参考
前提
开发环境
第一台机器-Linux
由于条件限制,Mycat 也安装在这台机器
由于条件限制,Mycat 也安装在这台机器
| 名称 | 版本 |
|---|---|
| CentOS7 | CentOS-7-x86_64-DVD-2003.iso |
| Linux | 3.10.0-1127.el7.x86_64 |
| mysql | 5.7.16 |
| IP | 192.168.114.128 |
第二台机器-Windows
| 名称 | 版本 |
|---|---|
| 操作系统 | Windows 10 X64 |
| mysql | 8.0.11 |
| IP | 192.168.114.1 |
测试库
两台机器都存在的数据库 luoma_test_1
分库
测试表-customer
配置 customer 表只在 192.168.114.1 这台机器的数据库上使用
CREATE TABLE customer(id INT AUTO_INCREMENT,NAME VARCHAR(200),PRIMARY KEY(id));insert into customer(`name`) values('name1');insert into customer(`name`) values('name2');
修改 schema.xml
<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"><table name="customer" dataNode="dn2" ></table></schema><dataNode name="dn1" dataHost="host1" database="luoma_test_1" /><dataNode name="dn2" dataHost="host2" database="luoma_test_1" /><dataHost name="host1" maxCon="1000" minCon="10" balance="1"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="192.168.114.128:3306" user="root"password="123456"><!-- 读写分离; 写走 hostM1,读走 hostS1; hostM1 宕机了, hostS1 也不可用 --><readHost host="hostS1" url="192.168.114.1:3306" user="root"password="123456"></readHost></writeHost><!-- 高可用,hostM1宕机了, hostM2顶上 --><writeHost host="hostM2" url="192.168.114.1:3306" user="root" password="123456" /></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="host2M1" url="192.168.114.1:3306" user="root"password="123456"></writeHost></dataHost></mycat:schema>
测试
进入 Macat mysql -uroot -p123456 -P8066 -h192.168.114.128
查询 customer
mysql> select * from customer;+----+-------+| id | NAME |+----+-------+| 1 | name1 || 2 | name2 |+----+-------+2 rows in set (0.25 sec)
水平分表
测试表-orders
orders 表根据 customer_id 不同放到不同的数据库中
两台机器的 luoma_test_1 数据库都创建这张表
CREATE TABLE orders(id INT AUTO_INCREMENT,order_type INT,customer_id INT,amount DECIMAL(10,2),PRIMARY KEY(id));
修改 schema.xml
vim /usr/local/mycat/conf/schema.xml
<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"><table name="customer" dataNode="dn2"></table><table name="orders" dataNode="dn1,dn2" rule="mod_rule" ></table></schema><dataNode name="dn1" dataHost="host1" database="luoma_test_1" /><dataNode name="dn2" dataHost="host2" database="luoma_test_1" /><dataHost name="host1" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="host1M1" url="192.168.114.128:3306" user="root" password="123456"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="host2M1" url="192.168.114.1:3306" user="root" password="123456"></writeHost></dataHost></mycat:schema>
修改 rule.xml
vim /usr/local/mycat/conf/rule.xml
<tableRule name="mod_rule"><rule><columns>customer_id</columns><algorithm>mod-long</algorithm></rule></tableRule><function name="mod-long" class="io.mycat.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">2</property></function>
重启 Macat
mycat restart
Mycat 添加 orders 表数据
mysql -uroot -p123456 -P8066 -h192.168.114.128
insert into orders(id,order_type,customer_id,amount) values(1,101,100,100100);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
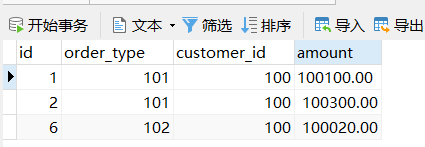
第一台机器的 orders 表数据
可以看到,根据 customer_id 字段进行了存储
第二台机器的 orders 表数据
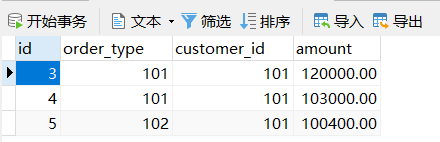
可以看到,根据 customer_id 字段进行了存储
Mycat 查询
mysql -uroot -p123456 -P8066 -h192.168.114.128
可以看到,Mycat 把两个数据库两张表的数据进行了合并。
mysql> select * from orders;+----+------------+-------------+-----------+| id | order_type | customer_id | amount |+----+------------+-------------+-----------+| 1 | 101 | 100 | 100100.00 || 2 | 101 | 100 | 100300.00 || 6 | 102 | 100 | 100020.00 || 3 | 101 | 101 | 120000.00 || 4 | 101 | 101 | 103000.00 || 5 | 102 | 101 | 100400.00 |+----+------------+-------------+-----------+6 rows in set (0.10 sec)
ER 分片
有一类业务,例如订单(orders)跟订单明细(orders_detail) ,明细表会依赖于订单,也就是说会存在表的主
从关系,这类似业务的切分可以抽象出合适的切分规则,比如根据用户ID(customer_id)切分,其他相关的表都依赖于用户ID。
再或者根据订单 ID 切分,总之部分业务总会可以抽象出父子关系的表。这类表适用于 ER 分片表,子表的记录与所关联的父表记录存放在同一个数据分片上,避免数据 Join 跨库操作。
测试表-orders_detail
create table orders_detail(id INT AUTO_INCREMENT,detail varchar(2000),order_id int,PRIMARY KEY(id));
在两台机器上分别创建表
修改 schema.xml
vim /usr/local/mycat/conf/schema.xml
<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"><table name="customer" dataNode="dn2"></table><table name="orders" dataNode="dn1,dn2" rule="mod_rule" ><childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /></table></schema><dataNode name="dn1" dataHost="host1" database="luoma_test_1" /><dataNode name="dn2" dataHost="host2" database="luoma_test_1" /><dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="host1M1" url="192.168.114.128:3306" user="root" password="123456"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="host2M1" url="192.168.114.1:3306" user="root" password="123456"></writeHost></dataHost></mycat:schema>
重启 Mycat 服务 mycat restart
测试-父表和子表数据不在一个分片上
1.第一台机器
现在第一台机器的 orders 数据如下
orders_detail 的数据如下
insert into orders_detail(detail,order_id) values('订单 3 详情',3);insert into orders_detail(detail,order_id) values('订单 4 详情',4);
2.第二台机器
第二台机器的 orders 表数据如下
orders_detail 的数据如下
insert into orders_detail(detail,order_id) values('订单 1 详情',1);insert into orders_detail(detail,order_id) values('订单 2 详情',2);
3.Mycat 查询
mysql -uroot -p123456 -P8066 -h192.168.114.128
mysql> select t1.*,t2.detail from orders t1,orders_detail t2 where t1.id = t2.order_id;Empty set (0.01 sec)
如果出现了同一台机器,子表的记录和所关联的父表就没有在同一个数据分片上,就会出现数据丢失。
测试-父表和子表数据在一个分片上
1.第一台机器
现在第一台机器的 orders 数据如下
orders_detail 的数据如下
delete from orders_detail;insert into orders_detail(detail,order_id) values('订单 1 详情',1);insert into orders_detail(detail,order_id) values('订单 2 详情',2);
2.第二台机器
第二台机器的 orders 表数据如下
orders_detail 的数据如下
delete from orders_detail;insert into orders_detail(detail,order_id) values('订单 4 详情',4);insert into orders_detail(detail,order_id) values('订单 5 详情',5);
3.Mycat 查询
mysql -uroot -p123456 -P8066 -h192.168.114.128
mysql> select t1.*,t2.detail from orders t1,orders_detail t2 where t1.id = t2.order_id;+----+------------+-------------+-----------+-----------------+| id | order_type | customer_id | amount | detail |+----+------------+-------------+-----------+-----------------+| 4 | 101 | 101 | 103000.00 | 订单 4 详情 || 5 | 102 | 101 | 100400.00 | 订单 5 详情 || 1 | 101 | 100 | 100100.00 | 订单 1 详情 || 2 | 101 | 100 | 100300.00 | 订单 2 详情 |+----+------------+-------------+-----------+-----------------+4 rows in set (0.00 sec)
全局表
设定为全局的表,会直接复制给每个数据库一份,所有写操作也会同步给多个库。
所以全局表一般不能是大数据表或者更新频繁的表
一般是字典表或者系统表为宜。
测试表-dict_order_type
两台机器都创建这张表
create table dict_order_type(id INT AUTO_INCREMENT,order_type varchar(200),PRIMARY KEY(id));
修改 schema.xml
vim /usr/local/mycat/conf/schema.xml
<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"><table name="customer" dataNode="dn2"></table><table name="orders" dataNode="dn1,dn2" rule="mod_rule" ><childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /></table><table name="dict_order_type" dataNode="dn1,dn2" type="global" ></table></schema><dataNode name="dn1" dataHost="host1" database="luoma_test_1" /><dataNode name="dn2" dataHost="host2" database="luoma_test_1" /><dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="host1M1" url="192.168.114.128:3306" user="root" password="123456"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="host2M1" url="192.168.114.1:3306" user="root" password="123456"></writeHost></dataHost></mycat:schema>
重启 Mycat 服务 mycat restart
Mycat 添加数据
mysql -uroot -p123456 -P8066 -h192.168.114.128
insert into dict_order_type(id,order_type) values(101,'type1');insert into dict_order_type(id,order_type) VALUES(102,'type2');
第一台机器的 dict_order_type 表数据
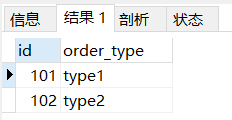
第二台机器的 dict_order_type 表数据
全局序列
全局序列三种实现方式
1.本地文件方式(不推荐)
2.数据库方式
3.本地时间戳方式(18 位,不推荐)
或者可以自主生成,例如:
1.根据业务逻辑组合
2.可以利用 redis 的单线程原子性 incr 来生成序列
下面介绍使用数据库方式实现全局序列
数据库序列方式原理
利用数据库一个表 来进行计数累加。
但是并不是每次生成序列都读写数据库,这样效率太低
mycat会预加载一部分号段到 mycat 的内存中,这样大部分读写序列都是在内存中完成的。
如果内存中的号段用完了 mycat 会再向数据库要一次。
问:那如果 mycat 崩溃了,那内存中的序列岂不是都没了?
是的。如果是这样,那么 mycat 启动后会向数据库申请新的号段,原有号段会弃用。
也就是说如果 mycat 重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复。
建库序列脚本
以下脚本都在第二台机器的 luoma_test_1 数据库创建
1.创建表 MYCAT_SEQUENCE
CREATE TABLE MYCAT_SEQUENCE(NAME VARCHAR(50) NOT NULL,current_value INT NOT NULL,increment INT NOT NULL DEFAULT 100,PRIMARY KEY(NAME)) ENGINE=INNODB;
2.创建方法 mycat_seq_currval
DELIMITER $$CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)DETERMINISTICBEGINDECLARE retval VARCHAR(64);SET retval="-999999999,null";SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retvalFROM MYCAT_SEQUENCE WHERE NAME = seq_name;RETURN retval;END $$DELIMITER;
3.创建方法 mycat_seq_setval
DELIMITER $$CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS VARCHAR(64)DETERMINISTICBEGINUPDATE MYCAT_SEQUENCESET current_value = VALUEWHERE NAME = seq_name;RETURN mycat_seq_currval(seq_name);END $$DELIMITER ;
4.创建方法 mycat_seq_nextval
DELIMITER $$CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)DETERMINISTICBEGINUPDATE MYCAT_SEQUENCESET current_value = current_value + increment WHERE NAME = seq_name;RETURN mycat_seq_currval(seq_name);END $$DELIMITER;
5.增加要用的序列
TRUNCATE TABLE MYCAT_SEQUENCE;##增加要用的序列INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment)VALUES ('ORDERS', 400000,100);SELECT * FROM MYCAT_SEQUENCE;
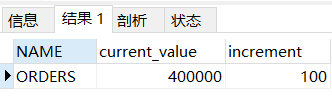
修改 mycat 配置
1.sequence_db_conf.properties
vim /usr/local/mycat/conf/sequence_db_conf.properties
#sequence stored in datanodeGLOBAL=dn1COMPANY=dn1CUSTOMER=dn1ORDERS=dn2
意思是 ORDERS 这个序列在 dn1 这个节点上,具体 dn2 节点是哪台机子,参考 schema.xml,这里就是第二台机器
<dataNode name="dn2" dataHost="host2" database="luoma_test_1" /><dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="host2M1" url="192.168.114.1:3306" user="root" password="123456"></writeHost></dataHost>
2.server.xml
vim /usr/local/mycat/conf/server.xml
<property name="sequnceHandlerType">1</property>
| sequnceHandlerType 值 | 描述 |
|---|---|
| 0 | 配置为 0 表示使用本地文件读取 |
| 1 | 配置为 1 表示从数据库表中读取 |
| 2 | 配置为 2 表示时间戳方式 |
3.重启 Mycat
mycat restart
4.测试前
现在第一台机器的 orders 数据如下
第二台机器的 orders 表数据如下
5.Mycat 添加数据
mysql -uroot -p123456 -P8066 -h192.168.114.128
insert into `orders`(id,amount,customer_id,order_type) values(next value for MYCATSEQ_ORDERS,1000,101,102);insert into `orders`(id,amount,customer_id,order_type) values(next value for MYCATSEQ_ORDERS,1000,100,102);
5.测试后
现在第一台机器的 orders 数据如下
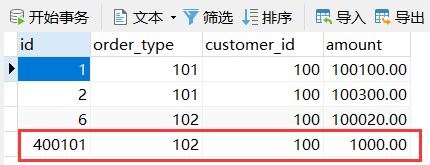
第二台机器的 orders 表数据如下
