开发环境
| 名称 | 版本 |
|---|---|
| 操作系统 | CentOS Linux release 7.8.2003 (Core) |
| Redis | 5.0.4 |
| XSheel | 7 |
| XFtp | 公测版 7 |
技术的分类
| 分类 | 代表 |
|---|---|
| 解决功能性问题 | Java,JSP,RDBMS,Tomcat,HTML,Linux,JDBC,SVN |
| 解决扩展性问题 | Struts,Spring,SpringMVC,Hibernate,Mybatis |
| 解决性能的问题 | NoSQL,Java 线程,Hadoop,Nginx,MQ,ElasticSearch |
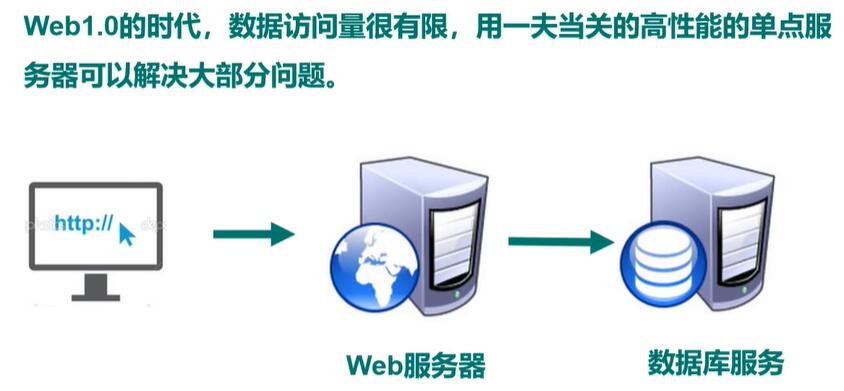
NoSQL 数据库简介
NoSQL 数据库背景
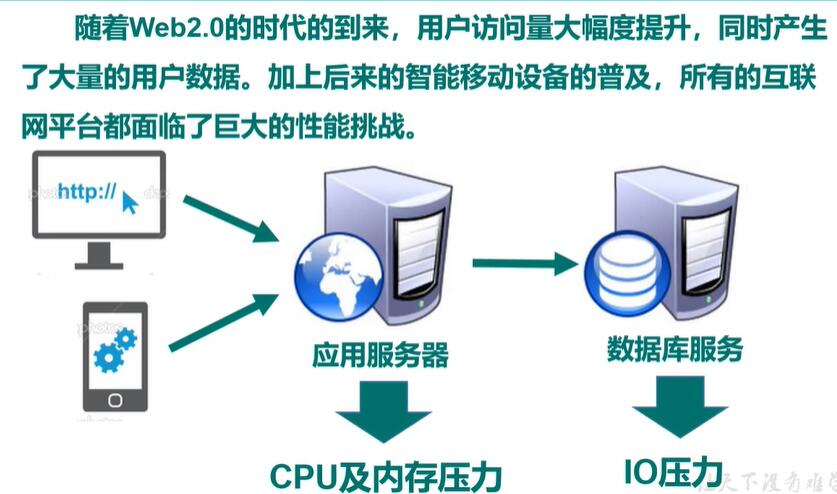
案例:解决 CPU 及内存压力

案例:解决 IO 压力
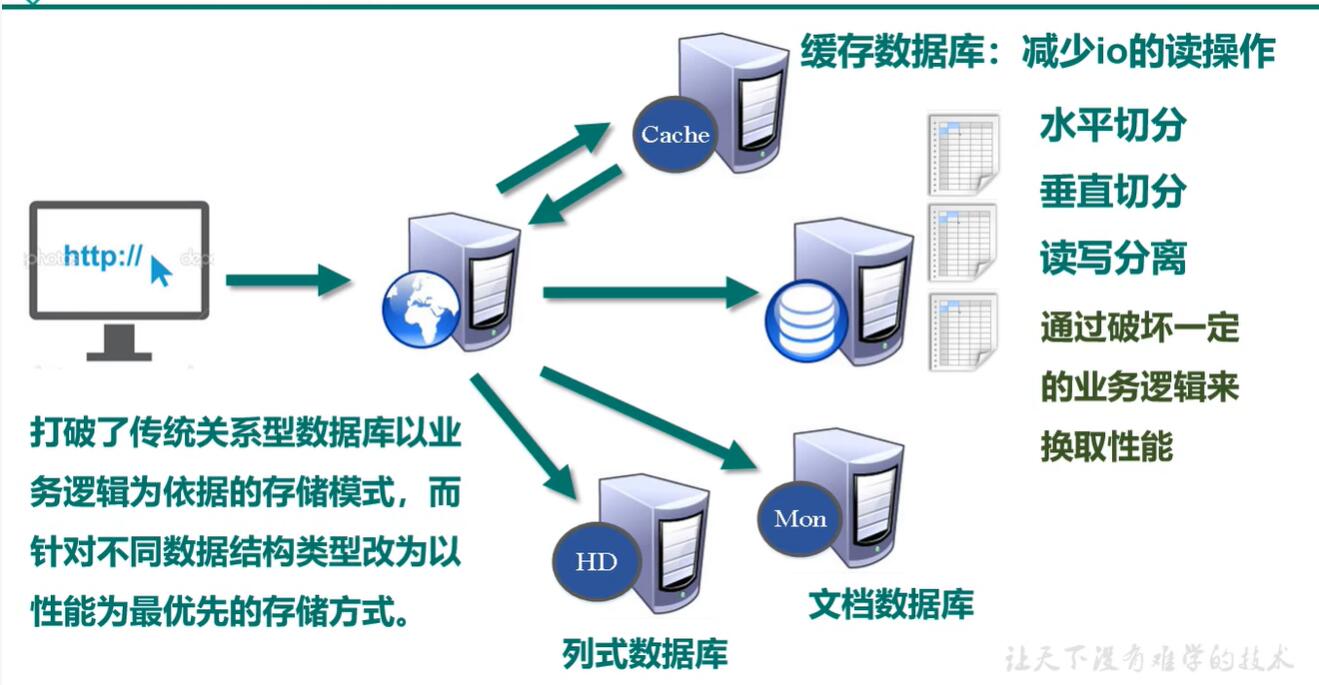
NoSQL 数据库概述
NoSQL(Not Only SQL),意即”不仅仅是 SQL”,泛指非关系型数据库。
NoSQL 不依赖业务逻辑方式存储,而以简单的 key-value 模式存储。
因此大大增加了数据库的扩展能力。
不遵循 SQL 标准。
不支持 ACID(事务的四个特性)。
远超于 SQL 的性能。
NoSQL 适用场景
1.对数据高并发的读写。
2.海量数据的读写。
3.对数据库高可扩展性的。
NoSQL 不适用场景
1.需要事务支持。
2.基于 sql 的结构化查询存储,处理复杂的关系,需要即席查询(条件查询)。
几种缓存数据库介绍
Memcached
1.很早出现的 NoSql 数据库
2.数据都在内存中,一般不持久化
3.支持简单的 key-value 模式
4.一般是作为缓存数据库辅助持久化的数据库
5.多线程+锁(memcached)
Redis
1.几乎覆盖了 Memcached 的绝大部分功能
2.数据都在内存中,支持持久化,主要用作备份恢复
3.除了简单的 key-value 模式,还支持多种数据结构的存储,比如 lsit,set,hash,zset 等。
4.一般是作为缓存数据库辅助持久化的数据库。
5.单线程+多路IO复用(Redis)
mongoDB
1.高性能、开源、模式自由(schema free)的文档型数据库。
2.数据都在内存中,如果内存不足,支持先进先出(环形队列)。
3.虽然是 key-value 模式,但是对 value(尤其是 json)提供把不常用的数据保存到硬盘提供了丰富的查询功能。
4.支持二进制数据及大型对象。
5.可根据数据的特点替代 RDBMS,成为独立的数据库,或者配合 RDBMS。
HBase
HBase 是 Hadoop 项目中的数据库。
它用于需要对大量数据进行随机、实时的读写操作场景中。
HBase 的目标就是处理数据量非常庞大的表,可以用普通的计算机处理超过 10 亿行数据,还可以处理数百万列元素的数据表。
Cassandra
Apache Cassandra 是一款免费的开源 NoSQL 数据库。
其设计的目的在于管理由大量商用服务器构建起来的庞大集群上的海量数据集(数据量通常达到 PB 级别)。
在众多显著的特性中,Cassandra 最为卓越的长处是对写入及读取操作进行规模调整,而且其不强调主集群设计的思路能够以相对直观的方式简化各集群的创建与扩展流程。
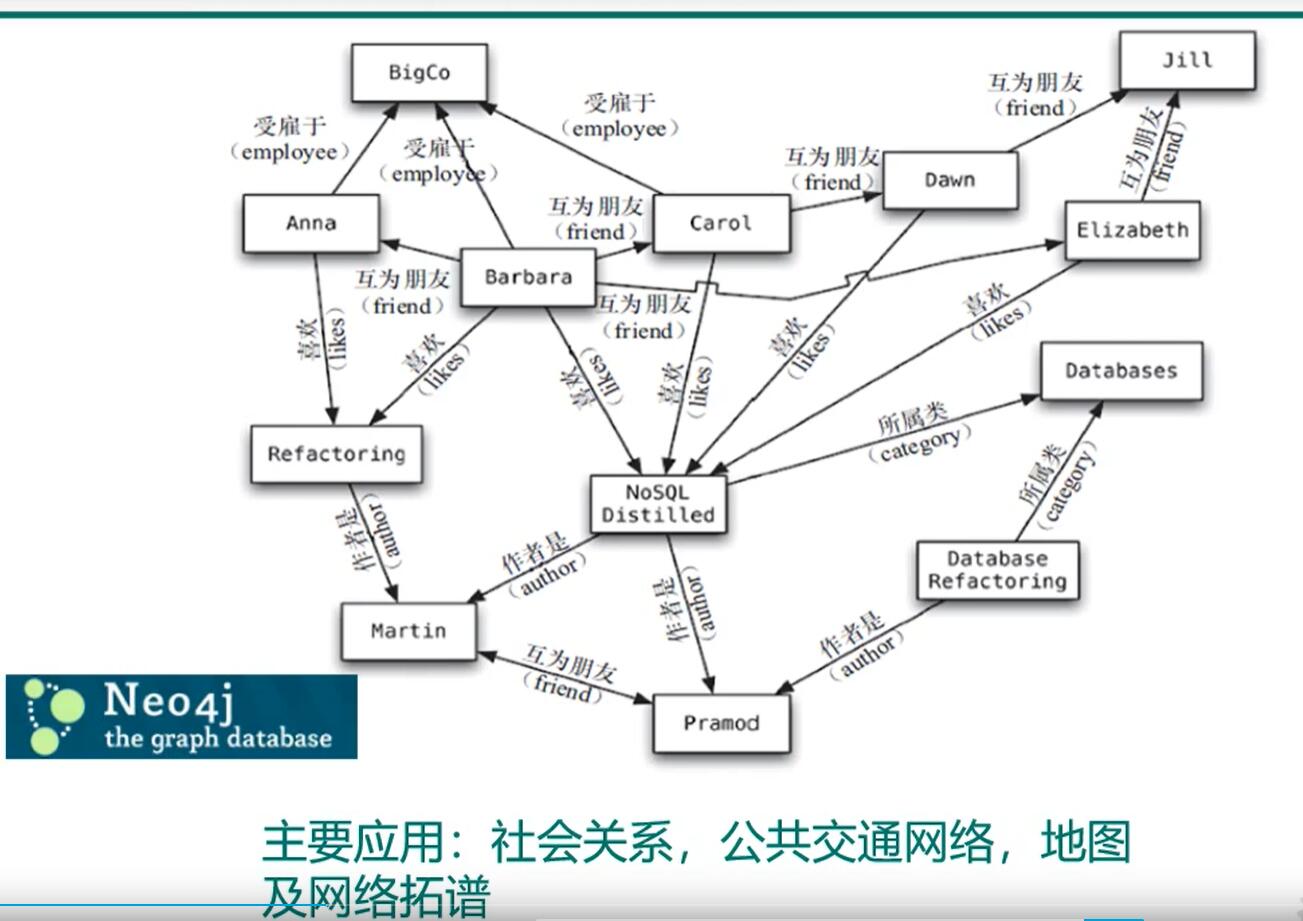
Neo4j
主要应用:社会关系,公共交通网络,地图及网络拓扑。
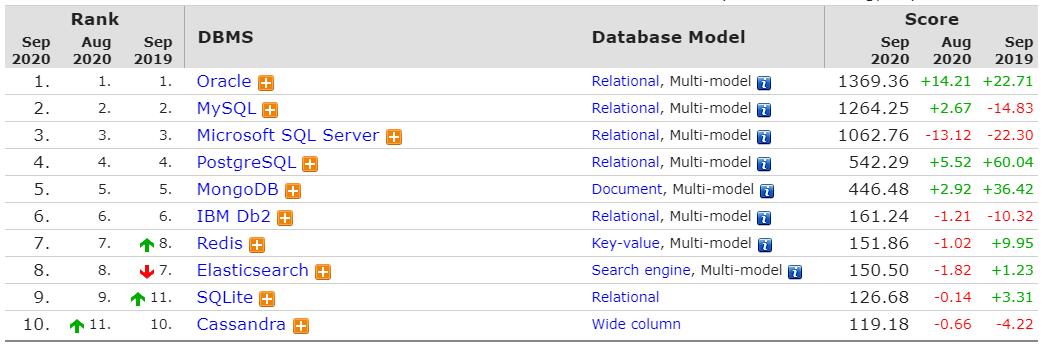
数据库排名
https://db-engines.com/en/ranking
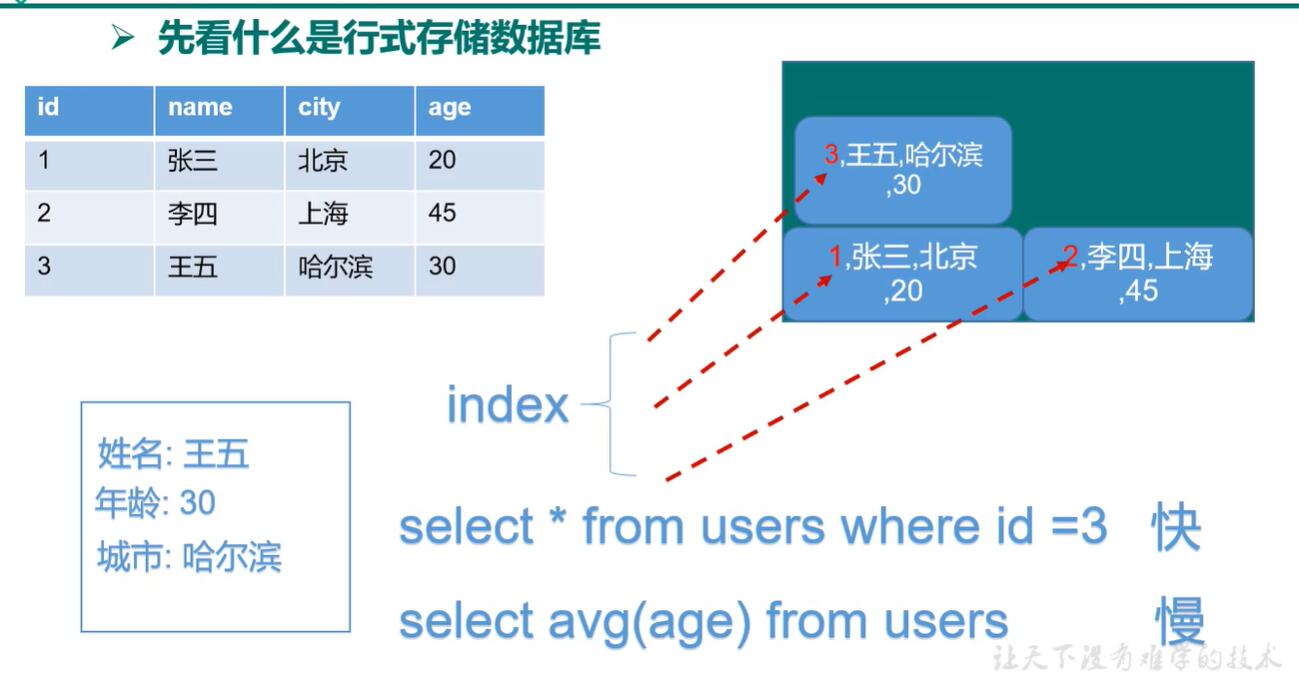
列式数据库
行式数据库
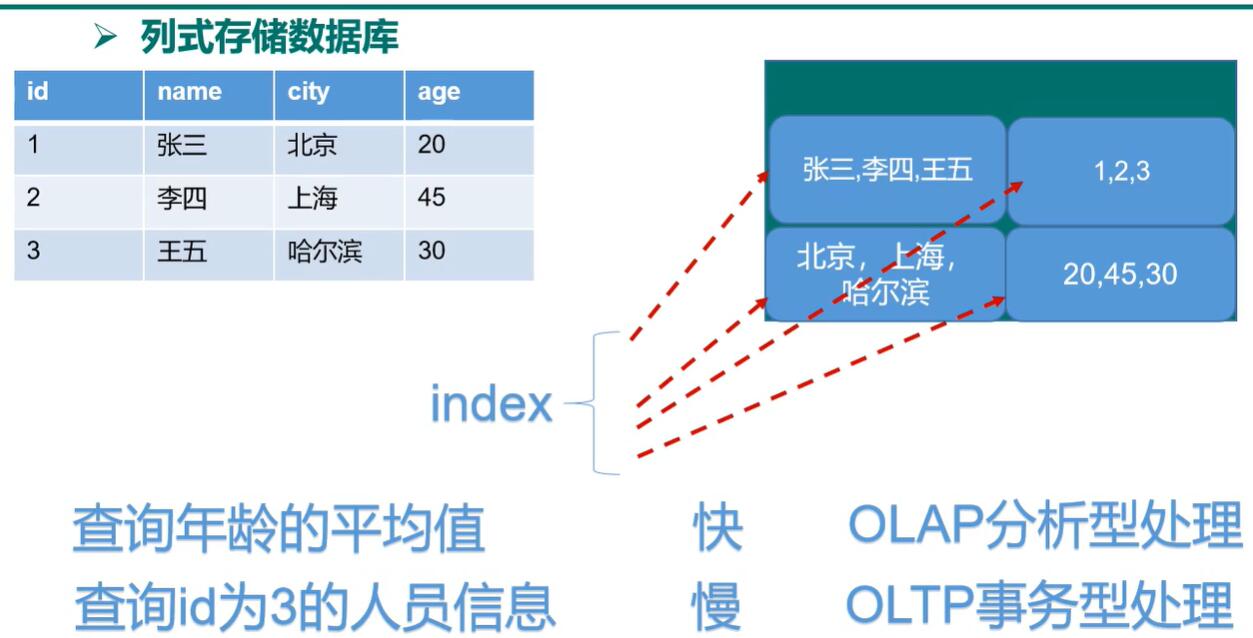
列式数据库
Redis 简介安装
Redis 介绍
Redis 是一个开源的 key-value 存储系统。
和 Memcached 类似,它支持存储的 value 类型相对更多。
包括 string(字符串)、list(链表)、set(集合)、zset(sorted set--有序集合)、hash(哈希类型)。
这些数据类型都支持 push/pop,add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
在此基础上,Redis 支持各种不同方式的排序。与 Memcached 一样,为了保证效率,数据都是缓存在内存中。
区别是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave(主从)同步。
Redis 应用场景
1.配合关系型数据库做高速缓存
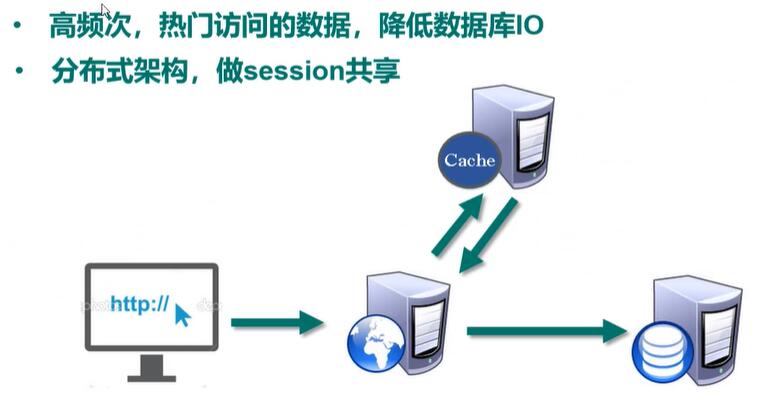
2.由于其拥有持久化能力,利用其多样的数据结构存储特定的数据
Redis 下载
https://www.redis.net.cn/download/
得到安装包 redis-5.0.4.tar.gz
Redis 安装
1.安装包放入 /opt 目录
redis-5.0.4.tar.gz 放入 /opt 目录
2.解压
解压 tar -zxvf redis-5.0.4.tar.gz
3.进入目录
cd redis-5.0.4
4.在目录下执行 make 命令
make
gcc:命令未找到
报下面的错误
[root@luoma redis-5.0.4]# makecd src && make allmake[1]: 进入目录“/opt/redis-5.0.4/src”CC Makefile.depmake[1]: 离开目录“/opt/redis-5.0.4/src”make[1]: 进入目录“/opt/redis-5.0.4/src”rm -rf redis-server redis-sentinel redis-cli redis-benchmark redis-check-rdb redis-check-aof *.o *.gcda *.gcno *.gcov redis.info lcov-html Makefile.dep dict-benchmark(cd ../deps && make distclean)make[2]: 进入目录“/opt/redis-5.0.4/deps”(cd hiredis && make clean) > /dev/null || true(cd linenoise && make clean) > /dev/null || true(cd lua && make clean) > /dev/null || true(cd jemalloc && [ -f Makefile ] && make distclean) > /dev/null || true(rm -f .make-*)make[2]: 离开目录“/opt/redis-5.0.4/deps”(rm -f .make-*)echo STD=-std=c99 -pedantic -DREDIS_STATIC='' >> .make-settingsecho WARN=-Wall -W -Wno-missing-field-initializers >> .make-settingsecho OPT=-O2 >> .make-settingsecho MALLOC=jemalloc >> .make-settingsecho CFLAGS= >> .make-settingsecho LDFLAGS= >> .make-settingsecho REDIS_CFLAGS= >> .make-settingsecho REDIS_LDFLAGS= >> .make-settingsecho PREV_FINAL_CFLAGS=-std=c99 -pedantic -DREDIS_STATIC='' -Wall -W -Wno-missing-field-initializers -O2 -g -ggdb -I../deps/hiredis -I../deps/linenoise -I../deps/lua/src -DUSE_JEMALLOC -I../deps/jemalloc/include >> .make-settingsecho PREV_FINAL_LDFLAGS= -g -ggdb -rdynamic >> .make-settings(cd ../deps && make hiredis linenoise lua jemalloc)make[2]: 进入目录“/opt/redis-5.0.4/deps”(cd hiredis && make clean) > /dev/null || true(cd linenoise && make clean) > /dev/null || true(cd lua && make clean) > /dev/null || true(cd jemalloc && [ -f Makefile ] && make distclean) > /dev/null || true(rm -f .make-*)(echo "" > .make-cflags)(echo "" > .make-ldflags)MAKE hirediscd hiredis && make staticmake[3]: 进入目录“/opt/redis-5.0.4/deps/hiredis”gcc -std=c99 -pedantic -c -O3 -fPIC -Wall -W -Wstrict-prototypes -Wwrite-strings -g -ggdb net.cmake[3]: gcc:命令未找到make[3]: *** [net.o] 错误 127make[3]: 离开目录“/opt/redis-5.0.4/deps/hiredis”make[2]: *** [hiredis] 错误 2make[2]: 离开目录“/opt/redis-5.0.4/deps”make[1]: [persist-settings] 错误 2 (忽略)CC adlist.o/bin/sh: cc: 未找到命令make[1]: *** [adlist.o] 错误 127make[1]: 离开目录“/opt/redis-5.0.4/src”make: *** [all] 错误 2
这是因为 redis 是 C 语言和 C++ 语言写的,linux 环境缺少这两个组件
解决方案1(能上网的情况)
yum install gccyum install gcc-c++
解决方案2-离线安装 gcc
这里注意我的 CentOS 版本是 CentOS Linux release 7.8.2003 (Core)
rpm 包下载
搜索下载下面的所有包放到文件夹 rpmgcc 中,每个包之间都有互相依赖
autogen-libopts-5.18-5.el7.x86_64.rpmcpp-4.8.5-16.el7.x86_64.rpmgcc-4.8.5-16.el7.x86_64.rpmgcc-c++-4.8.5-16.el7.x86_64.rpmglibc-devel-2.17-196.el7.x86_64.rpmglibc-headers-2.17-196.el7.x86_64.rpmkernel-headers-3.10.0-693.el7.x86_64.rpmkeyutils-1.5.8-3.el7.x86_64.rpmkrb5-devel-1.15.1-8.el7.x86_64.rpmlibcom_err-devel-1.42.9-10.el7.x86_64.rpmlibmpc-1.0.1-3.el7.x86_64.rpmlibselinux-devel-2.5-11.el7.x86_64.rpmlibsepol-devel-2.5-6.el7.x86_64.rpmlibstdc++-devel-4.8.5-16.el7.x86_64.rpmlibverto-devel-0.2.5-4.el7.x86_64.rpmmpfr-3.1.1-4.el7.x86_64.rpmntp-4.2.6p5-25.el7.centos.2.x86_64.rpmntpdate-4.2.6p5-25.el7.centos.2.x86_64.rpmopenssl-1.0.2k-8.el7.x86_64.rpmopenssl098e-0.9.8e-29.el7.centos.3.x86_64.rpmopenssl-devel-1.0.2k-8.el7.x86_64.rpmopenssl-libs-1.0.2k-8.el7.x86_64.rpmpkgconfig-0.27.1-4.el7.x86_64.rpmtcl-8.5.13-8.el7.x86_64.rpmzlib-1.2.7-17.el7.x86_64.rpmzlib-devel-1.2.7-17.el7.x86_64.rpm
拷贝到 linux 下的 /opt 目录
进入到 cd /opt/rpmgcc 目录
执行 rpm -Uvh *.rpm --nodeps --force
命令解析
--nodeps:不检查依赖关系--force:强制安装-ivh:安装-Uvh:升级
安装完成之后使用如下命令查看版本
gcc -vg++ -v
5.再次执行 make 命令
(1)编译
先执行 make distclean,否则会报下面的错误
zmalloc.h:50:31: 致命错误:jemalloc/jemalloc.h:没有那个文件或目录#include <jemalloc/jemalloc.h>
再执行 make,等待编译,最后看到下面的提示,安装成功。
Hint: It's a good idea to run 'make test' ;)make[1]: 离开目录“/opt/redis-5.0.4/src”
(2)安装
输入 make install
cd src && make installmake[1]: 进入目录“/opt/redis-5.0.4/src”CC Makefile.depmake[1]: 离开目录“/opt/redis-5.0.4/src”make[1]: 进入目录“/opt/redis-5.0.4/src”Hint: It's a good idea to run 'make test' ;)INSTALL installINSTALL installINSTALL installINSTALL installINSTALL installmake[1]: 离开目录“/opt/redis-5.0.4/src”
安装成功
Redis 相关目录
查看默认相关目录:usr/local/bin
| 目录名称 | 说明 |
|---|---|
| Redis-benchmark | 性能测试工具,可以在自己本子运行,看看自己本子性能如何(服务启动起来后执行) |
| Redis-check-aof | 修复有问题的 AOF 文件,rdb 和 aof 后面讲 |
| Redis-check-dump | 修复有问题的 dump.rdb 文件 |
| Redis-sentinel | Redis 集群使用 |
| redis-server | Redis 服务器启动命令 |
| redis-cli | 客户端,操作入口 |
Redis 操作
启动
前台启动:redis-server
后台启动:
1.备份 redis.conf:拷贝一份 redis.conf 到其它目录。
[root@luoma ~]# mkdir /opt/myRedis[root@luoma ~]# cp /opt/redis-5.0.4/redis.conf /opt/myRedis/redis.conf[root@luoma ~]# cd /opt/myRedis/
2.修改 redis.conf 文件将里面 daemonize no 改成 yes,让服务在后台启动。
3.启动命令:执行 redis-server /myRedis/redis.conf。
开启/关闭客户端
| 作用 | 命令 | 说明 |
|---|---|---|
| 开启客户端 | redis-cli |
例如:输入redis-cli,显示 127.0.0.1:6379> |
| 开启客户端(多端口) | redis-cli -h 127.0.0.1 -p 6379 |
|
| 查看是否连接成功 | ping |
例如:输入 ping,显示 PONG 为连接成功 |
| 单实例关闭客户端 | redis-cli shutdown |
|
| 多实例关闭客户端 | redis-cli -p 6379 shutdown |
|
| 进入终端后关闭 | shutdown |
例如:输入 shutdown,出现 not connected> 即已经关闭。 |
| 退出客户端 | exit |
退出客户端 |
数据库及密码
默认 16 个数据库,类似数组下标从 0 开始,初始默认使用 0 号库。
使用命令 select <dbid> 来切换数据库。如: select 8
127.0.0.1:6379> set a aOK127.0.0.1:6379> get a"a"127.0.0.1:6379> select 1OK127.0.0.1:6379[1]> get a(nil)127.0.0.1:6379[1]> select 0OK127.0.0.1:6379> get a"a"
统一密码管理,所有库都是同样密码,要么都 OK 要么一个也连接不上。
redis 是单线程+多路 IO 复用技术
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用 select 和 poll 函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
串行 vs 多线程+锁(memcached) vs 单线程+多路IO复用(Redis)
阻塞 IO:给女神发一条短信,说我来找你了,然后就默默的一直等着女神下楼,这个期间除了等待你不会做其他事情,属于备胎做法。
非阻塞 IO:给女神发短信,如果不回,接着再发,一直发到女神下楼,这个期间你除了发短信等待不会做其他事情,属于专一做法。
IO 多路复用,是找一个宿管大妈来帮你监视下楼的女生,这个期间你可以些其他的事情.例如可以顺便看看其他妹子,玩玩王者荣耀,上个厕所等等。IO 复用又包括 select,poll,epoll 模式.那么它们的区别是什么?
1.select 大妈,每一个女生下楼,select大妈都不知道这个是不是你的女神,她需要一个一个询问,并且select大妈能力还有限,最多一次帮你监视 1024 个妹子。
2.poll 大妈,不限制盯着女生的数量,只要是经过宿舍楼门口的女生,都会帮你去问是不是你女神。
3.epoll 大妈,不限制盯着女生的数量,并且也不需要一个一个去问.那么如何做呢?epoll 大妈会为每个进宿舍楼的女生脸上贴上一个大字条,上面写上女生自己的名字,只要女生下楼了,epoll 大妈就知道这个是不是你女神了,然后大妈再通知你。
Redis 数据类型
| 作用 | 命令 | 说明 |
|---|---|---|
| 查询当前库的所有键 | keys * |
|
| 判断某个键是否存在 | exists <key> |
例如:exists a |
| 查看键的类型 | type <key> |
例如:type a |
| 删除某个键 | del <key> |
例如:del a |
| 为键值设置过期时间,单位:秒 | expire a 10 |
例如:expire a 100 |
| 查看还有多少秒过期,-1表示永不过期,-2表示已过期 | ttl <key> |
例如:ttl a |
| 查看当前数据库 key 的数量 | dbsize |
|
| 清空当前库 | flushdb |
|
| 通杀全部库 | flushall |
慎重使用 |
string
原子性。
所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。
(1)在单线程中, 能够在单条指令中完成的操作都可以认为是”原子操作”,因为中断只能发生于指令之间。
(2)在多线程中,不能被其它进程(线程)打断的操作就叫原子操作。
Redis 单命令的原子性主要得益于 Redis 的单线程。
| 作用 | 命令 | 说明 |
|---|---|---|
| 查询对应键值 | get <key> |
例如:get a |
| 设置键值对 | set <key> <value> |
例如:set a a |
| 将给定的 <value> 追加到原值的末尾 | append <key> <value> |
例如:append a aaaa |
| 获得值的长度 | strlen <key> |
例如:strlen a |
| 只有在 key 不存在时,设置 value 的值 | setnx <key> <value> |
例如:setnx b b |
| 将 key 中存储的数字值增 1,空值新增值为 1 | incy <key> |
例如:set c 1,incy c |
| 将 key 中存储的数字值减 1,空值新增值为 -1 | decr <key> |
例如:decr c |
| 将 key 中存储的数字值增减。自定义步长。 | incrby / decrby <key> <步长> |
例如:incrby c 10,incy c,get c |
| 同时设置一个或多个 key-value 对 | mset <key1> <value1> <key2> <value2> |
例如:mset k1 v1 k2 v2 |
| 同时获取一个或多个 key-value 对 | mget <key1> <key2> |
例如:mget k1 k2 |
| 同时这种一个或多个 key-value 对,当且仅当 key 不存在 | msetnx <key1> <value1> <key2> <value2> |
例如:msetnx k3 v3 k4 v4 |
| 获得值的范围 | getrange <key> <起始位置> <结束位置> |
例如:getrange k1 0 2 |
| 用 <value> 覆写 <key> 说存储的字符,从 <起始位置> 开始 | setrange <key> <起始位置> <value> |
例如:setrange k1 1 abc |
| 设置键值的同时,设置过期时间 | setex <key> <过期时间> <value> |
例如:setex k1 10 v11111 |
| 以新换旧,设置新值的同时获得旧值 | getset <key> <value> |
例如:getset k1 v1-aaaa |
list
单键多值。
redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
| 作用 | 命令 | 说明 |
|---|---|---|
| 从左边/右边插入一个或多个值 | lpush/rpush <key> <value1> <value2> |
例如:lpush list1 str1 str2 str3 |
| 从左边/右边吐出一个值 | lpop/rpop <key> |
例如:lpop list1 |
| 从 <key1> 列表右边吐出一个值添加到 <key2> 的左边 | rpoplpush <key1> <key2> |
例如:rpoplpush list1 list2 |
| 按照索引下标获得元素(从左到右) | lrange <key> <start> <stop> |
例如:lrange list1 0 -1 |
| 按照索引下标获得元素(从左到右) | lindex <key> <index> |
例如:lindex list1 1 |
| 获得列表长度 | llen <key> |
例如:llen list1 |
| 在 <value> 的后面插入 <newvalue> 值 | linsert <key> after <value> <newvalue> |
例如:linsert list1 after str2 str2222 |
| 从左边删除 n 个 value(从左到右) | lrem <key> <n> <value> |
例如:lrem list1 1 2 |
set
redis set 对外提供的功能与 list 类似是一个列表的功能,特殊之处在于 set 是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。
redis的 set 是 string 类型的无序集合。它底层其实是一个 value 为 null 的 hash 表,所以添加,删除,查找的复杂度都是 O(1)。
| 作用 | 命令 | 说明 |
|---|---|---|
| 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。 | sadd <key> <value1> <value2> ..... |
例如:sadd set1 str1 str2 str3 str4 |
| 取出该集合的所有值 | smembers <key> |
例如:smembers set1 |
| 判断集合 <key> 是否为含有该 <value> 值,有返回 1,没有返回 0 | sismember <key> <value> |
例如:sismember set1 str1 |
| 返回该集合的元素个数 | scard <key> |
例如:srem set1 |
| 删除集合中的某个元素 | srem <key> <value1> <value2>.... |
例如:srem set1 str1 |
| 随机从该集合中吐出一个值 | spop <key> |
例如:spop set1 |
| 随机从该集合中取出 n 个值(不会从集合中删除) | srandmember <key> <n> |
例如:srandmember set1 2 |
| 返回两个集合的交集元素 | sinter <key1> <key2> |
例如:sinter set1 set2 |
| 返回两个集合的并集元素 | sunion <key1> <key2> |
例如:sunion set1 set2 |
| 返回两个集合的差集元素 | sdiff <key1> <key2> |
例如:sdiff set1 set2 |
hash
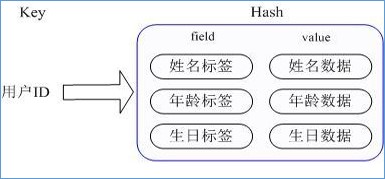
redis hash 是一个键值对集合。
redis hash是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
类似 Java 里面的 Map<String,String>
用户 ID 为查找的 key,存储的 value 用户对象包含姓名,年龄,生日等信息,如果用普通的 key/value 结构来存储,主要有以下2种存储方式:
每次修改用户的某个属性需要,先反序列化改好后再序列化回去。开销较大。
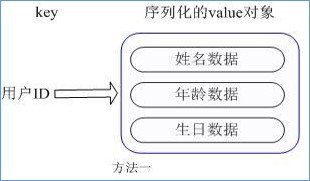
用户ID数据冗余
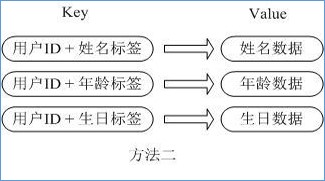
通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
| 作用 | 命令 | 说明 |
|---|---|---|
| 给<key>集合中的 <field>键赋值<value> | hset <key> <field> <value> |
例如:hset hash1 id 1 |
| 从<key1>集合<field> 取出 value | hget <key1> <field> |
例如:hget hash1 id |
| 批量设置 hash 的值 | hmset <key1> <field1> <value1> <field2> <value2>... |
例如:hmset userInfo user:1010:username admin user:1010:password 1234 |
| 查看哈希表 key 中,给定域 field 是否存在 | hexists key <field> |
例如:hexists userInfo user:1010:username |
| 列出该 hash 集合的所有 field | hkeys <key> |
例如:hkeys userInfo |
| 列出该 hash 集合的所有 value | hvals <key> |
例如:`` |
| 为哈希表 key 中的域 field 的值加上增量 increment | hincrby <key> <field> <increment> |
例如:hset userInfo user:1010:age 25,hincrby userInfo user:1010:age 10 |
| 将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 | hsetnx <key> <field> <value> |
例如:hsetnx userInfo user:1010:age 0 |
zset (sorted set)
redis 有序集合 zset 与普通集合 set 非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score) ,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
| 作用 | 命令 | 说明 |
|---|---|---|
| 将一个或多个 member 元素及其 score 值加入到有序集 key 当中 | zadd <key> <score1> <value1> <score2> <value2>... |
例如:zadd zset1 100 a 20 b 1 x 500 abc |
| 返回有序集 key 中,下标在<start> <stop>之间的元素。带WITHSCORES,可以让分数一起和值返回到结果集。 | zrange <key> <start> <stop> [WITHSCORES] |
例如:zrangebyscore zset1 1 200 |
| 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。 | zrangebyscore key min max [withscores] [limit offset count] |
例如:`` |
| 同上,改为从大到小排列。 | zrevrangebyscore key max min [withscores] [limit offset count] |
例如:zrevrangebyscore zset1 200 1 |
| 为元素的score加上增量 | zincrby <key> <increment> <value> |
例如:zincrby zset1 100 1 |
| 删除该集合下,指定值的元素 | zrem <key> <value> |
例如:zrem zset 100 |
| 统计该集合,分数区间内的元素个数 | zcount <key> <min> <max> |
例如:zcount zset1 1 200 |
| 返回该值在集合中的排名,从0开始。 | zrank <key> <value> |
例如:zrank zset1 abc |
redis 相关配置
| 配置 | 说明 |
|---|---|
| 大小写 | 大小写不敏感 |
| include | 类似 jsp 中的 include,多实例的情况可以把公用的配置文件提取出来 |
| ip 地址的绑定 bind | 默认情况 bind=127.0.0.1只能接受本机的访问请求。不写的情况下,无限制接受任何ip地址的访问。生产环境肯定要写你应用服务器的地址。如果开启了 protected-mode,那么在没有设定 bind ip 且没有设密码的情况下,Redis 只允许接受本机的响应。 |
| tcp-backlog | 可以理解是一个请求到达后至到接受进程处理前的队列。backlog 队列总和=未完成三次握手队列 + 已经完成三次握手队列。高并发环境 tcp-backlog 设置值跟超时时限内的 Redis 吞吐量决定 |
| timeout | 一个空闲的客户端维持多少秒会关闭,0 为永不关闭 |
| tcp keepalive | 对访问客户端的一种心跳检测,每个 n 秒检测一次,官方推荐设置为 60 秒 |
| daemonize | 是否为后台进程 |
| pidfile | 存放 pid 文件的位置,每个实例会产生一个不同的 pid 文件 |
| log level | 四个级别根据使用阶段来选择,生产环境选择 notice 或者 warning |
| log level | 日志文件名称 |
| syslog | 是否将 Redis 日志输送到 linux 系统日志服务中 |
| syslog-ident | 日志的标志 |
| syslog-facility | 输出日志的设备 |
| database | 设定库的数量,默认 16 |
| security | 在命令行中设置密码 |
| maxclient | 最大客户端连接数 |
| maxmemory | 设置 Redis 可以使用的内存量。一旦到达内存使用上限,Redis 一旦到达内存使用上限,Redis 将会试图移除内部数据,移除规则可以通过 maxmemory-policy 来指定。如果 Redis 无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么 Redis 则会针对那些需要申请内存的指令返回错误信息,比如 SET、LPUSH 等。 |
| Maxmemory-policy | volatile-lru:使用 LRU 算法移除 key,只对设置了过期时间的键。allkeys-lru:使用LRU算法移除 key。volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键。allkeys-random:移除随机的 key。volatile-ttl:移除那些TTL值最小的 key,即那些最近要过期的 key。noeviction:不进行移除。针对写操作,只是返回错误信息。 |
| Maxmemory-samples | 设置样本数量,LRU 算法和最小 TTL 算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小。 |
一般设置3到7的数字,数值越小样本越不准确,但是性能消耗也越小。 |
计量单位说明
cat /opt/myRedis/redis.conf | grep 1k -C 1
# Note on units: when memory size is needed, it is possible to specify# it in the usual form of 1k 5GB 4M and so forth:## 1k => 1000 bytes# 1kb => 1024 bytes# 1m => 1000000 bytes# 1mb => 1024*1024 bytes# 1g => 1000000000 bytes# 1gb => 1024*1024*1024 bytes## units are case insensitive so 1GB 1Gb 1gB are all the same.a
Redis 的 Java 客户端 Jedis
1.引入Jedis所需要的 jar 包
commons-pool2-2.4.2.jarjedis-2.8.1.jar
2.使用 Windows 环境下 Eclipse 连接虚拟机中的 Redis 注意事项
(1)禁用 Linux 的防火墙:Linux(CentOS7)里执行命令 : systemctl stop firewalld.service
(2)redis.conf 中注释掉 bind 127.0.0.1 ,然后 protected-mode no。
vim /opt/myRedis/redis.conf
#bind 127.0.0.1protected-mode no
3.Jedis 测试连通性
package com.guigu.bean;import redis.clients.jedis.Jedis;public class RedisTest {public static void main(String[] args) {//连接本地的 Redis 服务Jedis jedis = new Jedis("192.168.241.128",6379);//查看服务是否运行,打出 pong 表示OKSystem.out.println("connection is OK=======>:" + jedis.ping());}}
运行,控制台输出 connection is OK=======>:PONG
Redis 中事务的定义
Redis 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
Redis 事务的主要作用就是串联多个命令防止别的命令插队。
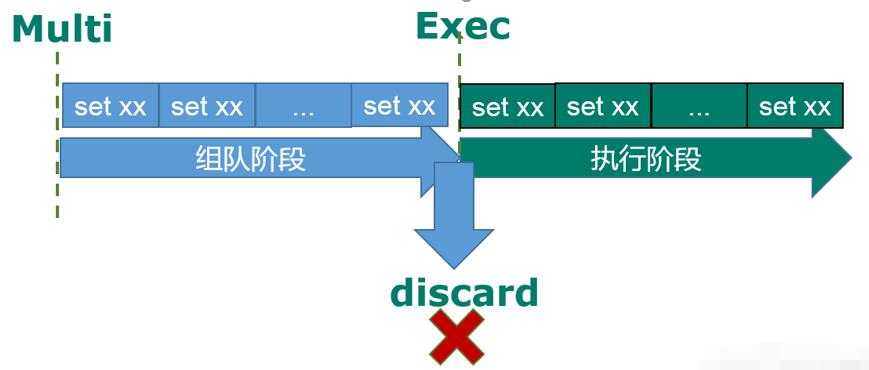
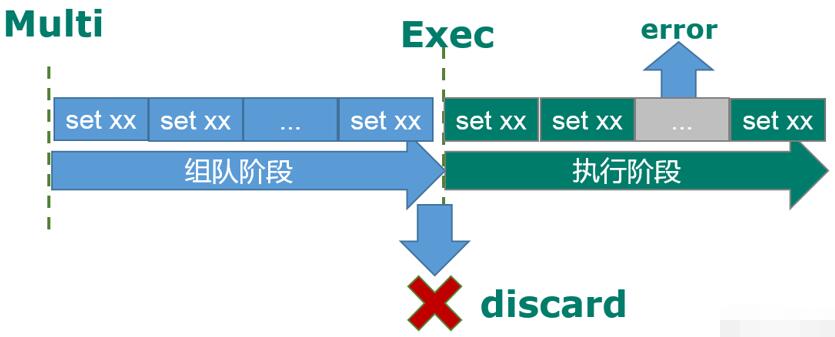
multi,exec,discard
1.从输入 multi 命令开始,输入的命令都会依次进入命令队列中,但不会执行,至到输入 exec后,Redis 会将之前的命令队列中的命令依次执行。
2.组队的过程中可以通过 discard 来放弃组队
事务中的错误处理
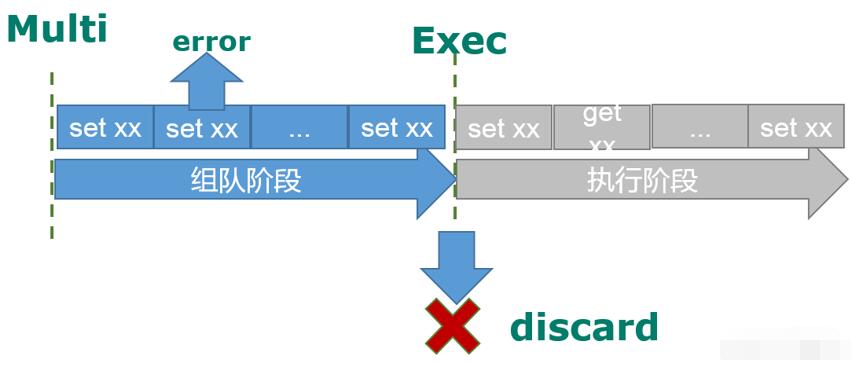
1.组队中某个命令出现了报告错误,执行时整个的所有队列会都会被取消。
2.如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。
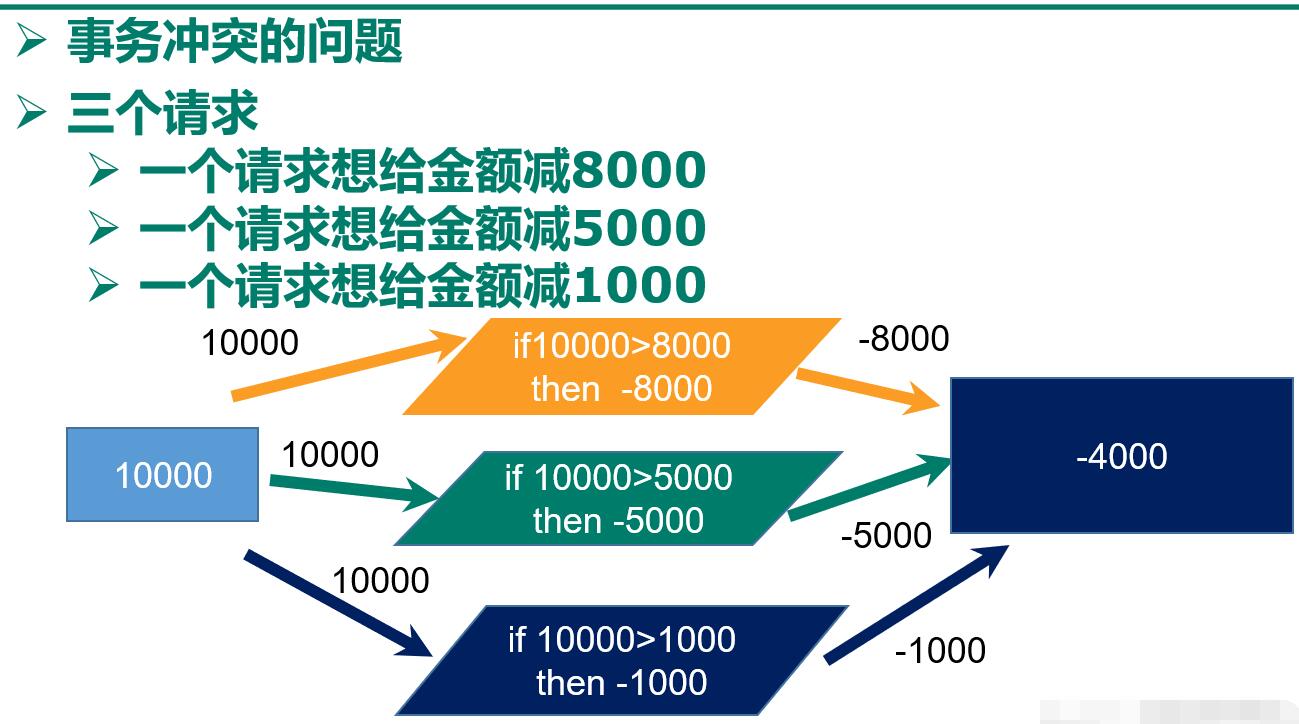
为什么要做成事务?
1.想想一个场景: 有很多人有你的账户,同时去参加双十一抢购
2.通过事务解决问题
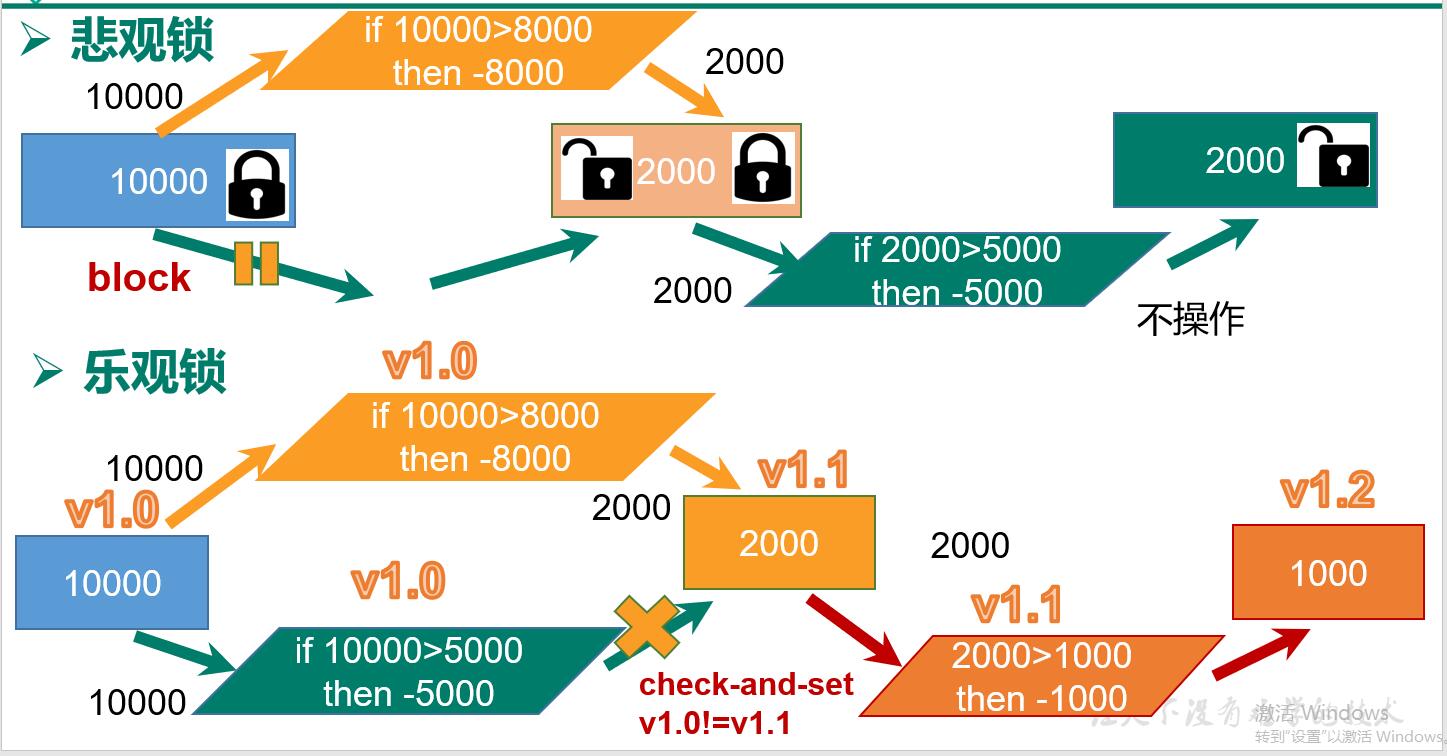
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会 block 直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis 就是利用这种 check-and-set 机制实现事务的。
Redis 事务的使用
WATCH key [key …]
在执行 multi 之前,先执行 watch key1 [key2],可以监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
下面的例子中
1.监视一个 key betch1
2.开启事务
3.定义自减变量 balance1
4.定义自增变量 debt1
5.提交
6.结果显示了两个变量的值
127.0.0.1:6379> watch betch1OK127.0.0.1:6379> multiOK127.0.0.1:6379> decrby balance1 10QUEUED127.0.0.1:6379> incrby debt1 20QUEUED127.0.0.1:6379> exec1) (integer) -102) (integer) 20
unwatch
取消 WATCH 命令对所有 key 的监视。
如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。
三特性
| 名称 | 定义 |
|---|---|
| 单独的隔离操作 | 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。 |
| 没有隔离级别的概念 | 队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在“事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头痛的问题? |
| 不保证原子性 | Redis 同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚 |
127.0.0.1:6379> get debt1"40"127.0.0.1:6379> get balance1"-10"127.0.0.1:6379> watch betch1OK127.0.0.1:6379> multiOK127.0.0.1:6379> decrby balance1 10aQUEUED127.0.0.1:6379> incrby debt1 10QUEUED127.0.0.1:6379> exec1) (error) ERR value is not an integer or out of range2) (integer) 50127.0.0.1:6379> get balance1"-10"127.0.0.1:6379> get debt1"50"127.0.0.1:6379>
Redis 持久化
Redis 提供了 2 个不同形式的持久化方式 RDB 和 AOF
RDB
1.在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的 Snapshot 快照,它恢复时是将快照文件直接读到内存里。
2.备份是如何执行的
Redis 会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何 IO 操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那 RDB 方式要比 AOF 方式更加的高效。RDB 的缺点是最后一次持久化后的数据可能丢失。
3.关于 fork
在 Linux 程序中,fork() 会产生一个和父进程完全相同的子进程,但子进程在此后多会 exec 系统调用,出于效率考虑,Linux 中引入了“写时复制技术”,一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
4.RDB 保存的文件
在 redis.conf 中配置文件名称,默认为 dump.rdb
查找配置文件中相关内容:cat /opt/myRedis/redis.conf | grep 'dbfilename dump.rdb' -C 2
显示
# The filename where to dump the DBdbfilename dump.rdb
5.RDB 文件的保存路径
默认为 Redis 启动时命令行所在的目录下,也可以修改
查找配置文件中相关内容:cat /opt/myRedis/redis.conf | grep 'dir ./' -C 2
显示
# Note that you must specify a directory here, not a file name.dir ./
6.RDB 的保存策略
查找配置文件中相关内容:cat /opt/myRedis/redis.conf | grep 'save 900 1' -C 20
# In the example below the behaviour will be to save:# after 900 sec (15 min) if at least 1 key changed# after 300 sec (5 min) if at least 10 keys changed# after 60 sec if at least 10000 keys changedsave 900 1save 300 10save 60 10000
7.RDB 的相关配置
| 配置项名称 | 含义 |
|---|---|
| stop-writes-on-bgsave-error | 当 Redis 无法写入磁盘的话,直接关掉 Redis 的写操作 |
| rdbcompression | 进行 rdb 保存时,将文件压缩 |
| rdbchecksum | 在存储快照后,还可以让 Redi s使用 CRC64 算法来进行数据校验,但是这样做会增加大约 10% 的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能 |
8.手动保存快照
save: 只管保存,其它不管,全部阻塞bgsave:按照保存策略自动保存
9.RDB 的备份与恢复
(1)备份:先通过 config get dir 查询 rdb 文件的目录 , 将 *.rdb 的文件拷贝到别的地方
(2)恢复: 关闭 Redis,把备份的文件拷贝到工作目录下,启动 redis,备份数据会直接加载。
使用 vim redis.conf 设置 .rdb 文件保存路径
dir /opt/myRedis
停止 redis 服务
redis-cli shutdown
重新进入 redis,查看当前 redis 中所有的键,并保存
127.0.0.1:6379> keys *1) "key1"2) "key2"127.0.0.1:6379> saveOK127.0.0.1:6379> exit
进入 Redis启动时命令行所在的目录
[root@luoma ~]# cd /opt/myRedis/ ls[root@luoma myRedis]# lsdump.rdb redis.conf
停止 redis 服务
redis-cli shutdown
剪切这个文件到上一级目录
[root@luoma myRedis]# mv dump.rdb ../dump.rdb
重新进入 redis,查看当前 redis 中所有的键
127.0.0.1:6379> keys *(empty list or set)
停止 redis 服务,拷贝上一级目录中的 dump.rdb 到 /opt/myRedis/,启动 redis,再次查看所有键
[root@luoma myRedis]# redis-cli shutdown[root@luoma opt]# mv dump.rdb myRedis/dump.rdb[root@luoma opt]# redis-server myRedis/redis.conf[root@luoma opt]# redis-cli127.0.0.1:6379> keys *1) "key2"2) "key1"
10.RDB 的优缺点
| 名称 | 含义 |
|---|---|
| 优点 | 节省磁盘空间,恢复速度快 |
| 缺点 | 虽然 Redis 在 fork 时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。在备份周期在一定间隔时间做一次备份,所以如果 Redis 意外 down 掉的话,就会丢失最后一次快照后的所有修改 |
AOF
1.以日志的形式来记录每个写操作,将 Redis 执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis 启动之初会读取该文件重新构建数据,换言之,Redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
2.AOF 默认不开启,需要手动在配置文件中配置
查找配置文件中相关内容:cat /opt/myRedis/redis.conf | grep 'AOF' -C 2
# AOF and RDB persistence can be enabled at the same time without problems.# If the AOF is enabled on startup Redis will load the AOF, that is the file# with the better durability guarantees.## Please check http://redis.io/topics/persistence for more information.appendonly no
3.可以在 redis.conf 中配置文件名称,默认为 appendonly.aof
查找配置文件中相关内容:cat /opt/myRedis/redis.conf | grep 'appendonly.aof' -C 2
# The name of the append only file (default: "appendonly.aof")appendfilename "appendonly.aof"
AOF 文件的保存路径,同 RDB 的路径一致
4.AOF 和 RDB 同时开启,redis 听谁的?
听 AOF 的,RDB 与 AOF 同时开启 默认无脑加载 AOF 的配置文件
相同数据集,AOF 文件要远大于 RDB 文件,恢复速度慢于 RDB
AOF 运行效率慢于 RDB,但是同步策略效率好,不同步效率和 RDB 相同。
5.AOF 文件故障备份
AOF 的备份机制和性能虽然和 RDB 不同, 但是备份和恢复的操作同 RDB 一样,都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载。
6.AOF 文件故障恢复
如遇到 AO F文件损坏,可通过redis-check-aof --fix appendonly.aof 进行恢复
7.AOF 同步频率设置
查找配置文件中相关内容:cat /opt/myRedis/redis.conf | grep 'appendfsync' -C 2
# If unsure, use "everysec".# appendfsync alwaysappendfsync everysec# appendfsync no
(1)始终同步,每次Redis的写入都会立刻记入日志
(2)每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
(3)把不主动进行同步,把同步时机交给操作系统。
8.Rewrite
(1)AOF 采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当 AOF 文件的大小超过所设定的阈值时,Redi s就会启动 AOF 文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令 bgrewriteaof。
(2))Redis 如何实现重写
AOF 文件持续增长而过大时,会 fork 出一条新进程来将文件重写(也是先写临时文件最后再 rename),遍历新进程的内存中数据,每条记录有一条的 Set 语句。重写 aof 文件的操作,并没有读取旧的 aof 文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof 文件,这点和快照有点类似。
(3)何时重写
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定 Redis 要满足一定条件才会进行重写。
查找配置文件中相关内容:cat /opt/myRedis/redis.conf | grep 'auto-aof' -C 2
auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb
系统载入时或者上次重写完毕时,Redis 会记录此时 AOF 大小,设为 base_size,如果 Redis 的 AOF 当前大小 >= base_size + base_size * 100% (默认) 且 当前大小>=64mb(默认) 的情况下,Redis 会对 AOF 进行重写。
9.AOF 的优缺点
| 优点 | 缺点 |
|---|---|
| 备份机制更稳健,丢失数据概率更低。可读的日志文本,通过操作 AOF 稳健,可以处理误操作。 | 比起 RDB 占用更多的磁盘空间。恢复备份速度要慢。每次读写都同步的话,有一定的性能压力。 |
10.例子
开启 AOF
[root@luoma opt]# vim /opt/myRedis/redis.conf
设置 appendonly yes
重启 redis
[root@luoma opt]# vim /opt/myRedis/redis.conf[root@luoma opt]# redis-cli shutdown[root@luoma opt]# redis-server /opt/myRedis/redis.conf[root@luoma opt]# redis-cli[root@luoma myRedis]# lsappendonly.aof dump.rdb redis.conf
RDB 和 AOF 用哪个好
(1)官方推荐两个都启用。
(2)如果对数据不敏感,可以选单独用 RDB
(3)不建议单独用 AOF,因为可能会出现 Bug
(4)如果只是做纯内存缓存,可以都不用
Redis 主从复制
什么是主从复制
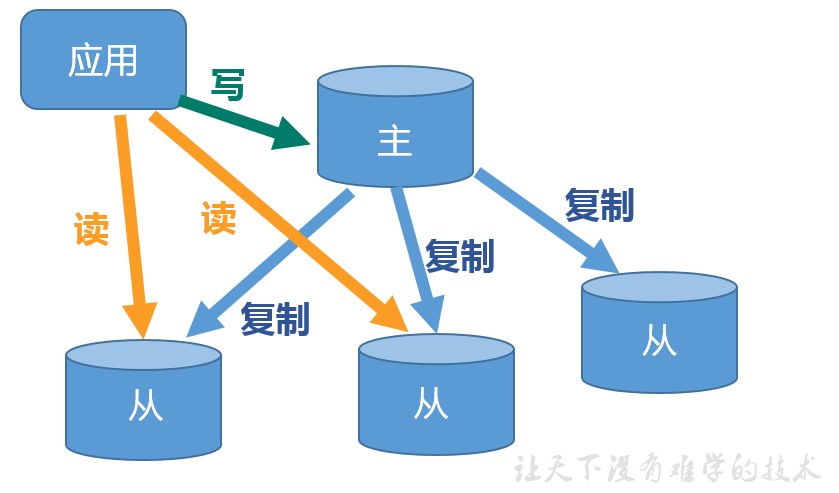
主从复制,就是主机数据更新后根据配置和策略,自动同步到备机的 master/slaver 机制,Master 以写为主,Slave 以读为主。
主从复制的目的
(1)读写分离,性能扩展
(2)容灾快速恢复
(3)
如何使用主从复制
下面的内容根据这篇博客根据自己的实际操作写成
深入学习Redis(3):主从复制
1.建立复制
需要注意,主从复制的开启,完全是在从节点发起的;不需要我们在主节点做任何事情。
从节点开启主从复制,有3种方式:
(1)配置文件
在从服务器的配置文件中加入:slaveof <masterip> <masterport>
(2)启动命令
redis-server 启动命令后加入 --slaveof <masterip> <masterport>
(3)客户端命令
Redis 服务器启动后,直接通过客户端执行命令:slaveof <masterip> <masterport>,则该 Redis 实例成为从节点。
上述三种方式是等效的,下面以客户端命令的方式为例,看一下当执行了 slaveof 后,Redis 主节点和从节点的变化。
2.实例
(1)准备工作:启动两个节点
方便起见,实验所使用的主从节点是在一台机器上的不同 Redis 实例,其中主节点监听 6379 端口,从节点监听 6380 端口。
1)主节点
在之前的配置中,主节点的位置位于 /opt/myRedis/redis.conf
2)从节点
我们复制 /opt/myRedis/ 为 /opt/myRedis1/,从节点监听的端口号可以在配置文件中修改。
cp /opt/myRedis /opt/myRedis1 -rv
进入 myRedis1 目录,修改 redis.conf 配置文件内容
# Accept connections on the specified port, default is 6379 (IANA #815344).# If port 0 is specified Redis will not listen on a TCP socket.port 6380
这里我使用 XShell 开启两个窗口,分别开启服务
启动后可以看到两个 Redis 节点启动后(分别称为 6379 节点和 6380 节点),默认都是主节点。
[root@luoma myRedis]# redis-server /opt/myRedis/redis.conf[root@luoma myRedis]# redis-cli -h 127.0.0.1 -p 6379127.0.0.1:6379>
[root@luoma myRedis1]# redis-server /opt/myRedis1/redis.conf[root@luoma myRedis1]# redis-cli -h 127.0.0.1 -p 6380127.0.0.1:6380>
(2)建立复制
此时在 6380 节点执行 slaveof 命令,使之变为从节点:
[root@luoma myRedis1]# redis-cli -h 127.0.0.1 -p 6380127.0.0.1:6380> slaveof 127.0.0.1 6379OK
(3)观察效果
1)首先在从节点查询一个不存在的 key
127.0.0.1:6380> get key1(nil)
2)然后在主节点中增加这个 key
127.0.0.1:6379> set key1 value1OK
3)此时在从节点中再次查询这个 key,会发现主节点的操作已经同步至从节点
127.0.0.1:6380> get key1"value1"
4)然后在主节点删除这个 key
127.0.0.1:6379> del key1(integer) 1
5)此时在从节点中再次查询这个 key,会发现主节点的操作已经同步至从节点
127.0.0.1:6380> get key1(nil)
3.断开复制
通过 slaveof <masterip> <masterport> 命令建立主从复制关系以后,可以通过 slaveof no one 断开。需要注意的是,从节点断开复制后,不会删除已有的数据,只是不再接受主节点新的数据变化。
从节点执行 slaveof no one 后
127.0.0.1:6380> slaveof no oneOK
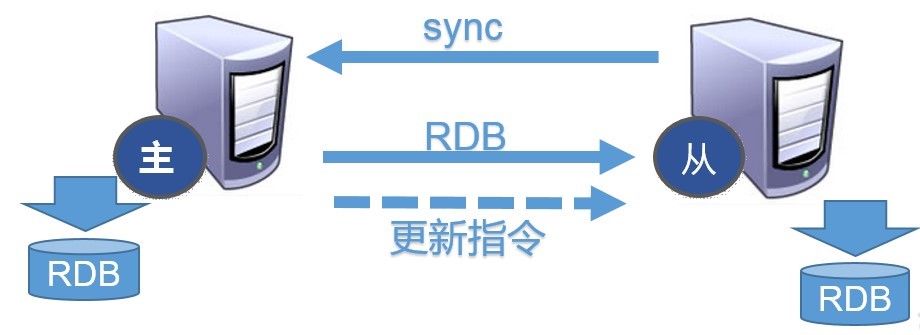
主从复制的实现原理
1.每次从机联通后,都会给主机发送 sync 指令
2.主机立刻进行存盘操作,发送 RDB 文件,给从机
3.从机收到 RDB 文件后,进行全盘加载
4.之后每次主机的写操作,都会立刻发送给从机,从机执行相同的命令
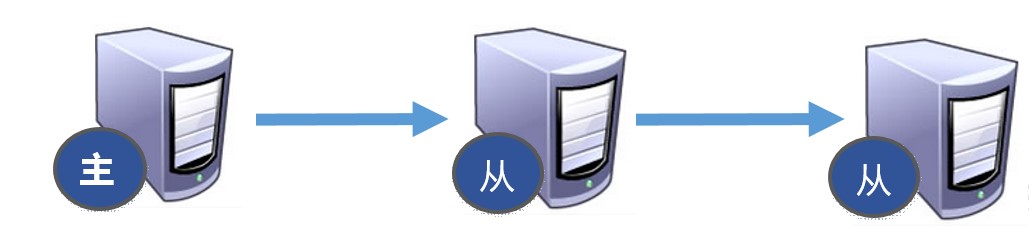
薪火相传模式
1.上一个 slave 可以是下一个 slave 的 Master,slave 同样可以接收其他 slaves 的连接和同步请求,那么该 slave 作为了链条中下一个的 master, 可以有效减轻 master 的写压力,去中心化降低风险。
中途变更转向:会清除之前的数据,重新建立拷贝最新的。
风险是一旦某个 slave 宕机,后面的 slave 都没法备份。
2.反客为主(小弟上位)
当一个 master 宕机后,后面的 slave 可以立刻升为 master,其后面的 slave 不用做任何修改。
用 slaveof no one 将从机变为主机。
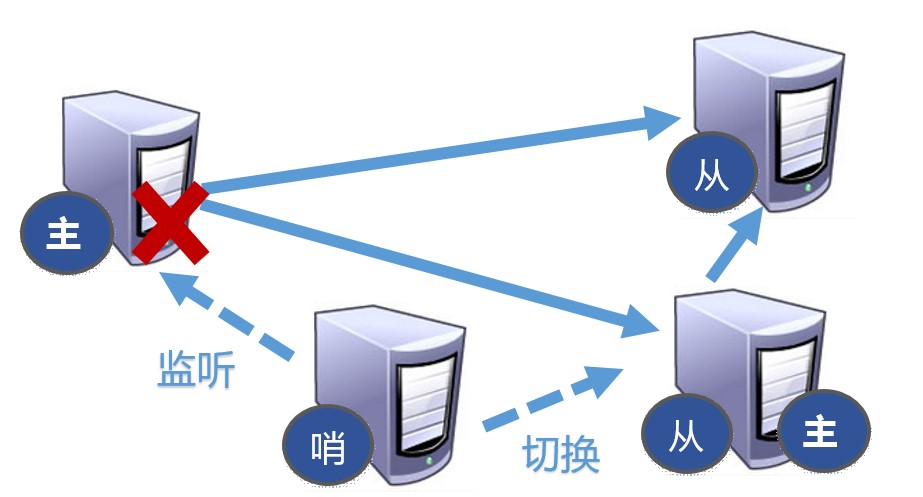
3.哨兵模式 sentinel (推举大哥)
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
下面的内容根据这篇博客根据自己的实际操作写成
深入学习Redis(4):哨兵
在介绍哨兵之前,首先从宏观角度回顾一下 Redis 实现高可用相关的技术。
| 高可用相关的技术 | 描述 |
|---|---|
| 持久化 | 持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。 |
| 复制 | 复制是高可用 Redis 的基础,哨兵和集群都是在复制基础上实现高可用的。复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。 |
| 哨兵 | 在复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限制 |
| 集群 | 通过集群,Redis 解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。 |
下面说回哨兵。Redis Sentinel,即 Redis 哨兵,在 Redis 2.8 版本开始引入。哨兵的核心功能是主节点的自动故障转移。下面是Redis官方文档对于哨兵功能的描述。
| 哨兵功能 | 描述 |
|---|---|
| 监控(Monitoring) | 哨兵会不断地检查主节点和从节点是否运作正常 |
| 自动故障转移(Automatic failover) | 当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点 |
| 配置提供者(Configuration provider) | 客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址 |
| 通知(Notification) | 哨兵可以将故障转移的结果发送给客户端 |
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移;而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
这里对“客户端”一词在文章中的用法做一个说明:在前面的文章中,只要通过 API 访问 redis 服务器,都会称作客户端,包括 redis-cli、Java 客户端 Jedis 等;为了便于区分说明,本文中的客户端并不包括 redis-cli,而是比 redis-cli 更加复杂:redis-cli 使用的是 redis 提供的底层接口,而客户端则对这些接口、功能进行了封装,以便充分利用哨兵的配置提供者和通知功能。
典型的哨兵架构图如下所示
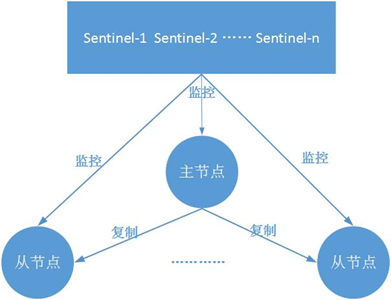
它由两部分组成
| 节点 | 描述 |
|---|---|
| 哨兵节点 | 哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据 |
| 数据节点 | 主节点和从节点都是数据节点 |
部署
这一部分将部署一个简单的哨兵系统,包含 1 个主节点、2 个从节点和 3 个哨兵节点。
方便起见:所有这些节点都部署在一台机器上(局域网IP:192.168.241.128),使用端口号区分;节点的配置尽可能简化。
1.部署主从节点
哨兵系统中的主从节点,与普通的主从节点配置是一样的,并不需要做任何额外配置。下面分别是主节点(port=6379)和2个从节点(port=6380/6381)的配置文件,配置都比较简单,不再详述。
在上面部分内容中,我们已经配置了 6380 的内容,6381 的配置方式是一样的。我们需要把之前 redis.conf 修改为对应该端口的名称。
#redis-6379.confport 6379daemonize yeslogfile "6379.log"dbfilename "dump-6379.rdb"#redis-6380.confport 6380daemonize yeslogfile "6380.log"dbfilename "dump-6380.rdb"slaveof 192.168.241.128 6379#redis-6381.confport 6381daemonize yeslogfile "6381.log"dbfilename "dump-6381.rdb"slaveof 192.168.241.128 6379
配置完成后,依次启动主节点和从节点。
redis-server redis-6379.confredis-server redis-6380.confredis-server redis-6381.conf
节点启动后,连接主节点查看主从状态是否正常
[root@luoma myRedis1]# redis-cli -p 6379127.0.0.1:6379> info Replication# Replicationrole:masterconnected_slaves:2slave0:ip=192.168.241.128,port=6381,state=online,offset=686,lag=1slave1:ip=192.168.241.128,port=6380,state=online,offset=686,lag=0master_replid:ea6484d7652ecab63d3e9afe9ee8e30b5aed6a32master_replid2:0000000000000000000000000000000000000000master_repl_offset:686second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:686
2.部署哨兵节点
哨兵节点本质上是特殊的 Redis 节点。
3 个哨兵节点的配置几乎是完全一样的,主要区别在于端口号的不同(26379/26380/26381)
#sentinel-26379.confport 26379daemonize yeslogfile "26379.log"sentinel monitor mymaster 192.168.241.128 6379 2#sentinel-26380.confport 26380daemonize yeslogfile "26380.log"sentinel monitor mymaster 192.168.241.128 6379 2#sentinel-26381.confport 26381daemonize yeslogfile "26381.log"sentinel monitor mymaster 192.168.241.128 6379 2
其中 sentinel monitor mymaster 192.168.241.128 6379 2 配置的含义是”该哨兵节点监控 192.168.241.128 6379 这个主节点,该主节点的名称是mymaster,最后的 2 的含义与主节点的故障判定有关:至少需要 2 个哨兵节点同意,才能判定主节点故障并进行故障转移”。
哨兵节点的启动有两种方式,二者作用是完全相同的:
redis-sentinel sentinel-26379.confredis-server sentinel-26379.conf --sentinel
这里我依次启动 3 个哨兵节点
redis-server sentinel-26379.confredis-server sentinel-26380.confredis-server sentinel-26381.conf
按照上述方式配置和启动之后,整个哨兵系统就启动完毕了。可以通过 redis-cli -p 26379 连接哨兵节点进行验证,如下所示:可以看出 26379 哨兵节点已经在监控 mymaster 主节点(即 192.168.241.128:6379),并发现了其2个从节点和另外 2 个哨兵节点。
[root@luoma myRedis]# redis-cli -p 26379127.0.0.1:26379> info Sentinel# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0master0:name=mymaster,status=ok,address=192.168.241.128:6379,slaves=2,sentinels=3127.0.0.1:26379>
此时如果查看哨兵节点的配置文件,会发现一些变化,以 26379 为例
[root@luoma myRedis]# cat sentinel-26379.conf |grep 'Generated by'Generated by CONFIG REWRITEsentinel deny-scripts-reconfig yessentinel monitor mymaster 192.168.241.128 6379 2sentinel config-epoch mymaster 0sentinel leader-epoch mymaster 0sentinel known-replica mymaster 192.168.241.128 6380sentinel known-replica mymaster 192.168.241.128 6381sentinel known-sentinel mymaster 192.168.241.128 26381 bb2a13cf88e5a1382e5b33a2ab233003114fc8b8sentinel known-sentinel mymaster 192.168.241.128 26380 e1252d2ff718d68b6d733f0cbd558594159438desentinel current-epoch 0
kknown-replica 和 known-sentinel 显示哨兵已经发现了从节点和其他哨兵;带有 epoch 的参数与配置纪元有关(配置纪元是一个从 0 开始的计数器,每进行一次领导者哨兵选举,都会 +1;领导者哨兵选举是故障转移阶段的一个操作)。
演示故障转移
这一小节将演示当主节点发生故障时,哨兵的监控和自动故障转移功能。
1.首先,使用 kill 命令杀掉主节点
[root@luoma myRedis]# ps aux | grep 6379root 2203 0.3 1.1 159452 11888 ? Ssl 17:15 0:27 redis-server *:6379root 2292 0.3 0.7 156380 7904 ? Ssl 17:22 0:28 redis-sentinel *:26379 [sentinel]root 3607 0.0 0.0 112660 988 pts/0 S+ 19:40 0:00 grep --color=auto 6379[root@luoma myRedis]# kill -9 2203
2.如果此时立即在哨兵节点中使用 info Sentinel 命令查看,会发现主节点还没有切换过来,因为哨兵发现主节点故障并转移,需要一段时间。
[root@luoma myRedis]# redis-cli -p 26379 info Sentinel# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0master0:name=mymaster,status=ok,address=192.168.241.128:6379,slaves=2,sentinels=3
3.一段时间以后,再次在哨兵节点中执行 info Sentinel 查看,发现主节点已经切换成 6380 节点。
[root@luoma myRedis]# redis-cli -p 26379 info Sentinel# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0master0:name=mymaster,status=ok,address=192.168.241.128:6380,slaves=2,sentinels=3
但是同时可以发现,哨兵节点认为新的主节点仍然有 2 个从节点,这是因为哨兵在将 6380 切换成主节点的同时,将6379 节点置为其从节点;虽然 6379 从节点已经挂掉,但是由于哨兵并不会对从节点进行客观下线,因此认为该从节点一直存在。当 6379 节点重新启动后,会自动变成 6380 节点的从节点。下面验证一下。
4.重启 6379 节点
从 slave1:ip=192.168.241.128,port=6379,state=online,offset=1848575,lag=0 可以看到 6379 节点成为了 6380 节点的从节点。
[root@luoma myRedis]# redis-server redis-6379.conf[root@luoma myRedis]# redis-cli -p 6380 info Replication# Replicationrole:masterconnected_slaves:2slave0:ip=192.168.241.128,port=6381,state=online,offset=1848575,lag=0slave1:ip=192.168.241.128,port=6379,state=online,offset=1848575,lag=0master_replid:211320803d8e64bf1d2def7fe095f651b4d96dddmaster_replid2:c14f062b9e26c93627eed34411aba2988ff820b1master_repl_offset:1848720second_repl_offset:1783585repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:800145repl_backlog_histlen:1048576
5.在故障转移阶段,哨兵和主从节点的配置文件都会被改写。
对于主从节点,主要是 slaveof 配置的变化:新的主节点没有了slaveof 配置,其从节点则 slaveof 新的主节点。
对于哨兵节点,除了主从节点信息的变化,纪元(epoch)也会变化,下面可以看到纪元相关的参数都 +1 了。
[root@luoma myRedis]# cat sentinel-26379.conf | grep 'sentinel' -C 10sentinel deny-scripts-reconfig yessentinel monitor mymaster 192.168.241.128 6380 2sentinel config-epoch mymaster 1sentinel leader-epoch mymaster 1sentinel known-replica mymaster 192.168.241.128 6379sentinel known-replica mymaster 192.168.241.128 6381sentinel known-sentinel mymaster 192.168.241.128 26381 bb2a13cf88e5a1382e5b33a2ab233003114fc8b8sentinel known-sentinel mymaster 192.168.241.128 26380 e1252d2ff718d68b6d733f0cbd558594159438desentinel current-epoch 1
总结
哨兵系统的搭建过程,有几点需要注意:
1.哨兵系统中的主从节点,与普通的主从节点并没有什么区别,故障发现和转移是由哨兵来控制和完成的。
2.哨兵节点本质上是 redis 节点。
3.每个哨兵节点,只需要配置监控主节点,便可以自动发现其他的哨兵节点和从节点。
4.在哨兵节点启动和故障转移阶段,各个节点的配置文件会被重写(config rewrite)。
5.本章的例子中,一个哨兵只监控了一个主节点;实际上,一个哨兵可以监控多个主节点,通过配置多条 sentinel monitor 即可实现。
客户端访问哨兵系统
监控和自动故障转移,本小节则结合客户端演示哨兵的另外两个作用:配置提供者和通知。
代码示例
在介绍客户端的原理之前,先以 Java 客户端 Jedis 为例,演示一下使用方法:下面代码可以连接我们刚刚搭建的哨兵系统,并进行各种读写操作(代码中只演示如何连接哨兵,异常处理、资源关闭等未考虑)。
package com.guigu.bean;import java.util.HashSet;import java.util.Set;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisSentinelPool;public class RedisTest {public static void main(String[] args) {String masterName = "mymaster";Set<String> sentinels = new HashSet<>();sentinels.add("192.168.241.128:26379");sentinels.add("192.168.241.128:26380");sentinels.add("192.168.241.128:26381");JedisSentinelPool pool = new JedisSentinelPool(masterName, sentinels);Jedis jedis = pool.getResource();jedis.set("key1","value1");pool.close();}}
运行,控制台输出
十月 19, 2020 8:04:46 下午 redis.clients.jedis.JedisSentinelPool initSentinels信息: Trying to find master from available Sentinels...十月 19, 2020 8:04:46 下午 redis.clients.jedis.JedisSentinelPool initSentinels信息: Redis master running at 192.168.241.128:6380, starting Sentinel listeners...十月 19, 2020 8:04:46 下午 redis.clients.jedis.JedisSentinelPool initPool信息: Created JedisPool to master at 192.168.241.128:6380
返回 Redis 查看,发现已经添加成功了。
[root@luoma myRedis]# redis-cli -p 6380127.0.0.1:6380> keys *1) "key1"
客户端原理
Jedis 客户端对哨兵提供了很好的支持。如上述代码所示,我们只需要向 Jedis 提供 哨兵节点集合 和 masterName,构造 JedisSentinelPool 对象;然后便可以像使用普通 redis 连接池一样来使用了:通过pool.getResource() 获取连接,执行具体的命令。
在整个过程中,我们的代码不需要显式的指定主节点的地址,就可以连接到主节点;代码中对故障转移没有任何体现,就可以在哨兵完成故障转移后自动的切换主节点。之所以可以做到这一点,是因为在 JedisSentinelPool 的构造器中,进行了相关的工作;主要包括以下两点。
1.遍历哨兵节点,获取主节点信息。
遍历哨兵节点,通过其中一个哨兵节点 + masterName 获得主节点的信息;该功能是通过调用哨兵节点的 sentinel get-master-addr-by-name 命令实现,该命令示例如下。
[root@luoma myRedis]# redis-cli -p 26379127.0.0.1:26379> sentinel get-master-addr-by-name mymaster1) "192.168.241.128"2) "6380"
一旦获得主节点信息,停止遍历(因此一般来说遍历到第一个哨兵节点,循环就停止了)。
2.增加对哨兵的监听。
这样当发生故障转移时,客户端便可以收到哨兵的通知,从而完成主节点的切换。具体做法是利用 redis 提供的发布订阅功能,为每一个哨兵节点开启一个单独的线程,订阅哨兵节点的 + switch-master 频道,当收到消息时,重新初始化连接池。
总结
通过客户端原理的介绍,可以加深对哨兵功能的理解。
1.配置提供者:客户端可以通过哨兵节点 + masterName 获取主节点信息,在这里哨兵起到的作用就是配置提供者。
需要注意的是,哨兵只是配置提供者,而不是代理。二者的区别在于,如果是配置提供者,客户端在通过哨兵获得主节点信息后,会直接建立到主节点的连接,后续的请求(如set/get)会直接发向主节点;如果是代理,客户端的每一次请求都会发向哨兵,哨兵再通过主节点处理请求。
举一个例子可以很好的理解哨兵的作用是配置提供者,而不是代理。在前面部署的哨兵系统中,将哨兵节点的配置文件进行如下修改。
sentinel monitor mymaster 192.168.241.128 6379 2
改为
sentinel monitor mymaster 127.0.0.1 6379 2
然后,将前述客户端代码在局域网的另外一台机器上运行,会发现客户端无法连接主节点。这是因为哨兵作为配置提供者,客户端通过它查询到主节点的地址为 127.0.0.1:6379,客户端会向 127.0.0.1:6379 建立 redis 连接,自然无法连接。如果哨兵是代理,这个问题就不会出现了。
2.通知。
哨兵节点在故障转移完成后,会将新的主节点信息发送给客户端,以便客户端及时切换主节点。
Redis 集群
根据 深入学习Redis(5):集群 结合自己的实际操作的笔记记录
什么是集群?
集群,即 Redis Cluster,是 Redis 3.0 开始引入的分布式存储方案。
集群由多个节点(Node)组成,Redis 的数据分布在这些节点中。集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制。
集群的作用,可以归纳为两点:
1.数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多个节点,一方面突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis 单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave 和 bgrewriteaof 的 fork 操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出。
2.高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
集群的搭建
这一部分我们将搭建一个简单的集群:共 6 个节点,3 主 3从。
方便起见:所有节点在同一台服务器上,以端口号进行区分;配置从简。3 个主节点端口号:7000/7001/7002,对应的从节点端口号:8000/8001/8002。
集群的搭建有两种方式。
1.手动执行 Redis 命令,一步步完成搭建。
2.使用 Ruby 脚本搭建。
二者搭建的原理是一样的,只是 Ruby 脚本将 Redis 命令进行了打包封装。在实际应用中推荐使用脚本方式,简单快捷不容易出错。下面分别介绍这两种方式。
执行 Redis 命令搭建集群
集群的搭建可以分为四步。
1.启动节点:将节点以集群模式启动,此时节点是独立的,并没有建立联系;
2.节点握手:让独立的节点连成一个网络;
3.分配槽:将 16384 个槽分配给主节点;
4.指定主从关系:为从节点指定主节点。
实际上,前三步完成后集群便可以对外提供服务;但指定从节点后,集群才能够提供真正高可用的服务。
1.启动节点
集群节点的启动仍然是使用 redis-server 命令,但需要使用集群模式启动。下面是节点的配置文件(只列出了节点正常工作关键配置,其他配置(如开启AOF)可以参照单机节点进行)。
进入配置文件目录,复制之前的配置文件 cp redis-6379.conf redis-7000.conf,得到以下配置,并修改对应配置项。
#redis-7000.confport 7000cluster-enabled yescluster-config-file "node-7000.conf"logfile "log-7000.log"dbfilename "dump-7000.rdb"daemonize yes#bind 127.0.0.1protected-mode no#redis-7001.confport 7001cluster-enabled yescluster-config-file "node-7001.conf"logfile "log-7001.log"dbfilename "dump-7001.rdb"daemonize yes#bind 127.0.0.1protected-mode no#redis-7002.confport 7002cluster-enabled yescluster-config-file "node-7002.conf"logfile "log-7002.log"dbfilename "dump-7002.rdb"daemonize yes#bind 127.0.0.1protected-mode no#redis-8000.confport 8000cluster-enabled yescluster-config-file "node-8000.conf"logfile "log-8000.log"dbfilename "dump-8000.rdb"daemonize yes#bind 127.0.0.1protected-mode no#redis-8001.confport 8001cluster-enabled yescluster-config-file "node-8001.conf"logfile "log-8001.log"dbfilename "dump-8001.rdb"daemonize yes#bind 127.0.0.1protected-mode no#redis-8002.confport 8002cluster-enabled yescluster-config-file "node-8002.conf"logfile "log-8002.log"dbfilename "dump-8002.rdb"daemonize yes#bind 127.0.0.1protected-mode no
其中的 cluster-enabled 和 cluster-config-file 是与集群相关的配置。
cluster-enabled yes:Redis 实例可以分为单机模式(standalone)和集群模式(cluster);cluster-enabled yes 可以启动集群模式。在单机模式下启动的Redis 实例,如果执行 info server 命令,可以发现redis_mode一项为 standalone
[root@luoma myRedis]# redis-server redis-6379.conf[root@luoma myRedis]# redis-cli -p 6379 info Server# Serverredis_version:5.0.4redis_git_sha1:00000000redis_git_dirty:0redis_build_id:9a6089d2891aa82fredis_mode:standaloneos:Linux 3.10.0-1127.el7.x86_64 x86_64
集群模式下的节点,其 redis_mode 为 cluster
[root@luoma myRedis]# redis-server redis-7000.conf[root@luoma myRedis]# redis-cli -p 7000 info Server# Serverredis_version:5.0.4redis_git_sha1:00000000redis_git_dirty:0redis_build_id:9a6089d2891aa82fredis_mode:cluster
cluster-config-file:该参数指定了集群配置文件的位置。每个节点在运行过程中,会维护一份集群配置文件;每当集群信息发生变化时(如增减节点),集群内所有节点会将最新信息更新到该配置文件;当节点重启后,会重新读取该配置文件,获取集群信息,可以方便的重新加入到集群中。也就是说,当 Redis 节点以集群模式启动时,会首先寻找是否有集群配置文件,如果有则使用文件中的配置启动,如果没有,则初始化配置并将配置保存到文件中。集群配置文件由 Redis 节点维护,不需要人工修改。
编辑好配置文件后,使用 redis-server 命令启动该节点
redis-server redis-7000.conf
节点启动以后,通过 cluster nodes 命令可以查看节点的情况,如下所示。
[root@luoma myRedis]# redis-cli -p 7000 cluster nodes8f79849b10c68ed64f894ecd8fa195d21add8d4a 192.168.241.128:7000@17000 myself,master - 0 1603356935699 0 connected 0-546
其中返回值第一项表示节点 id,由 40 个 16 进制字符串组成,节点id 与主从复制中提到的 runId 不同:Redis 每次启动 runId 都会重新创建,但是节点 id 只在集群初始化时创建一次,然后保存到集群配置文件中,以后节点重新启动时会直接在集群配置文件中读取。
其它节点使用相同办法启动
[root@luoma myRedis]# redis-server redis-7001.conf[root@luoma myRedis]# redis-server redis-7002.conf[root@luoma myRedis]# redis-server redis-8000.conf[root@luoma myRedis]# redis-server redis-8001.conf[root@luoma myRedis]# redis-server redis-8002.conf
需要特别注意,在启动节点阶段,节点是没有主从关系的,因此从节点不需要加 slaveo 配置。
2.节点握手
节点启动以后是相互独立的,并不知道其它节点存在;需要进行节点握手,将独立的节点组成一个网络。
节点握手使用 cluster meet {ip} {port} 命令实现,例如在 7000 节点中执行 cluster meet 192.168.241.128 7001,可以完成 7000 节点和 7001 节点的握手;注意 ip 使用的是局域网ip而不是localhost 或 127.0.0.1,是为了其它机器上的节点或客户端也可以访问。此时再使用 cluster nodes 查看
[root@luoma myRedis]# redis-cli -p 7000127.0.0.1:7000> cluster meet 192.168.241.128 7001OK127.0.0.1:7000> cluster nodes8f79849b10c68ed64f894ecd8fa195d21add8d4a 192.168.241.128:7000@17000 myself,master - 0 1603356935699 0 connected 0-5461103ba084340c9e52a7360465aaa765db55df4a1c 192.168.241.128:7001@17001 handshake - 1603357546391 0 0 disconnected
同理,在 7000 节点中使用 cluster meet 命令,可以将所有节点加入到集群,完成节点握手。
127.0.0.1:7000> cluster meet 192.168.241.128 7002OK127.0.0.1:7000> cluster meet 192.168.241.128 8000OK127.0.0.1:7000> cluster meet 192.168.241.128 8001OK127.0.0.1:7000> cluster meet 192.168.241.128 8002OK
执行完上述命令后,可以看到 7000 节点已经感知到了所有其它节点。
127.0.0.1:7000> cluster nodes41c5cb007b427e6cf9202f63053512ffb3059363 127.0.0.1:8002@18002 master - 0 1603362870000 0 connected8f79849b10c68ed64f894ecd8fa195d21add8d4a 192.168.241.128:7000@17000 myself,master - 0 1603362870000 2 connected 0-5461edd82ca44407389ef77ebeac2662c3b0079bb413 127.0.0.1:8000@18000 master - 0 1603362870000 0 connected932386e8a2a4732e259c9b0a2cb0fb348ab08062 127.0.0.1:7002@17002 master - 0 1603362871000 3 connected 10923-163837c507ed70d63095d11b588b24bd24a4a03779d87 127.0.0.1:7001@17001 master - 0 1603362871000 1 connected 5462-10922926fa7fabe57c31623b8d557029ecd2dcee8f6ae 127.0.0.1:8001@18001 master - 0 1603362871989 4 connected
通过节点之间的通信,每个节点都可以感知到所有其它节点,以 8000 节点为例。
[root@luoma myRedis]# redis-cli -p 8000127.0.0.1:8000> cluster nodes932386e8a2a4732e259c9b0a2cb0fb348ab08062 127.0.0.1:7002@17002 master - 0 1603362937795 3 connected 10923-163837c507ed70d63095d11b588b24bd24a4a03779d87 127.0.0.1:7001@17001 master - 0 1603362935780 1 connected 5462-10922926fa7fabe57c31623b8d557029ecd2dcee8f6ae 127.0.0.1:8001@18001 master - 0 1603362936000 4 connected41c5cb007b427e6cf9202f63053512ffb3059363 127.0.0.1:8002@18002 master - 0 1603362934000 5 connectededd82ca44407389ef77ebeac2662c3b0079bb413 127.0.0.1:8000@18000 myself,master - 0 1603362936000 0 connected8f79849b10c68ed64f894ecd8fa195d21add8d4a 127.0.0.1:7000@17000 master - 0 1603362936787 2 connected 0-5461
3.分配槽
在 Redis 集群中,借助槽实现数据分区。集群有 16384 个槽,槽是数据管理和迁移的基本单位。当数据库中的 16384 个槽都分配了节点时,集群处于上线状态(ok);如果有任意一个槽没有分配节点,则集群处于下线状态(fail)
cluster info 命令可以查看集群状态,分配槽之前状态为 fail
[root@luoma myRedis]# redis-cli -p 7000 cluster infocluster_state:failcluster_slots_assigned:2
分配槽使用 cluster addslots 命令,执行下面的命令将槽(编号 0-16383)全部分配完毕
[root@luoma myRedis]# redis-cli -p 7000 cluster addslots {0..5461}OK[root@luoma myRedis]# redis-cli -p 7001 cluster addslots {5462..10922}OK[root@luoma myRedis]# redis-cli -p 7002 cluster addslots {10923..16383}OK
此时查看集群状态,显示所有槽分配完毕,集群进入上线状态
[root@luoma myRedis]# redis-cli -p 7000 cluster infocluster_state:okcluster_slots_assigned:16384
4.指定主从关系
集群中指定主从关系不再使用 slaveof 命令,而是使用cluster replicate 命令;参数使用节点 id。
通过 cluster nodes 获得几个主节点的节点 id 后,执行下面的命令为每个从节点指定主节点。
redis-cli -p 8000 cluster replicate 8f79849b10c68ed64f894ecd8fa195d21add8d4aredis-cli -p 8001 cluster replicate 7c507ed70d63095d11b588b24bd24a4a03779d87redis-cli -p 8002 cluster replicate 932386e8a2a4732e259c9b0a2cb0fb348ab08062
此时执行 cluster nodes查看各个节点的状态,可以看到主从关系已经建立。
[root@luoma myRedis]# redis-cli -p 7000127.0.0.1:7000> cluster nodes41c5cb007b427e6cf9202f63053512ffb3059363 127.0.0.1:8002@18002 slave 932386e8a2a4732e259c9b0a2cb0fb348ab08062 0 1603363569000 5 connected8f79849b10c68ed64f894ecd8fa195d21add8d4a 192.168.241.128:7000@17000 myself,master - 0 1603363570000 2 connected 0-5461edd82ca44407389ef77ebeac2662c3b0079bb413 127.0.0.1:8000@18000 slave 8f79849b10c68ed64f894ecd8fa195d21add8d4a 0 1603363570594 2 connected932386e8a2a4732e259c9b0a2cb0fb348ab08062 127.0.0.1:7002@17002 master - 0 1603363571600 3 connected 10923-163837c507ed70d63095d11b588b24bd24a4a03779d87 127.0.0.1:7001@17001 master - 0 1603363570000 1 connected 5462-10922926fa7fabe57c31623b8d557029ecd2dcee8f6ae 127.0.0.1:8001@18001 slave 7c507ed70d63095d11b588b24bd24a4a03779d87 0 1603363569587 4 connected
至此,集群搭建完毕。
使用 Ruby 脚本搭建集群
1.安装 Ruby 环境
(1)在线安装
yum install ruby #安装ruby环境yum install rubygems #gem是ruby的包管理工具,该命令可以安装ruby-redis依赖
(2)离线安装
获取如下工具
redis-3.2.0.gem
拷贝到 /opt/ 目录下
获取如下 rpm 包
"libyaml-0.1.4-11.el7_0.x86_64.rpm""ruby-2.0.0.648-30.el7.x86_64.rpm""rubygem-abrt-0.3.0-1.el7.noarch.rpm""rubygem-bigdecimal-1.2.0-30.el7.x86_64.rpm""rubygem-bundler-1.7.8-3.el7.noarch.rpm""rubygem-io-console-0.4.2-30.el7.x86_64.rpm""rubygem-json-1.7.7-30.el7.x86_64.rpm""rubygem-net-http-persistent-2.8-5.el7.noarch.rpm""rubygem-psych-2.0.0-30.el7.x86_64.rpm""rubygem-rdoc-4.0.0-30.el7.noarch.rpm""rubygems-2.0.14.1-30.el7.noarch.rpm""rubygem-thor-0.19.1-1.el7.noarch.rpm""ruby-irb-2.0.0.648-30.el7.noarch.rpm""ruby-libs-2.0.0.648-30.el7.x86_64.rpm"
拷贝到 /opt/rpmruby/ 目录下,并 cd 到此目录
执行:rpm -ivh *.rpm --force --nodeps 安装各个 rpm 包,nodeps 的意思是忽视依赖关系。因为各个软件之间会有多多少少的联系。有了这两个设置选项就忽略了这些依赖关系,强制安装或者卸载
在 opt 目录下执行 gem install --local redis-3.2.0.gem
[root@luoma opt]# gem install --local redis-3.2.0.gemSuccessfully installed redis-3.2.0Parsing documentation for redis-3.2.0Installing ri documentation for redis-3.2.01 gem installed
2.删除集群
之前的案例中创建了集群,现在删除掉。
(1)删除 redis 数据存储文件
我们需要将每个节点下面的,aof 和 rdb 是存储文件,都删除,还有节点配置信息,nodes-xx.conf 都删除掉
#直接杀死所有进程(直接暴力)kill -9 $(pidof redis-server)#停止所有节点(这个关闭也行,不暴力)redis-cli -h 127.0.0.1 -p 7000 shutdownredis-cli -h 127.0.0.1 -p 7001 shutdownredis-cli -h 127.0.0.1 -p 7002 shutdownredis-cli -h 127.0.0.1 -p 8000 shutdownredis-cli -h 127.0.0.1 -p 8001 shutdownredis-cli -h 127.0.0.1 -p 8002 shutdown#删除节点下面的所有相关文件(这个是批量删除的操作)rm -f nodes-*.conf appendonly.aof dump-*.rdb
3.启动节点
与第一种方法中的“启动节点”完全相同。
[root@luoma myRedis]# redis-server redis-7000.conf[root@luoma myRedis]# redis-server redis-7001.conf[root@luoma myRedis]# redis-server redis-7002.conf[root@luoma myRedis]# redis-server redis-8000.conf[root@luoma myRedis]# redis-server redis-8001.conf[root@luoma myRedis]# redis-server redis-8002.conf
4.搭建集群
进入到 cd /opt/redis-5.0.4/src
redis-trib.rb 脚本提供了众多命令,其中 create 用于搭建集群,使用方法如下
./redis-trib.rb create --replicas 1 192.168.241.128:7000 192.168.241.128:7001 192.168.241.128:7002 192.168.241.128:8000 192.168.241.128:8001 192.168.241.128:8002
出现如下提示
[root@luoma src]# ./redis-trib.rb create --replicas 1 192.168.241.128:7000 192.168.241.128:7001 192.168.241.128:7002 192.168.241.128:8000 192.168.241.128:8001 192.168.241.128:8002WARNING: redis-trib.rb is not longer available!You should use redis-cli instead.All commands and features belonging to redis-trib.rb have been movedto redis-cli.In order to use them you should call redis-cli with the --clusteroption followed by the subcommand name, arguments and options.Use the following syntax:redis-cli --cluster SUBCOMMAND [ARGUMENTS] [OPTIONS]Example:redis-cli --cluster create 192.168.241.128:7000 192.168.241.128:7001 192.168.241.128:7002 192.168.241.128:8000 192.168.241.128:8001 192.168.241.128:8002 --cluster-replicas 1To get help about all subcommands, type:redis-cli --cluster help
使用下面的命令创建
redis-cli --cluster create 192.168.241.128:7000 192.168.241.128:7001 192.168.241.128:7002 192.168.241.128:8000 192.168.241.128:8001 192.168.241.128:8002 --cluster-replicas 1
这里报错了,,报错的原因是
Could not connect to Redis at 192.168.241.128:7000: Connection refused
于是我使用 127.0.0.1 来创建。
解决办法是(已验证)
(1)打开对应 redis.conf,将 bind 127.0.0.1 注释掉
(2)将 protected-mode yes 改为 protected-mode no
(3)重启 Redis 服务,即可使用 IP 访问 Redis
执行创建命令后,脚本会给出创建集群的计划,如下所示;计划包括哪些是主节点,哪些是从节点,以及如何分配槽。
[root@luoma src]# redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:8000 127.0.0.1:8001 127.0.0.1:8002 --cluster-replicas 1>>> Performing hash slots allocation on 6 nodes...Master[0] -> Slots 0 - 5460Master[1] -> Slots 5461 - 10922Master[2] -> Slots 10923 - 16383Adding replica 127.0.0.1:8001 to 127.0.0.1:7000Adding replica 127.0.0.1:8002 to 127.0.0.1:7001Adding replica 127.0.0.1:8000 to 127.0.0.1:7002>>> Trying to optimize slaves allocation for anti-affinity[WARNING] Some slaves are in the same host as their masterM: b34e35bac050019eb5c67c964352f897633894b8 127.0.0.1:7000slots:[0-5460] (5461 slots) masterM: 46fdd1a4c063f65e3dc2b151d5f95ca4b18e7f37 127.0.0.1:7001slots:[5461-10922] (5462 slots) masterM: 1fe1b88aa13fb98fe51a1dd839d57c35cf4156ae 127.0.0.1:7002slots:[10923-16383] (5461 slots) masterS: 57972d9fb6cb83f45a475384264b3bb41f14d661 127.0.0.1:8000replicates 46fdd1a4c063f65e3dc2b151d5f95ca4b18e7f37S: a0c1d70393c6f983c710e612859fbf92d1f83c73 127.0.0.1:8001replicates 1fe1b88aa13fb98fe51a1dd839d57c35cf4156aeS: b35a79a77029012a5224613f4bafc02cf7c61a58 127.0.0.1:8002replicates b34e35bac050019eb5c67c964352f897633894b8Can I set the above configuration? (type 'yes' to accept): yes
输入 yes 确认执行计划,脚本便开始按照计划执行,如下所示。
>>> Nodes configuration updated>>> Assign a different config epoch to each node>>> Sending CLUSTER MEET messages to join the clusterWaiting for the cluster to join....>>> Performing Cluster Check (using node 127.0.0.1:7000)M: b34e35bac050019eb5c67c964352f897633894b8 127.0.0.1:7000slots:[0-5460] (5461 slots) master1 additional replica(s)M: 46fdd1a4c063f65e3dc2b151d5f95ca4b18e7f37 127.0.0.1:7001slots:[5461-10922] (5462 slots) master1 additional replica(s)S: 57972d9fb6cb83f45a475384264b3bb41f14d661 127.0.0.1:8000slots: (0 slots) slavereplicates 46fdd1a4c063f65e3dc2b151d5f95ca4b18e7f37M: 1fe1b88aa13fb98fe51a1dd839d57c35cf4156ae 127.0.0.1:7002slots:[10923-16383] (5461 slots) master1 additional replica(s)S: a0c1d70393c6f983c710e612859fbf92d1f83c73 127.0.0.1:8001slots: (0 slots) slavereplicates 1fe1b88aa13fb98fe51a1dd839d57c35cf4156aeS: b35a79a77029012a5224613f4bafc02cf7c61a58 127.0.0.1:8002slots: (0 slots) slavereplicates b34e35bac050019eb5c67c964352f897633894b8[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.
至此,集群搭建完毕。