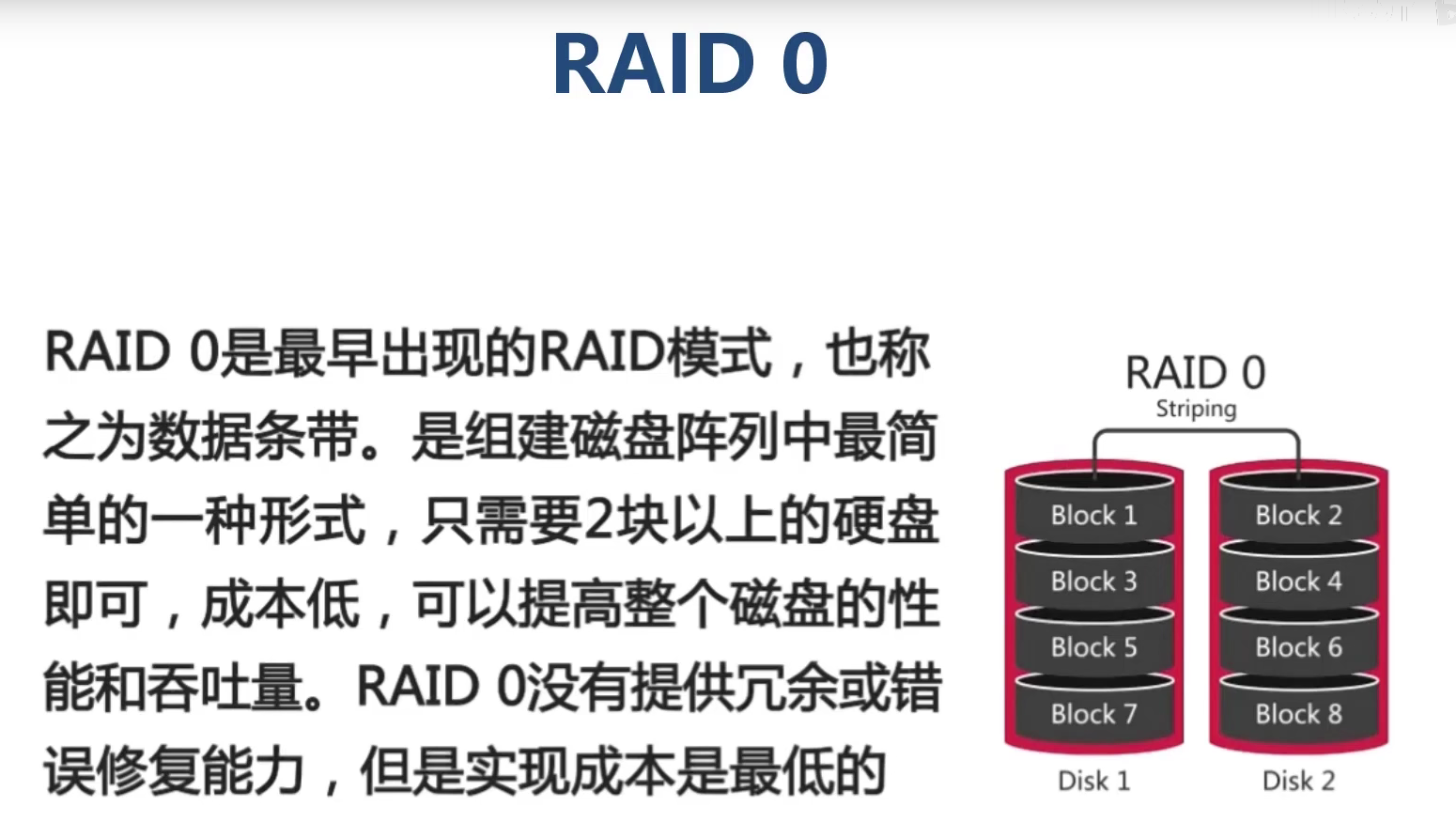
什么是 RAID
RAID是磁盘冗余队列的简称
(Redundant Arrays of Independent Disks)
简单来说 RAID 的作用就是可以把多个容量较小的磁盘
组成一组容量更大的磁盘, 并提供数据冗余来保证数据完整性的技术


RAID 级别的选择
| 等级 | 特点 | 是否冗余 | 盘数 | 读 | 写 |
|---|---|---|---|---|---|
| RAID0 | 便宜,快速,危险 | 否 | N | 快 | 快 |
| RAID1 | 高速读,简单,安全 | 有 | 2 | 快 | 慢 |
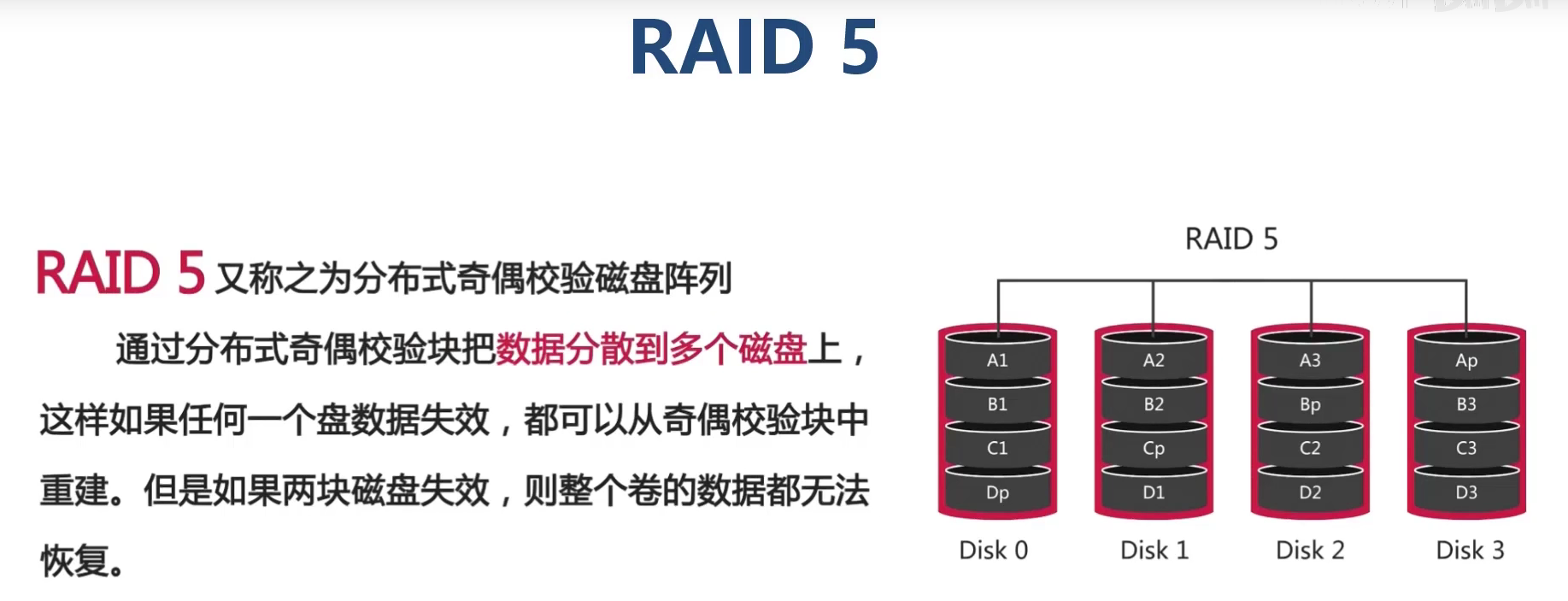
| RAID5 | 安全,成本折中 | 有 | N + 1 | 快 | 取决于最慢的盘 |
| RAID10 | 贵,高速,安全 | 有 | 2N | 快 | 快 |
【055】MySQL 模糊查询还在用like?Mysql Ngram 全文检索技术快速上手
来源:https://www.bilibili.com/video/BV1xv411G7Cv?spm_id_from=333.999.0.0
索引失效的情况
create index idx_title on article(title)#可能用到索引,看索引选择性select * from article where title like ‘Java%’#一定不会用到索引select * from article where title like ‘%Java’select * from article where title like ‘%Java%’
为什么不使用 ElasticSearch?

● 更高的成本
● 数据一致性如何保证
● ElasticSearch 高可用架构采用哪种方案
● 谁来负责维护 ElasticSearch
MySQL 给出了折中的办法
从 MySQL 5.7.6 开始,MySQL 内置了 ngram 全文解析器
允许对短文本进行全文检索查询,以替代 like 关键字
对于复杂业务场景的全文检索查询,还是要用 ES
使用案例:MySQL 5.7 中文全文检索