[目录]
参考资料
业务背景
之前数据库的编码是 gbk,为了业务的国际化,需要把编码修改为 utf8
由于 gbk 和 utf8 对应汉字的存储字节不同,所以需要对之前的字段做兼容性处理
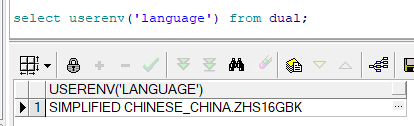
Oracal数据库当前字符编码
查询sql:select userenv('language') from dual;
查询结果:SIMPLIFIED CHINESE_CHINA.ZHS16GBK
gbk 和 utf8 对应字节
| 编码类型 | 英文字节 | 汉字字节 |
|---|---|---|
| gbk | 1 | 2 |
| utf-8 | 1 | 3 |
string strTmp = "h";int ascii = System.Text.Encoding.ASCII.GetBytes(strTmp).Length;int unicode = System.Text.Encoding.Unicode.GetBytes(strTmp).Length;int gbk = System.Text.Encoding.Default.GetBytes(strTmp).Length;int utf8 = System.Text.Encoding.UTF8.GetBytes(strTmp).Length;Console.WriteLine("ascii-----:" + ascii);Console.WriteLine("unicode---:" + unicode);Console.WriteLine("gbk-------:"+ gbk);Console.WriteLine("utf8------:" + utf8);Console.ReadKey();
结果:
ascii-----:1unicode---:2gbk-------:1utf8------:1
string strTmp = "汉";int ascii = System.Text.Encoding.ASCII.GetBytes(strTmp).Length;int unicode = System.Text.Encoding.Unicode.GetBytes(strTmp).Length;int gbk = System.Text.Encoding.Default.GetBytes(strTmp).Length;int utf8 = System.Text.Encoding.UTF8.GetBytes(strTmp).Length;Console.WriteLine("ascii-----:" + ascii);Console.WriteLine("unicode---:" + unicode);Console.WriteLine("gbk-------:"+ gbk);Console.WriteLine("utf8------:" + utf8);Console.ReadKey();
结果:
ascii-----:1unicode---:2gbk-------:2utf8------:3
修改思路
从下表可知,gbk 和 utf8 英文都只占用1个字节
gbk 1个汉字占用2个字节,utf8 占用3个,3/2=1.5
| 编码类型 | 英文字节 | 汉字字节 |
|---|---|---|
| gbk | 1 | 2 |
| utf-8 | 1 | 3 |
如果之前的 gbk 编码类型长度为 255,修改为 utf8 后,对应类型长度应该为
255*1.5 = 382.5
为了更好的兼容,我们修改为之前长度的两倍 255*2
使用 oracle dmu 得到需要扩容表和字段
什么是 Oracle Database Migration Assistant for Unicode?
Oracle Database Migration Assistant for Unicode (DMU) 是一款独特的下一代迁移工具,提供将数据库从传统编码迁移到 Unicode 的端到端解决方案。通过在整个迁移流程中为 DBA 提供指导并实现许多迁移任务的自动化,DMU 直观的用户界面极大简化了迁移流程并降低了对字符集迁移专业知识的要求。它采用可扩展的就地迁移架构,与传统的导出和导入迁移方法相比,可显著减少数据转换所需的工作和停机时间。对于迁移后的数据库和已经使用 Unicode 字符集的现有数据库,DMU 还提供了一种验证模式,可识别未正确用 Unicode 编码的数据,从而对数据库应用中的 Unicode 实现的潜在问题进行健康检查。
从 2.1 版开始,DMU 与 Oracle GoldenGate 复制技术结合使用,支持近乎零停机时间的迁移模型。结合使用 DMU 与 GoldenGate 12.1.2.1.0 或更高版本,您可以设置这样一个迁移过程,利用 DMU 的数据准备和就地转换功能,利用 GoldenGate 复制迁移过程中生产系统上发生的增量数据更改,从而有效地消除停机时间窗口需求。
思路
功能大致如下
1.全库扫描表字段,字段类型,字段值,字符编码
2.把对应表的字符编码从 gbk 转换为 utf8,如果之前字段的长度能够存储对应内容,就通过
3.如果之前字段的长度不能存储对应内容,比如存不下了,就会在 system.dum$exceptions 表里面添加对应表,行,列信息,这个字段就是需要扩展的字段
辅助查询
查询表信息
--查询表信息select * from dba_objectswhere upper(object_name) ='Student'
查询表对应的列信息
--查询表对应的列信息select * from dba_tab_columnswhere TABLE_NAME='Student'
查询兼容的异常信息
--查询兼容的异常信息select decode(sde.type,2,'exceed column',4,'exceed datatype',8,'invalid') as "DMU_TYPE",sde.row_id, --表行Idsde.obj#, --表的Idsde.intcol# --表列Idfrom system.dum$exceptions sdewhere sde.obj# = 1301018 --表对象Id
获取表对应行,列对应的值方法
create or replace function dmu_data_detail_f(p_object_id in number,p_column_id in number,p_rowid in varchar2)return varchar2 isl_data_detail varchar2(4000);l_data_query_sql VARCHAR2(2000);l_column_name VARCHAR2(128);l_table_name VARCHAR2(128);l_owner_name VARCHAR2(128);beginselect dtc.column_nameinto l_column_namefrom dba_objects do, dba_tab_columns dtcwhere do.object_name = dtc.TABLE_NAMEand do.OWNER = dtc.OWNERand dtc.COLUMN_ID = p_column_idand do.object_id = p_object_id;select object_name, ownerinto l_table_name, l_owner_namefrom dba_objectswhere object_id = p_object_id;l_data_query_sql := 'select ' || l_column_name || ' from ' ||l_owner_name || '.' || l_table_name ||' where rowid=''' || p_rowid || '''';--dbms_output.put_line(l_data_query_sql);execute immediate l_data_query_sqlinto l_data_detail;return(l_data_detail);end dmu_data_detail_f;
查询对应表不兼容的字段-记录数少时使用
--当查询结果记录数少时使用select owner as "用户",object_name as "对象名",object_type as "对象类型",COLUMN_NAME as "数据列",DATA_TYPE as "数据类型",DMU_TYPE as "扩展类型",dmu_data_detail_f(obj#, intcol#, row_id) as "例外数据"from (select do.owner,do.object_name,do.object_type,dto.COLUMN_NAME,dto.DATA_TYPE || '(' || dto.DATA_LENGTH || ')' as "DATA_TYPE",decode(sde.type,2,'exceed column',4,'exceed datatype',8,'invalid') as "DMU_TYPE",sde.row_id,sde.obj#,sde.intcol#from system.dum$exceptions sde,dba_objects do,dba_tab_columns dtowhere sde.obj# = do.object_idand sde.intcol# = dto.COLUMN_IDand do.object_name = dto.TABLE_NAMEand do.OWNER = dto.OWNERand upper(do.object_name) = upper('&p_table_name')--and sde.type = &p_dmu_typeorder by OWNER, object_name, COLUMN_NAME, TYPE);
查询对应表不兼容的字段-数据量大时使用
select '用户.表','字段名称',字段名称 ,255 data_length,cux_utf8_pub.count_byte_as_utf8(字段名称),rowid row_idfrom 用户.表 t where exists (select nullfrom system.dum$exceptions sde,dba_objects do,dba_tab_cols dtowhere sde.obj# = do.object_idand sde.intcol# = dto.internal_column_idand do.object_name = dto.table_nameand do.owner = dto.ownerand do.owner = '用户'and dto.column_name = '字段名称'and upper(do.object_name) = '表名称'and sde.row_id = t.rowid);
修改 sql
从上面得到对应的表和不兼容的字段,对应修改该字段的字段长度或类型即可,例如
-- =============================================-- Author: luoma-- Create date: 2019年4月9日15:48:25-- Description: 字符编码从 SIMPLIFIED CHINESE_CHINA.ZHS16GBK 修改为 utf-8,所以对应字段要进行扩容-- gbk和utf8 英文都占用1个字符,gbk中文占用2个字符,utf8占用3个,所以对应字段需要扩容为之前的1.5倍,这里我们修改为2倍-- =============================================alter table Studentmodify Name varchar2(383);
字符串截取
测试sql
-- =============================================-- Author: luoma-- Create date: 2019年4月11日10:50:24-- Description: 用utf8字符集截取对应表超过指定utf8编码长度的字符串-- =============================================declarel_ret_var varchar2(32767);--存储需要截取的字符串l_var varchar2(3); --存储截取的单个字符串l_len number := 0; --用于已经截取的utf8字符总长度l_dump number := 0; --存储单个utf8字符长度p_lengthb number := 25; --需要截取的字符长度begin--获取超过指定用UTF8字符集计算字符串字节数的数据for item in (select no,name from test_v_hwhao1 where (nvl(lengthb(name), 0) - nvl(length(name), 0)) + nvl(lengthb(name), 0) > p_lengthb )loop--初始化变量l_len := 0;l_ret_var := '';--处理超过指定长度的字段for i in 1 .. length(item.name)loop--截取单个字符串l_var := substr(item.name,i,1);--因为之前使用 gbk 编码,所以一个中文占用2个字符if (lengthb(l_var) = 2) then--utf8 一个中文字符长度为3l_dump := 3;else--utf8 其它字符长度为1l_dump := 1;end if;--已经总共统计了多少个 utf8 字符长度l_len := l_len + l_dump;--如果截取的长度还未达到需要截取的长度if(l_len <= p_lengthb) then--继续添加l_ret_var := l_ret_var || l_var;end if;--如果截取的长度达到了需要截取的长度if(l_len >= p_lengthb) then--把截取后的长度修改到表字段update test_v_hwhao1set name = l_ret_varwhere no = item.no;--提交修改commit;--退出循环exit;end if;end loop i;end loop;end;
测试表
测试完成后,结果应该为下图中红圈部分
select * from test_v_hwhao1 order by no
测试前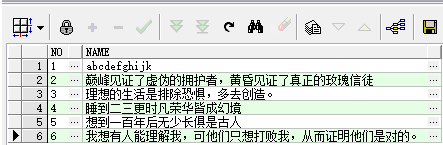
测试后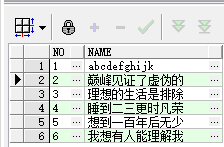
cux_utf8_pub
create or replace package body cux_utf8_pub is--用UTF8字符集计算字符串字节function count_byte_as_utf8(p_text in varchar2) return number isl_char_lenth number := 0;l_byte_lenth number := 0;beginl_char_lenth := nvl(length(p_text), 0);l_byte_lenth := nvl(lengthb(p_text), 0);return(l_byte_lenth - l_char_lenth) + l_byte_lenth;end count_byte_as_utf8;--用UTF8字符集截取字符串,确保最后一位不是乱码function substrb_use_utf8(p_text in varchar2, p_lengthb in number)return varchar2 isl_ret_var varchar2(32767);l_var varchar2(3);l_len number := 0;l_dump number := 0;beginif (count_byte_as_utf8(p_text) <= p_lengthb) thenreturn p_text;end if;for i in 1 .. length(p_text) loopl_var := substr(p_text, i, 1);if (lengthb(l_var) = 2) thenl_dump := 3;elsel_dump := 1;end if;l_len := l_len + l_dump;if (l_len <= p_lengthb) thenl_ret_var := l_ret_var || l_var;end if;if (l_len >= p_lengthb) thenreturn l_ret_var;end if;end loop i;return l_ret_var;end substrb_use_utf8;--用GBK字符集截取字符串,确保最后一位不是乱码function substrb_use_gbk(p_text in varchar2, p_lengthb in number)return varchar2 isl_last_string1 varchar2(4000);l_last_string2 varchar2(4000);beginif (lengthb(p_text) <= p_lengthb) thenreturn p_text;end if;--截取逻辑if (length(substrb(p_text, p_lengthb, 2)) = 1) then--截取少一位return substrb(p_text, 1, p_lengthb - 1);elsereturn substrb(p_text, 1, p_lengthb);end if;end substrb_use_gbk;procedure execute_substrb(p_owner in varchar2,p_table_name in varchar2,p_column_name in varchar2,p_debug_flag in varchar2 default 'Y') isl_bakup_sql varchar2(4000);l_datafix_sql varchar2(4000);l_count_length_sql varchar2(4000);l_extend_sql varchar2(4000);g_max_length number := 4000;l_length number;begin--截断处理for cur in (select t.rowid row_id, t.*, c.data_lengthfrom cux_utf8_substr_list t, dba_tab_cols cwhere t.table_name = c.table_nameand t.owner = c.ownerand t.column_name = c.column_nameand c.data_type = 'VARCHAR2'and t.owner = nvl(p_owner, t.owner)and t.column_name = nvl(p_column_name, t.column_name)and t.table_name = nvl(p_table_name, t.table_name)and convert_type = 'CUT') loopl_bakup_sql := 'insert into cux_utf8_substr_bak(table_name, owner, column_name, bak_data, bak_date, data_row_id)select ''' || cur.table_name || ''',''' ||cur.owner || ''',''' || cur.column_name || ''',' ||cur.column_name || ',sysdate, t.rowid row_id from ' ||cur.owner || '.' || cur.table_name ||' t where exists (select nullfrom system.dum$exceptions sde,dba_objects do,dba_tab_cols dtowhere sde.obj# = do.object_idand sde.intcol# = dto.internal_column_idand do.object_name = dto.table_nameand do.owner = dto.ownerand do.owner = upper(''' || cur.owner || ''')and dto.column_name = upper(''' ||cur.column_name || ''')and upper(do.object_name) = upper(''' ||cur.table_name || ''')and sde.row_id = t.rowid)';--dbms_output.put_line(l_sql);/*insert into cux_utf8_substr_bak(table_name, owner, column_name, bak_data, bak_date)select cur.table_name,cur.owner,cur.column_name,dmu_data_detail_f(obj#, intcol#, row_id),sysdatefrom system.dum$exceptions sde,dba_objects do,dba_tab_cols dtowhere sde.obj# = do.object_idand sde.intcol# = dto.internal_column_idand do.object_name = dto.table_nameand do.owner = dto.ownerand do.owner = upper(cur.owner)and dto.column_name = upper(cur.column_name)and upper(do.object_name) = upper(cur.table_name);*/l_datafix_sql := 'update ' || cur.owner || '.' || cur.table_name ||' t set ' || cur.column_name ||'=cux_utf8_pub.substrb_use_utf8(' || cur.column_name || ',' ||cur.data_length ||') where exists (select nullfrom system.dum$exceptions sde,dba_objects do,dba_tab_cols dtowhere sde.obj# = do.object_idand sde.intcol# = dto.internal_column_idand do.object_name = dto.table_nameand do.owner = dto.ownerand do.owner = upper(''' || cur.owner || ''')and dto.column_name = upper(''' ||cur.column_name || ''')and upper(do.object_name) = upper(''' ||cur.table_name || ''')and sde.row_id = t.rowid)';if (p_debug_flag = 'N') THENupdate cux_utf8_substr_list tset t.process_flag = 'P',t.process_date_start = sysdate,t.datafix_sql = l_datafix_sql,t.bakup_sql = l_bakup_sqlwhere rowid = cur.row_id;execute immediate l_bakup_sql;execute immediate l_datafix_sql;update cux_utf8_substr_list tset t.process_flag = 'S', t.process_date_end = sysdatewhere rowid = cur.row_id;commit;elsedbms_output.put_line('bakup:');dbms_output.put_line(l_bakup_sql);dbms_output.put_line('');dbms_output.put_line('datafix:');dbms_output.put_line(l_datafix_sql);end if;end loop cur;--扩展处理for cur in (select t.rowid row_id, t.*, c.data_lengthfrom cux_utf8_substr_list t, dba_tab_cols cwhere t.table_name = c.table_nameand t.owner = c.ownerand t.column_name = c.column_nameand c.data_type = 'VARCHAR2'and t.owner = nvl(p_owner, t.owner)and t.column_name = nvl(p_column_name, t.column_name)and t.table_name = nvl(p_table_name, t.table_name)and convert_type = 'EXT') loopl_count_length_sql := 'SELECT max(cux_utf8_pub.count_byte_as_utf8(' ||cur.column_name || ')) from ' || cur.owner || '.' ||cur.table_name || ' t' ||' where exists (select nullfrom system.dum$exceptions sde,dba_objects do,dba_tab_cols dtowhere sde.obj# = do.object_idand sde.intcol# = dto.internal_column_idand do.object_name = dto.table_nameand do.owner = dto.ownerand do.owner = upper(''' || cur.owner || ''')and dto.column_name = upper(''' ||cur.column_name || ''')and upper(do.object_name) = upper(''' ||cur.table_name || ''')and sde.row_id = t.rowid)';execute immediate l_count_length_sqlinto l_length;if (l_length > g_max_length) thendbms_output.put_line(cur.owner || '.' || cur.table_name || '.' ||cur.column_name || '扩展后的长度:' || l_length ||'超过4000');update cux_utf8_substr_list tset t.process_flag = 'E', t.process_date_start = sysdatewhere rowid = cur.row_id;commit;continue;end if;l_extend_sql := 'alter table ' || cur.owner || '.' || cur.table_name ||' modify ' || cur.column_name || ' VARCHAR2(' ||l_length || ')';l_bakup_sql := 'alter table ' || cur.owner || '.' || cur.table_name ||' modify ' || cur.column_name || ' VARCHAR2(' ||cur.data_length || ')';if (p_debug_flag = 'N') THENupdate cux_utf8_substr_list tset t.process_flag = 'P',t.process_date_start = sysdate,t.extend_sql = l_extend_sql,t.bakup_sql = l_bakup_sqlwhere rowid = cur.row_id;execute immediate l_extend_sql;update cux_utf8_substr_list tset t.process_flag = 'S', t.process_date_end = sysdatewhere rowid = cur.row_id;commit;elsedbms_output.put_line('extend sql:');dbms_output.put_line(l_extend_sql);dbms_output.put_line('bakup_sql:');dbms_output.put_line(l_bakup_sql);end if;end loop cur;end execute_substrb;procedure get_quick_query_sql(p_owner in varchar2 default null,p_table_name in varchar2,p_column_name in varchar2 default null) isl_sql varchar2(4000);beginfor cur in (select dto.data_length,do.object_name,do.owner,dto.column_name,do.object_id,dto.internal_column_idfrom dba_objects do,dba_tab_cols dto,cux_utf8_error_info cuwhere do.object_name = dto.table_nameand do.owner = dto.ownerand do.owner = cu.ownerand dto.column_name = cu.column_nameand do.object_name = cu.table_nameand cu.owner = nvl(upper(p_owner), cu.owner)and cu.table_name = upper(p_table_name)and cu.column_name =nvl(upper(p_column_name), cu.column_name)) loopl_sql := 'select ''' || cur.owner || '.' || cur.object_name ||''',''' || cur.column_name || ''',' || cur.column_name || ' ,' ||cur.data_length ||' data_length,cux_utf8_pub.count_byte_as_utf8(' ||cur.column_name || '),rowid row_id from ' || cur.owner || '.' ||cur.object_name || ' t where exists (select nullfrom system.dum$exceptions sde,dba_objects do,dba_tab_cols dtowhere sde.obj# = do.object_idand sde.intcol# = dto.internal_column_idand do.object_name = dto.table_nameand do.owner = dto.ownerand do.owner = ''' || cur.owner || '''and dto.column_name = ''' || cur.column_name || '''and upper(do.object_name) = ''' || cur.object_name || '''and sde.row_id = t.rowid);';dbms_output.put_line(l_sql);dbms_output.put_line('');end loop cur;end get_quick_query_sql;end cux_utf8_pub;